 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMP: Boosting Adversarial Robustness Against Multiple $l_p$ Perturbations
Paper and Code
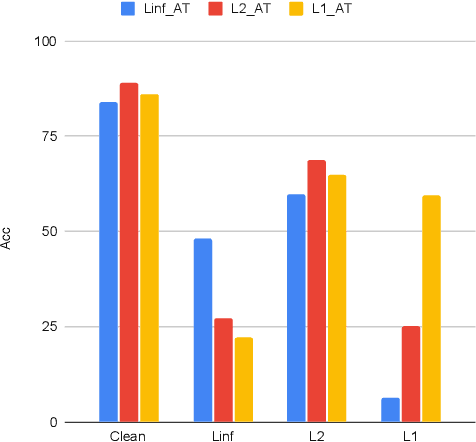

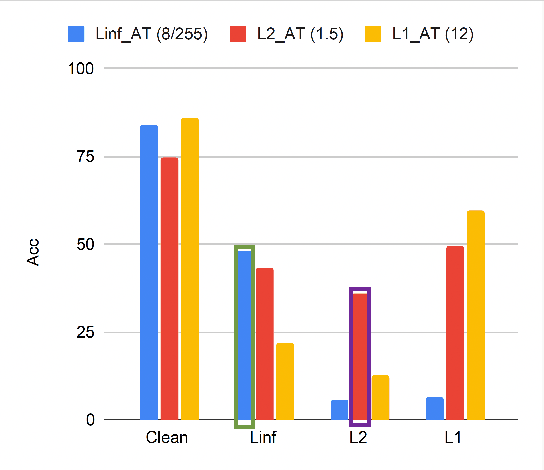
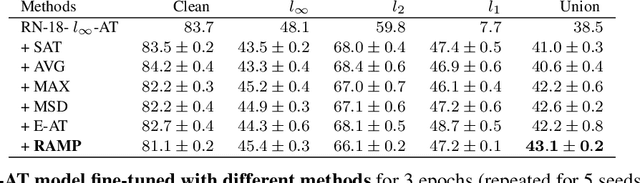
There is considerable work on improving robustness against adversarial attacks bounded by a single $l_p$ norm using adversarial training (AT). However, the multiple-norm robustness (union accuracy) of AT models is still low. We observe that simultaneously obtaining good union and clean accuracy is hard since there are tradeoffs between robustness against multiple $l_p$ perturbations, and accuracy/robustness/efficiency. By analyzing the tradeoffs from the lens of distribution shifts, we identify the key tradeoff pair among $l_p$ attacks to boost efficiency and design a logit pairing loss to improve the union accuracy. Next, we connect natural training with AT via gradient projection, to find and incorporate useful information from natural training into AT, which moderates the accuracy/robustness tradeoff. Combining our contributions, we propose a framework called \textbf{RAMP}, to boost the robustness against multiple $l_p$ perturbations. We show \textbf{RAMP} can be easily adapted for both robust fine-tuning and full AT. For robust fine-tuning, \textbf{RAMP} obtains a union accuracy up to $53.5\%$ on CIFAR-10, and $29.7\%$ on ImageNet. For training from scratch, \textbf{RAMP} achieves SOTA union accuracy of $44.6\%$ and relatively good clean accuracy of $81.2\%$ on ResNet-18 against AutoAttack on CIFAR-10.