 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoodness-of-Fit of Attributed Probabilistic Graph Generative Models
Jul 28, 2023



Probabilistic generative models of graphs are important tools that enable representation and sampling. Many recent works have created probabilistic models of graphs that are capable of representing not only entity interactions but also their attributes. However, given a generative model of random attributed graph(s), the general conditions that establish goodness of fit are not clear a-priori. In this paper, we define goodness of fit in terms of the mean square contingency coefficient for random binary networks. For this statistic, we outline a procedure for assessing the quality of the structure of a learned attributed graph by ensuring that the discrepancy of the mean square contingency coefficient (constant, or random) is minimal with high probability. We apply these criteria to verify the representation capability of a probabilistic generative model for various popular types of graph models.
Layer-Wise Feedback Alignment is Conserved in Deep Neural Networks
Jun 02, 2023



In the quest to enhance the efficiency and bio-plausibility of training deep neural networks, Feedback Alignment (FA), which replaces the backward pass weights with random matrices in the training process, has emerged as an alternative to traditional backpropagation. While the appeal of FA lies in its circumvention of computational challenges and its plausible biological alignment, the theoretical understanding of this learning rule remains partial. This paper uncovers a set of conservation laws underpinning the learning dynamics of FA, revealing intriguing parallels between FA and Gradient Descent (GD). Our analysis reveals that FA harbors implicit biases akin to those exhibited by GD, challenging the prevailing narrative that these learning algorithms are fundamentally different. Moreover, we demonstrate that these conservation laws elucidate sufficient conditions for layer-wise alignment with feedback matrices in ReLU networks. We further show that this implies over-parameterized two-layer linear networks trained with FA converge to minimum-norm solutions. The implications of our findings offer avenues for developing more efficient and biologically plausible alternatives to backpropagation through an understanding of the principles governing learning dynamics in deep networks.
No Bidding, No Regret: Pairwise-Feedback Mechanisms for Digital Goods and Data Auctions
Jun 02, 2023The growing demand for data and AI-generated digital goods, such as personalized written content and artwork, necessitates effective pricing and feedback mechanisms that account for uncertain utility and costly production. Motivated by these developments, this study presents a novel mechanism design addressing a general repeated-auction setting where the utility derived from a sold good is revealed post-sale. The mechanism's novelty lies in using pairwise comparisons for eliciting information from the bidder, arguably easier for humans than assigning a numerical value. Our mechanism chooses allocations using an epsilon-greedy strategy and relies on pairwise comparisons between realized utility from allocated goods and an arbitrary value, avoiding the learning-to-bid problem explored in previous work. We prove this mechanism to be asymptotically truthful, individually rational, and welfare and revenue maximizing. The mechanism's relevance is broad, applying to any setting with made-to-order goods of variable quality. Experimental results on multi-label toxicity annotation data, an example of negative utilities, highlight how our proposed mechanism could enhance social welfare in data auctions. Overall, our focus on human factors contributes to the development of more human-aware and efficient mechanism design.
Double Descent Demystified: Identifying, Interpreting & Ablating the Sources of a Deep Learning Puzzle
Mar 24, 2023



Double descent is a surprising phenomenon in machine learning, in which as the number of model parameters grows relative to the number of data, test error drops as models grow ever larger into the highly overparameterized (data undersampled) regime. This drop in test error flies against classical learning theory on overfitting and has arguably underpinned the success of large models in machine learning. This non-monotonic behavior of test loss depends on the number of data, the dimensionality of the data and the number of model parameters. Here, we briefly describe double descent, then provide an explanation of why double descent occurs in an informal and approachable manner, requiring only familiarity with linear algebra and introductory probability. We provide visual intuition using polynomial regression, then mathematically analyze double descent with ordinary linear regression and identify three interpretable factors that, when simultaneously all present, together create double descent. We demonstrate that double descent occurs on real data when using ordinary linear regression, then demonstrate that double descent does not occur when any of the three factors are ablated. We use this understanding to shed light on recent observations in nonlinear models concerning superposition and double descent. Code is publicly available.
Federated Domain Adaptation via Gradient Projection
Feb 21, 2023Federated Domain Adaptation (FDA) describes the federated learning setting where a set of source clients work collaboratively to improve the performance of a target client and where the target client has limited labeled data. The domain shift between the source and target domains, combined with limited samples in the target domain, makes FDA a challenging problem, e.g., common techniques such as FedAvg and fine-tuning fail with a large domain shift. To fill this gap, we propose Federated Gradient Projection ($\texttt{FedGP}$), a novel aggregation rule for FDA, used to aggregate the source gradients and target gradient during training. Further, we introduce metrics that characterize the FDA setting and propose a theoretical framework for analyzing the performance of aggregation rules, which may be of independent interest. Using this framework, we theoretically characterize how, when, and why $\texttt{FedGP}$ works compared to baselines. Our theory suggests certain practical rules that are predictive of practice. Experiments on synthetic and real-world datasets verify the theoretical insights and illustrate the effectiveness of the proposed method in practice.
Target Conditioned Representation Independence (TCRI); From Domain-Invariant to Domain-General Representations
Dec 21, 2022



