 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Adversarial Regularization for Offline Preference Optimization
Jan 29, 2026Learning from human feedback typically relies on preference optimization that constrains policy updates through token-level regularization. However, preference optimization for language models is particularly challenging because token-space similarity does not imply semantic or behavioral similarity. To address this challenge, we leverage latent-space regularization for language model preference optimization. We introduce GANPO, which achieves latent-space regularization by penalizing divergence between the internal representations of a policy model and a reference model. Given that latent representations are not associated with explicit probability densities, we adopt an adversarial approach inspired by GANs to minimize latent-space divergence. We integrate GANPO as a regularizer into existing offline preference optimization objectives. Experiments across multiple model architectures and tasks show consistent improvements from latent-space regularization. Further, by comparing GANPO-induced inferential biases with those from token-level regularization, we find that GANPO provides more robust structural feedback under distributional shift and noise while maintaining comparable downstream performance with minor computational overhead.
A Framework for Objective-Driven Dynamical Stochastic Fields
Apr 18, 2025
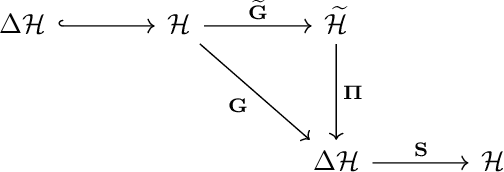
Fields offer a versatile approach for describing complex systems composed of interacting and dynamic components. In particular, some of these dynamical and stochastic systems may exhibit goal-directed behaviors aimed at achieving specific objectives, which we refer to as $\textit{intelligent fields}$. However, due to their inherent complexity, it remains challenging to develop a formal theoretical description of such systems and to effectively translate these descriptions into practical applications. In this paper, we propose three fundamental principles -- complete configuration, locality, and purposefulness -- to establish a theoretical framework for understanding intelligent fields. Moreover, we explore methodologies for designing such fields from the perspective of artificial intelligence applications. This initial investigation aims to lay the groundwork for future theoretical developments and practical advances in understanding and harnessing the potential of such objective-driven dynamical stochastic fields.
Aligning Compound AI Systems via System-level DPO
Feb 24, 2025
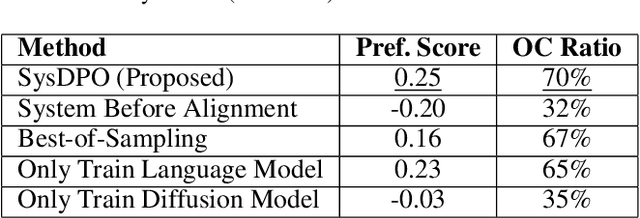

Compound AI systems, comprising multiple interacting components such as LLM agents and external tools, demonstrate state-of-the-art results across diverse tasks. It is hence crucial to align components within the system to produce consistent results that match human expectations. However, conventional alignment methods, such as Direct Preference Optimization (DPO), are not directly applicable to compound AI systems. These challenges include the non-differentiable interactions between components, making end-to-end gradient optimization infeasible. Additionally, system-level preferences cannot be directly translated into component-level preferences, further complicating alignment. We address the issues by formulating compound AI systems as Directed Acyclic Graphs (DAGs), capturing the connections between agents and the data generation processes. We propose a system-level DPO (SysDPO) to jointly align compound systems by adapting the DPO to operate on these DAGs. We study the joint alignment of an LLM and a diffusion model to demonstrate the effectiveness of our approach. Our exploration provides insights into the alignment of compound AI systems and lays a foundation for future advancements.
Can Public Large Language Models Help Private Cross-device Federated Learning?
May 20, 2023



We study (differentially) private federated learning (FL) of language models. The language models in cross-device FL are relatively small, which can be trained with meaningful formal user-level differential privacy (DP) guarantees when massive parallelism in training is enabled by the participation of a moderate size of users. Recently, public data has been used to improve privacy-utility trade-offs for both large and small language models. In this work, we provide a systematic study of using large-scale public data and LLMs to help differentially private training of on-device FL models, and further improve the privacy-utility tradeoff by techniques of distillation. Moreover, we propose a novel distribution matching algorithm with theoretical grounding to sample public data close to private data distribution, which significantly improves the sample efficiency of (pre-)training on public data. The proposed method is efficient and effective for training private model by taking advantage of public data, especially for customized on-device architectures that do not have ready-to-use pre-trained models.
Federated Domain Adaptation via Gradient Projection
Feb 21, 2023Federated Domain Adaptation (FDA) describes the federated learning setting where a set of source clients work collaboratively to improve the performance of a target client and where the target client has limited labeled data. The domain shift between the source and target domains, combined with limited samples in the target domain, makes FDA a challenging problem, e.g., common techniques such as FedAvg and fine-tuning fail with a large domain shift. To fill this gap, we propose Federated Gradient Projection ($\texttt{FedGP}$), a novel aggregation rule for FDA, used to aggregate the source gradients and target gradient during training. Further, we introduce metrics that characterize the FDA setting and propose a theoretical framework for analyzing the performance of aggregation rules, which may be of independent interest. Using this framework, we theoretically characterize how, when, and why $\texttt{FedGP}$ works compared to baselines. Our theory suggests certain practical rules that are predictive of practice. Experiments on synthetic and real-world datasets verify the theoretical insights and illustrate the effectiveness of the proposed method in practice.