 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Reinforcement Learning with Verifiable Rewards via Randomly Selected Few-Shot Guidance
May 14, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has achieved great success in developing Large Language Models (LLMs) with chain-of-thought rollouts for many tasks such as math and coding. Nevertheless, RLVR struggles with sample efficiency on difficult problems where correct rollouts are hard to generate. Prior works propose to address this issue via demonstration-guided RLVR, i.e., to conduct Supervised FineTuning (SFT) when RL fails; however, SFT often requires a lot of data, which can be expensive to acquire. In this paper, we propose FEST, a FEw-ShoT demonstration-guided RLVR algorithm. It attains compelling results with only 128 demonstrations randomly selected from an SFT dataset. We find that three components are vital for the success: supervised signal, on-policy signal, and decaying weights on the few-shot SFT dataset to prevent overfitting from multiple-epoch training. On several benchmarks, FEST outperforms baselines with magnitudes less SFT data, even matching their performance with full dataset.
Seeing Without Eyes: 4D Human-Scene Understanding from Wearable IMUs
Apr 23, 2026Understanding human activities and their surrounding environments typically relies on visual perception, yet cameras pose persistent challenges in privacy, safety, energy efficiency, and scalability. We explore an alternative: 4D perception without vision. Its goal is to reconstruct human motion and 3D scene layouts purely from everyday wearable sensors. For this we introduce IMU-to-4D, a framework that repurposes large language models for non-visual spatiotemporal understanding of human-scene dynamics. IMU-to-4D uses data from a few inertial sensors from earbuds, watches, or smartphones and predicts detailed 4D human motion together with coarse scene structure. Experiments across diverse human-scene datasets show that IMU-to-4D yields more coherent and temporally stable results than SoTA cascaded pipelines, suggesting wearable motion sensors alone can support rich 4D understanding.
Latent Wasserstein Adversarial Imitation Learning
Mar 05, 2026Imitation Learning (IL) enables agents to mimic expert behavior by learning from demonstrations. However, traditional IL methods require large amounts of medium-to-high-quality demonstrations as well as actions of expert demonstrations, both of which are often unavailable. To reduce this need, we propose Latent Wasserstein Adversarial Imitation Learning (LWAIL), a novel adversarial imitation learning framework that focuses on state-only distribution matching. It benefits from the Wasserstein distance computed in a dynamics-aware latent space. This dynamics-aware latent space differs from prior work and is obtained via a pre-training stage, where we train the Intention Conditioned Value Function (ICVF) to capture a dynamics-aware structure of the state space using a small set of randomly generated state-only data. We show that this enhances the policy's understanding of state transitions, enabling the learning process to use only one or a few state-only expert episodes to achieve expert-level performance. Through experiments on multiple MuJoCo environments, we demonstrate that our method outperforms prior Wasserstein-based IL methods and prior adversarial IL methods, achieving better results across various tasks.
Studying Classifier(-Free) Guidance From a Classifier-Centric Perspective
Mar 13, 2025Classifier-free guidance has become a staple for conditional generation with denoising diffusion models. However, a comprehensive understanding of classifier-free guidance is still missing. In this work, we carry out an empirical study to provide a fresh perspective on classifier-free guidance. Concretely, instead of solely focusing on classifier-free guidance, we trace back to the root, i.e., classifier guidance, pinpoint the key assumption for the derivation, and conduct a systematic study to understand the role of the classifier. We find that both classifier guidance and classifier-free guidance achieve conditional generation by pushing the denoising diffusion trajectories away from decision boundaries, i.e., areas where conditional information is usually entangled and is hard to learn. Based on this classifier-centric understanding, we propose a generic postprocessing step built upon flow-matching to shrink the gap between the learned distribution for a pre-trained denoising diffusion model and the real data distribution, majorly around the decision boundaries. Experiments on various datasets verify the effectiveness of the proposed approach.
