 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Behavioral Safety Evaluation Fails: A Representation-Level Perspective
Jun 06, 2026Large Language Model (LLM) safety has often been evaluated at the behavior level, which provides limited evidence of internal robustness, as these evaluations target outputs rather than representation-level vulnerability under intervention. We formalize this discrepancy as the audit gap: the difference between behavioral safety and robustness under intervention. To study this gap, we construct dissociated models that preserve safe outward behavior while remaining vulnerable in the latent space. We introduce an intervention-based evaluation framework to test model robustness through soft interventions in parameter and latent spaces, including harmful fine-tuning and layer-wise latent perturbations. To formalize the evaluation, we propose the Latent Vulnerability Score (LVS) to measure how easily harmful behavior can be elicited by bounded latent perturbations. Using this evaluation framework, we show that behavioral safety metrics are insufficient measures of representation-level robustness across multiple safely and unsafely aligned state-of-the-art models. Notably, dissociated models show substantially elevated LVSs despite comparable refusal behavior under harmful intervention, with intermediate representations being the most sensitive to intervention. Our results suggest that behavioral safety evaluation alone provides an incomplete picture of model robustness, motivating representation-aware audits of latent vulnerability and observable behavior.
Environment-Adaptive Preference Optimization for Wildfire Prediction
May 12, 2026Predicting rare extreme events such as wildfires from meteorological data requires models that remain reliable under evolving environmental conditions. This problem is inherently long-tailed: wildfire events are rare but high-impact, while most observations correspond to non-fire conditions, causing standard learning objectives to underemphasize the minority class (fire) that matters most. In addition, models trained on historical distributions often fail under distribution shifts, exhibiting degraded performance in new environments. To this end, we propose Environment-Adaptive Preference Optimization (EAPO), a framework that adapts prediction to the target environment with long-tail distribution. Given a new input distribution, we first construct distribution-aligned datasets via $k$-nearest neighbor retrieval. We then perform a hybrid fine-tuning procedure on this local manifold, combining supervised learning with preference optimization, as well as emphasizing on rare extreme events. EAPO refines decision boundaries while avoiding conflicting signals from heterogeneous training data. We evaluate EAPO on a real-world wildfire prediction task with environmental shifts. EAPO achieves robust performance (ROC-AUC 0.7310) and improves detection in extreme regimes, demonstrating its effectiveness in dynamic wildfire prediction systems.
Latent Adversarial Regularization for Offline Preference Optimization
Jan 29, 2026Learning from human feedback typically relies on preference optimization that constrains policy updates through token-level regularization. However, preference optimization for language models is particularly challenging because token-space similarity does not imply semantic or behavioral similarity. To address this challenge, we leverage latent-space regularization for language model preference optimization. We introduce GANPO, which achieves latent-space regularization by penalizing divergence between the internal representations of a policy model and a reference model. Given that latent representations are not associated with explicit probability densities, we adopt an adversarial approach inspired by GANs to minimize latent-space divergence. We integrate GANPO as a regularizer into existing offline preference optimization objectives. Experiments across multiple model architectures and tasks show consistent improvements from latent-space regularization. Further, by comparing GANPO-induced inferential biases with those from token-level regularization, we find that GANPO provides more robust structural feedback under distributional shift and noise while maintaining comparable downstream performance with minor computational overhead.
Misaligning Reasoning with Answers -- A Framework for Assessing LLM CoT Robustness
May 23, 2025


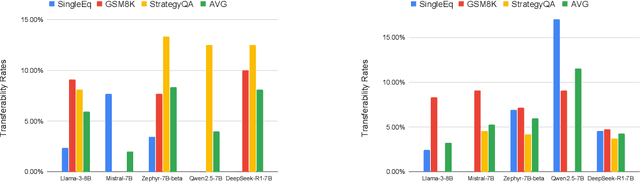
LLMs' decision-making process is opaque, prompting the need for explanation techniques like Chain-of-Thought. To investigate the relationship between answer and reasoning, we design a novel evaluation framework, MATCHA. In domains like education and healthcare, reasoning is key for model trustworthiness. MATCHA reveals that LLMs under input perturbations can give inconsistent or nonsensical reasoning. Additionally, we use LLM judges to assess reasoning robustness across models. Our results show that LLMs exhibit greater vulnerability to input perturbations for multi-step and commonsense tasks than compared to logical tasks. Also, we show non-trivial transfer rates of our successful examples to black-box models. Our evaluation framework helps to better understand LLM reasoning mechanisms and guides future models toward more robust and reasoning-driven architectures, enforcing answer-reasoning consistency.
Towards Universal Certified Robustness with Multi-Norm Training
Oct 03, 2024
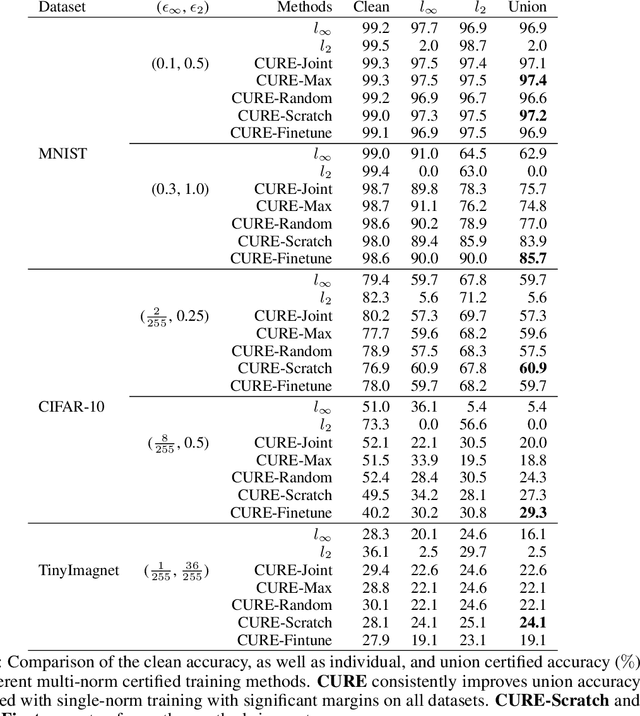


