 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Radiance Fields for Dynamic Face Synthesis
Paper and Code
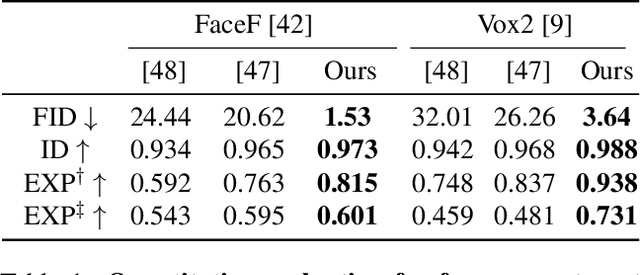
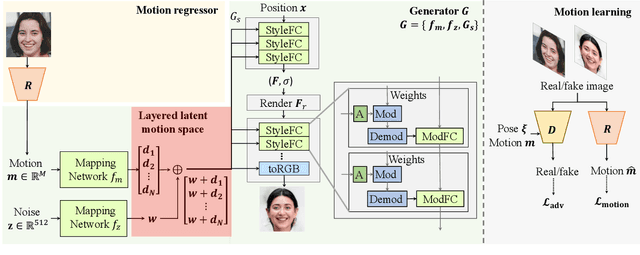
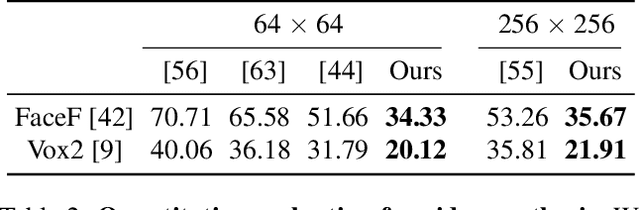
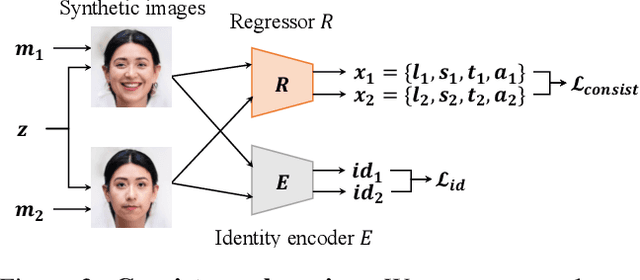
Recent work on 3D-aware image synthesis has achieved compelling results using advances in neural rendering. However, 3D-aware synthesis of face dynamics hasn't received much attention. Here, we study how to explicitly control generative model synthesis of face dynamics exhibiting non-rigid motion (e.g., facial expression change), while simultaneously ensuring 3D-awareness. For this we propose a Controllable Radiance Field (CoRF): 1) Motion control is achieved by embedding motion features within the layered latent motion space of a style-based generator; 2) To ensure consistency of background, motion features and subject-specific attributes such as lighting, texture, shapes, albedo, and identity, a face parsing net, a head regressor and an identity encoder are incorporated. On head image/video data we show that CoRFs are 3D-aware while enabling editing of identity, viewing directions, and motion.