Variational Rectified Flow Matching
Feb 13, 2025We study Variational Rectified Flow Matching, a framework that enhances classic rectified flow matching by modeling multi-modal velocity vector-fields. At inference time, classic rectified flow matching 'moves' samples from a source distribution to the target distribution by solving an ordinary differential equation via integration along a velocity vector-field. At training time, the velocity vector-field is learnt by linearly interpolating between coupled samples one drawn from the source and one drawn from the target distribution randomly. This leads to ''ground-truth'' velocity vector-fields that point in different directions at the same location, i.e., the velocity vector-fields are multi-modal/ambiguous. However, since training uses a standard mean-squared-error loss, the learnt velocity vector-field averages ''ground-truth'' directions and isn't multi-modal. In contrast, variational rectified flow matching learns and samples from multi-modal flow directions. We show on synthetic data, MNIST, CIFAR-10, and ImageNet that variational rectified flow matching leads to compelling results.
LIFe-GoM: Generalizable Human Rendering with Learned Iterative Feedback Over Multi-Resolution Gaussians-on-Mesh
Feb 13, 2025
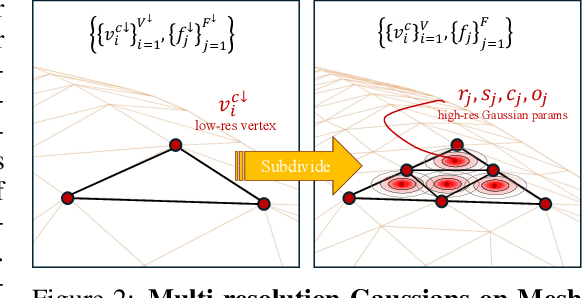


Generalizable rendering of an animatable human avatar from sparse inputs relies on data priors and inductive biases extracted from training on large data to avoid scene-specific optimization and to enable fast reconstruction. This raises two main challenges: First, unlike iterative gradient-based adjustment in scene-specific optimization, generalizable methods must reconstruct the human shape representation in a single pass at inference time. Second, rendering is preferably computationally efficient yet of high resolution. To address both challenges we augment the recently proposed dual shape representation, which combines the benefits of a mesh and Gaussian points, in two ways. To improve reconstruction, we propose an iterative feedback update framework, which successively improves the canonical human shape representation during reconstruction. To achieve computationally efficient yet high-resolution rendering, we study a coupled-multi-resolution Gaussians-on-Mesh representation. We evaluate the proposed approach on the challenging THuman2.0, XHuman and AIST++ data. Our approach reconstructs an animatable representation from sparse inputs in less than 1s, renders views with 95.1FPS at $1024 \times 1024$, and achieves PSNR/LPIPS*/FID of 24.65/110.82/51.27 on THuman2.0, outperforming the state-of-the-art in rendering quality.
Reinforcement Learning Gradients as Vitamin for Online Finetuning Decision Transformers
Oct 31, 2024



Decision Transformers have recently emerged as a new and compelling paradigm for offline Reinforcement Learning (RL), completing a trajectory in an autoregressive way. While improvements have been made to overcome initial shortcomings, online finetuning of decision transformers has been surprisingly under-explored. The widely adopted state-of-the-art Online Decision Transformer (ODT) still struggles when pretrained with low-reward offline data. In this paper, we theoretically analyze the online-finetuning of the decision transformer, showing that the commonly used Return-To-Go (RTG) that's far from the expected return hampers the online fine-tuning process. This problem, however, is well-addressed by the value function and advantage of standard RL algorithms. As suggested by our analysis, in our experiments, we hence find that simply adding TD3 gradients to the finetuning process of ODT effectively improves the online finetuning performance of ODT, especially if ODT is pretrained with low-reward offline data. These findings provide new directions to further improve decision transformers.
