 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOW-VISCap: Open-World Video Instance Segmentation and Captioning
Paper and Code

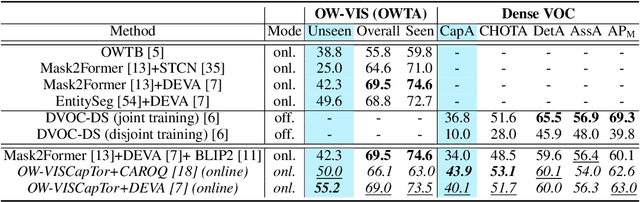
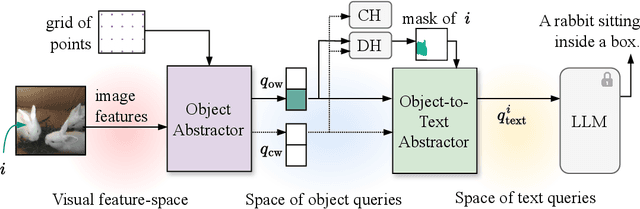

Open-world video instance segmentation is an important video understanding task. Yet most methods either operate in a closed-world setting, require an additional user-input, or use classic region-based proposals to identify never before seen objects. Further, these methods only assign a one-word label to detected objects, and don't generate rich object-centric descriptions. They also often suffer from highly overlapping predictions. To address these issues, we propose Open-World Video Instance Segmentation and Captioning (OW-VISCap), an approach to jointly segment, track, and caption previously seen or unseen objects in a video. For this, we introduce open-world object queries to discover never before seen objects without additional user-input. We generate rich and descriptive object-centric captions for each detected object via a masked attention augmented LLM input. We introduce an inter-query contrastive loss to ensure that the object queries differ from one another. Our generalized approach matches or surpasses state-of-the-art on three tasks: open-world video instance segmentation on the BURST dataset, dense video object captioning on the VidSTG dataset, and closed-world video instance segmentation on the OVIS dataset.