We propose a Target Conditioned Representation Independence (TCRI) objective for domain generalization. TCRI addresses the limitations of existing domain generalization methods due to incomplete constraints. Specifically, TCRI implements regularizers motivated by conditional independence constraints that are sufficient to strictly learn complete sets of invariant mechanisms, which we show are necessary and sufficient for domain generalization. Empirically, we show that TCRI is effective on both synthetic and real-world data. TCRI is competitive with baselines in average accuracy while outperforming them in worst-domain accuracy, indicating desired cross-domain stability.
Metric Elicitation; Moving from Theory to Practice
Dec 07, 2022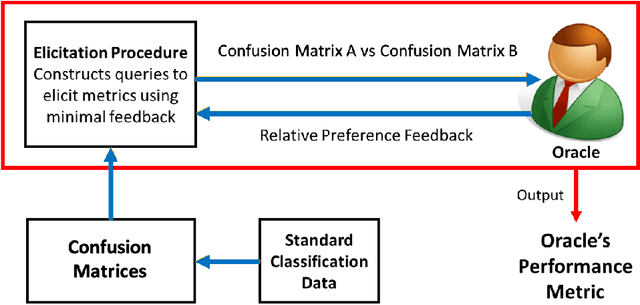
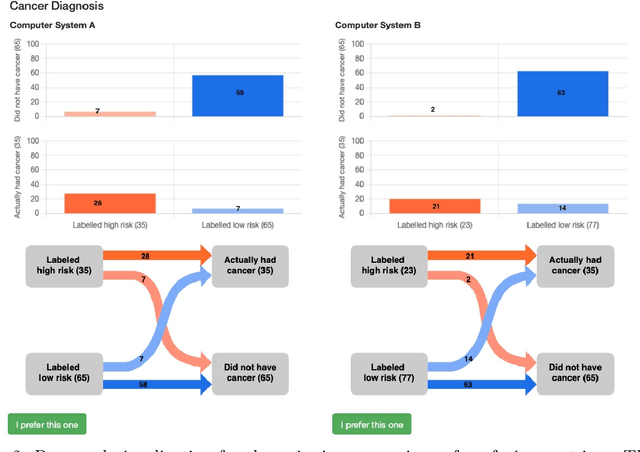
Metric Elicitation (ME) is a framework for eliciting classification metrics that better align with implicit user preferences based on the task and context. The existing ME strategy so far is based on the assumption that users can most easily provide preference feedback over classifier statistics such as confusion matrices. This work examines ME, by providing a first ever implementation of the ME strategy. Specifically, we create a web-based ME interface and conduct a user study that elicits users' preferred metrics in a binary classification setting. We discuss the study findings and present guidelines for future research in this direction.
Batch Active Learning from the Perspective of Sparse Approximation
Nov 05, 2022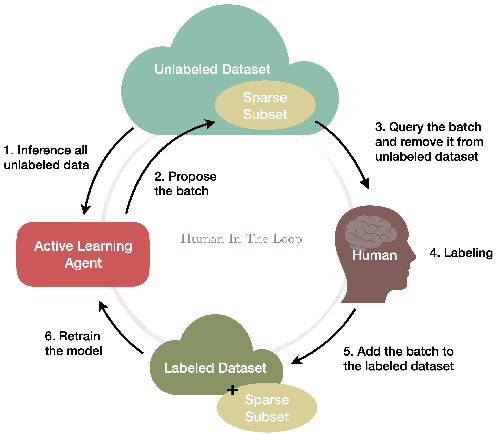