GoMAvatar: Efficient Animatable Human Modeling from Monocular Video Using Gaussians-on-Mesh
Apr 11, 2024We introduce GoMAvatar, a novel approach for real-time, memory-efficient, high-quality animatable human modeling. GoMAvatar takes as input a single monocular video to create a digital avatar capable of re-articulation in new poses and real-time rendering from novel viewpoints, while seamlessly integrating with rasterization-based graphics pipelines. Central to our method is the Gaussians-on-Mesh representation, a hybrid 3D model combining rendering quality and speed of Gaussian splatting with geometry modeling and compatibility of deformable meshes. We assess GoMAvatar on ZJU-MoCap data and various YouTube videos. GoMAvatar matches or surpasses current monocular human modeling algorithms in rendering quality and significantly outperforms them in computational efficiency (43 FPS) while being memory-efficient (3.63 MB per subject).
OW-VISCap: Open-World Video Instance Segmentation and Captioning
Apr 04, 2024
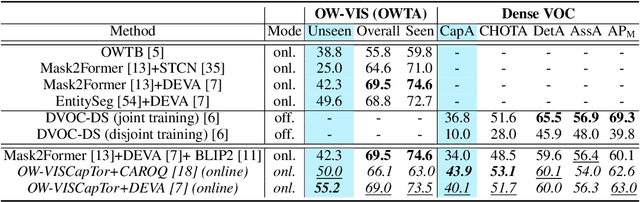
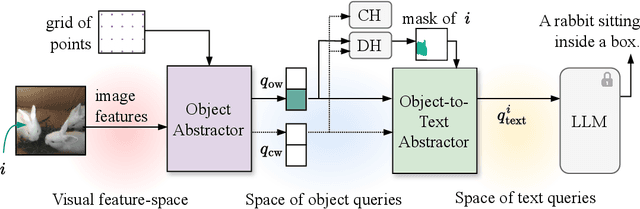

Open-world video instance segmentation is an important video understanding task. Yet most methods either operate in a closed-world setting, require an additional user-input, or use classic region-based proposals to identify never before seen objects. Further, these methods only assign a one-word label to detected objects, and don't generate rich object-centric descriptions. They also often suffer from highly overlapping predictions. To address these issues, we propose Open-World Video Instance Segmentation and Captioning (OW-VISCap), an approach to jointly segment, track, and caption previously seen or unseen objects in a video. For this, we introduce open-world object queries to discover never before seen objects without additional user-input. We generate rich and descriptive object-centric captions for each detected object via a masked attention augmented LLM input. We introduce an inter-query contrastive loss to ensure that the object queries differ from one another. Our generalized approach matches or surpasses state-of-the-art on three tasks: open-world video instance segmentation on the BURST dataset, dense video object captioning on the VidSTG dataset, and closed-world video instance segmentation on the OVIS dataset.
StableDreamer: Taming Noisy Score Distillation Sampling for Text-to-3D
Dec 02, 2023



In the realm of text-to-3D generation, utilizing 2D diffusion models through score distillation sampling (SDS) frequently leads to issues such as blurred appearances and multi-faced geometry, primarily due to the intrinsically noisy nature of the SDS loss. Our analysis identifies the core of these challenges as the interaction among noise levels in the 2D diffusion process, the architecture of the diffusion network, and the 3D model representation. To overcome these limitations, we present StableDreamer, a methodology incorporating three advances. First, inspired by InstructNeRF2NeRF, we formalize the equivalence of the SDS generative prior and a simple supervised L2 reconstruction loss. This finding provides a novel tool to debug SDS, which we use to show the impact of time-annealing noise levels on reducing multi-faced geometries. Second, our analysis shows that while image-space diffusion contributes to geometric precision, latent-space diffusion is crucial for vivid color rendition. Based on this observation, StableDreamer introduces a two-stage training strategy that effectively combines these aspects, resulting in high-fidelity 3D models. Third, we adopt an anisotropic 3D Gaussians representation, replacing Neural Radiance Fields (NeRFs), to enhance the overall quality, reduce memory usage during training, and accelerate rendering speeds, and better capture semi-transparent objects. StableDreamer reduces multi-face geometries, generates fine details, and converges stably.