Existing certified training methods can only train models to be robust against a certain perturbation type (e.g. $l_\infty$ or $l_2$). However, an $l_\infty$ certifiably robust model may not be certifiably robust against $l_2$ perturbation (and vice versa) and also has low robustness against other perturbations (e.g. geometric transformation). To this end, we propose the first multi-norm certified training framework \textbf{CURE}, consisting of a new $l_2$ deterministic certified training defense and several multi-norm certified training methods, to attain better \emph{union robustness} when training from scratch or fine-tuning a pre-trained certified model. Further, we devise bound alignment and connect natural training with certified training for better union robustness. Compared with SOTA certified training, \textbf{CURE} improves union robustness up to $22.8\%$ on MNIST, $23.9\%$ on CIFAR-10, and $8.0\%$ on TinyImagenet. Further, it leads to better generalization on a diverse set of challenging unseen geometric perturbations, up to $6.8\%$ on CIFAR-10. Overall, our contributions pave a path towards \textit{universal certified robustness}.
RAMP: Boosting Adversarial Robustness Against Multiple $l_p$ Perturbations
Feb 09, 2024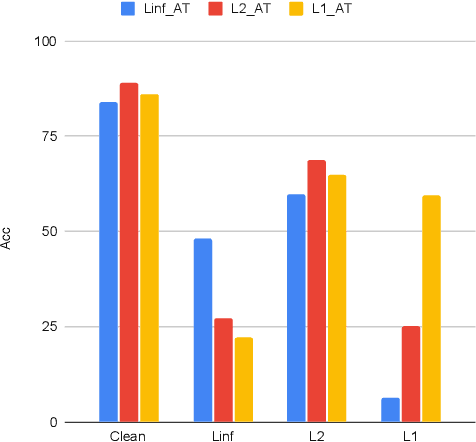

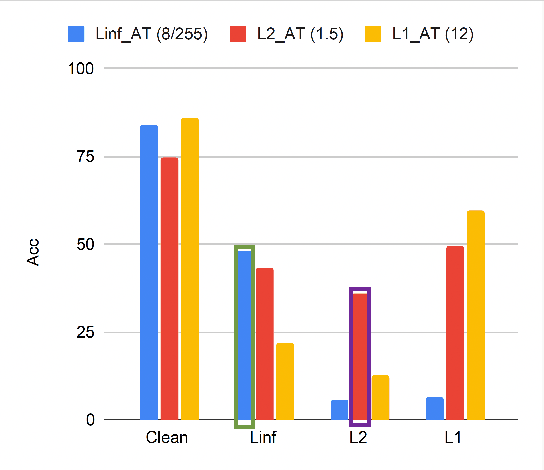
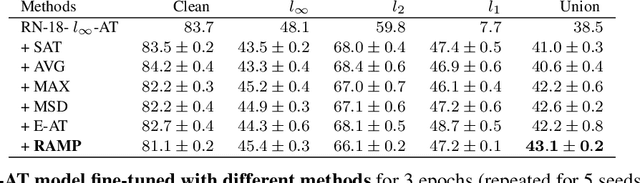
There is considerable work on improving robustness against adversarial attacks bounded by a single $l_p$ norm using adversarial training (AT). However, the multiple-norm robustness (union accuracy) of AT models is still low. We observe that simultaneously obtaining good union and clean accuracy is hard since there are tradeoffs between robustness against multiple $l_p$ perturbations, and accuracy/robustness/efficiency. By analyzing the tradeoffs from the lens of distribution shifts, we identify the key tradeoff pair among $l_p$ attacks to boost efficiency and design a logit pairing loss to improve the union accuracy. Next, we connect natural training with AT via gradient projection, to find and incorporate useful information from natural training into AT, which moderates the accuracy/robustness tradeoff. Combining our contributions, we propose a framework called \textbf{RAMP}, to boost the robustness against multiple $l_p$ perturbations. We show \textbf{RAMP} can be easily adapted for both robust fine-tuning and full AT. For robust fine-tuning, \textbf{RAMP} obtains a union accuracy up to $53.5\%$ on CIFAR-10, and $29.7\%$ on ImageNet. For training from scratch, \textbf{RAMP} achieves SOTA union accuracy of $44.6\%$ and relatively good clean accuracy of $81.2\%$ on ResNet-18 against AutoAttack on CIFAR-10.
Federated Domain Adaptation via Gradient Projection
Feb 21, 2023Federated Domain Adaptation (FDA) describes the federated learning setting where a set of source clients work collaboratively to improve the performance of a target client and where the target client has limited labeled data. The domain shift between the source and target domains, combined with limited samples in the target domain, makes FDA a challenging problem, e.g., common techniques such as FedAvg and fine-tuning fail with a large domain shift. To fill this gap, we propose Federated Gradient Projection ($\texttt{FedGP}$), a novel aggregation rule for FDA, used to aggregate the source gradients and target gradient during training. Further, we introduce metrics that characterize the FDA setting and propose a theoretical framework for analyzing the performance of aggregation rules, which may be of independent interest. Using this framework, we theoretically characterize how, when, and why $\texttt{FedGP}$ works compared to baselines. Our theory suggests certain practical rules that are predictive of practice. Experiments on synthetic and real-world datasets verify the theoretical insights and illustrate the effectiveness of the proposed method in practice.