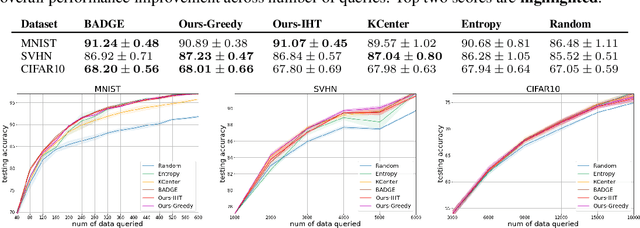

Active learning enables efficient model training by leveraging interactions between machine learning agents and human annotators. We study and propose a novel framework that formulates batch active learning from the sparse approximation's perspective. Our active learning method aims to find an informative subset from the unlabeled data pool such that the corresponding training loss function approximates its full data pool counterpart. We realize the framework as sparsity-constrained discontinuous optimization problems, which explicitly balance uncertainty and representation for large-scale applications and could be solved by greedy or proximal iterative hard thresholding algorithms. The proposed method can adapt to various settings, including both Bayesian and non-Bayesian neural networks. Numerical experiments show that our work achieves competitive performance across different settings with lower computational complexity.
Latent Multimodal Functional Graphical Model Estimation
Oct 31, 2022Joint multimodal functional data acquisition, where functional data from multiple modes are measured simultaneously from the same subject, has emerged as an exciting modern approach enabled by recent engineering breakthroughs in the neurological and biological sciences. One prominent motivation to acquire such data is to enable new discoveries of the underlying connectivity by combining multimodal signals. Despite the scientific interest, there remains a gap in principled statistical methods for estimating the graph underlying multimodal functional data. To this end, we propose a new integrative framework that models the data generation process and identifies operators mapping from the observation space to the latent space. We then develop an estimator that simultaneously estimates the transformation operators and the latent graph. This estimator is based on the partial correlation operator, which we rigorously extend from the multivariate to the functional setting. Our procedure is provably efficient, with the estimator converging to a stationary point with quantifiable statistical error. Furthermore, we show recovery of the latent graph under mild conditions. Our work is applied to analyze simultaneously acquired multimodal brain imaging data where the graph indicates functional connectivity of the brain. We present simulation and empirical results that support the benefits of joint estimation.
Controllable Radiance Fields for Dynamic Face Synthesis
Oct 11, 2022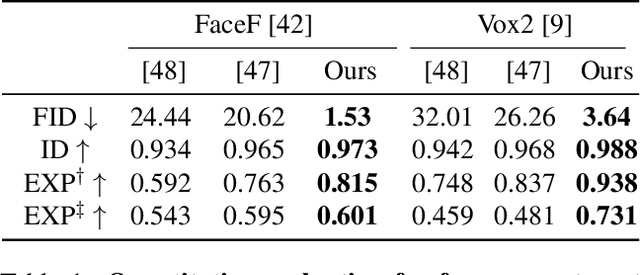
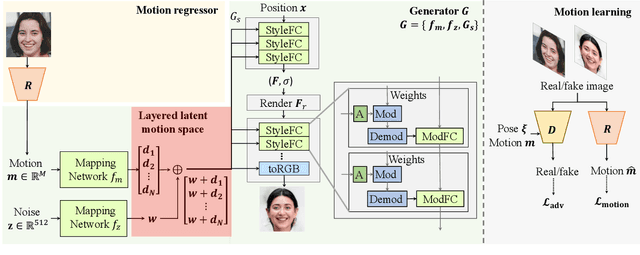
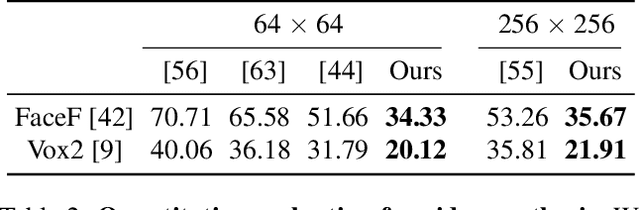
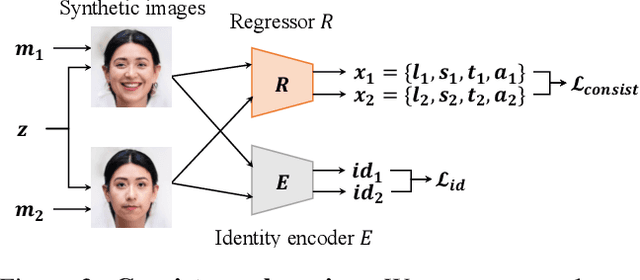
Recent work on 3D-aware image synthesis has achieved compelling results using advances in neural rendering. However, 3D-aware synthesis of face dynamics hasn't received much attention. Here, we study how to explicitly control generative model synthesis of face dynamics exhibiting non-rigid motion (e.g., facial expression change), while simultaneously ensuring 3D-awareness. For this we propose a Controllable Radiance Field (CoRF): 1) Motion control is achieved by embedding motion features within the layered latent motion space of a style-based generator; 2) To ensure consistency of background, motion features and subject-specific attributes such as lighting, texture, shapes, albedo, and identity, a face parsing net, a head regressor and an identity encoder are incorporated. On head image/video data we show that CoRFs are 3D-aware while enabling editing of identity, viewing directions, and motion.