 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATNAV: Cached Vision-Language Traversability for Efficient Zero-Shot Robot Navigation
Mar 24, 2026Navigating unstructured environments requires assessing traversal risk relative to a robot's physical capabilities, a challenge that varies across embodiments. We present CATNAV, a cost-aware traversability navigation framework that leverages multimodal LLMs for zero-shot, embodiment-aware costmap generation without task-specific training. We introduce a visuosemantic caching mechanism that detects scene novelty and reuses prior risk assessments for semantically similar frames, reducing online VLM queries by 85.7%. Furthermore, we introduce a VLM-based trajectory selection module that evaluates proposals through visual reasoning to choose the safest path given behavioral constraints. We evaluate CATNAV on a quadruped robot across indoor and outdoor unstructured environments, comparing against state-of-the-art vision-language-action baselines. Across five navigation tasks, CATNAV achieves 10 percentage point higher average goal-reaching rate and 33% fewer behavioral constraint violations.
HyReach: Vision-Guided Hybrid Manipulator Reaching in Unseen Cluttered Environments
Mar 22, 2026As robotic systems increasingly operate in unstructured, cluttered, and previously unseen environments, there is a growing need for manipulators that combine compliance, adaptability, and precise control. This work presents a real-time hybrid rigid-soft continuum manipulator system designed for robust open-world object reaching in such challenging environments. The system integrates vision-based perception and 3D scene reconstruction with shape-aware motion planning to generate safe trajectories. A learning-based controller drives the hybrid arm to arbitrary target poses, leveraging the flexibility of the soft segment while maintaining the precision of the rigid segment. The system operates without environment-specific retraining, enabling direct generalization to new scenes. Extensive real-world experiments demonstrate consistent reaching performance with errors below 2 cm across diverse cluttered setups, highlighting the potential of hybrid manipulators for adaptive and reliable operation in unstructured environments.
S2Act: Simple Spiking Actor
Mar 16, 2026Spiking neural networks (SNNs) and biologically-inspired learning mechanisms are attractive in mobile robotics, where the size and performance of onboard neural network policies are constrained by power and computational budgets. Existing SNN approaches, such as population coding, reward modulation, and hybrid artificial neural network (ANN)-SNN architectures, have shown promising results; however, they face challenges in complex, highly stochastic environments due to SNN sensitivity to hyperparameters and inconsistent gradient signals. To address these challenges, we propose simple spiking actor (S2Act), a computationally lightweight framework that deploys an RL policy using an SNN in three steps: (1) architect an actor-critic model based on an approximated network of rate-based spiking neurons, (2) train the network with gradients using compatible activation functions, and (3) transfer the trained weights into physical parameters of rate-based leaky integrate-and-fire (LIF) neurons for inference and deployment. By globally shaping LIF neuron parameters such that their rate-based responses approximate ReLU activations, S2Act effectively mitigates the vanishing gradient problem, while pre-constraining LIF response curves reduces reliance on complex SNN-specific hyperparameter tuning. We demonstrate our method in two multi-agent stochastic environments (capture-the-flag and parking) that capture the complexity of multi-robot interactions, and deploy our trained policies on physical TurtleBot platforms using Intel's Loihi neuromorphic hardware. Our experimental results show that S2Act outperforms relevant baselines in task performance and real-time inference in nearly all considered scenarios, highlighting its potential for rapid prototyping and efficient real-world deployment of SNN-based RL policies.
Visual-Language-Guided Task Planning for Horticultural Robots
Jan 17, 2026Crop monitoring is essential for precision agriculture, but current systems lack high-level reasoning. We introduce a novel, modular framework that uses a Visual Language Model (VLM) to guide robotic task planning, interleaving input queries with action primitives. We contribute a comprehensive benchmark for short- and long-horizon crop monitoring tasks in monoculture and polyculture environments. Our main results show that VLMs perform robustly for short-horizon tasks (comparable to human success), but exhibit significant performance degradation in challenging long-horizon tasks. Critically, the system fails when relying on noisy semantic maps, demonstrating a key limitation in current VLM context grounding for sustained robotic operations. This work offers a deployable framework and critical insights into VLM capabilities and shortcomings for complex agricultural robotics.
Active Semantic Mapping of Horticultural Environments Using Gaussian Splatting
Jan 17, 2026Semantic reconstruction of agricultural scenes plays a vital role in tasks such as phenotyping and yield estimation. However, traditional approaches that rely on manual scanning or fixed camera setups remain a major bottleneck in this process. In this work, we propose an active 3D reconstruction framework for horticultural environments using a mobile manipulator. The proposed system integrates the classical Octomap representation with 3D Gaussian Splatting to enable accurate and efficient target-aware mapping. While a low-resolution Octomap provides probabilistic occupancy information for informative viewpoint selection and collision-free planning, 3D Gaussian Splatting leverages geometric, photometric, and semantic information to optimize a set of 3D Gaussians for high-fidelity scene reconstruction. We further introduce simple yet effective strategies to enhance robustness against segmentation noise and reduce memory consumption. Simulation experiments demonstrate that our method outperforms purely occupancy-based approaches in both runtime efficiency and reconstruction accuracy, enabling precise fruit counting and volume estimation. Compared to a 0.01m-resolution Octomap, our approach achieves an improvement of 6.6% in fruit-level F1 score under noise-free conditions, and up to 28.6% under segmentation noise. Additionally, it achieves a 50% reduction in runtime, highlighting its potential for scalable, real-time semantic reconstruction in agricultural robotics.
ZeST: an LLM-based Zero-Shot Traversability Navigation for Unknown Environments
Aug 26, 2025The advancement of robotics and autonomous navigation systems hinges on the ability to accurately predict terrain traversability. Traditional methods for generating datasets to train these prediction models often involve putting robots into potentially hazardous environments, posing risks to equipment and safety. To solve this problem, we present ZeST, a novel approach leveraging visual reasoning capabilities of Large Language Models (LLMs) to create a traversability map in real-time without exposing robots to danger. Our approach not only performs zero-shot traversability and mitigates the risks associated with real-world data collection but also accelerates the development of advanced navigation systems, offering a cost-effective and scalable solution. To support our findings, we present navigation results, in both controlled indoor and unstructured outdoor environments. As shown in the experiments, our method provides safer navigation when compared to other state-of-the-art methods, constantly reaching the final goal.
Towards Efficient Large Scale Spatial-Temporal Time Series Forecasting via Improved Inverted Transformers
Mar 13, 2025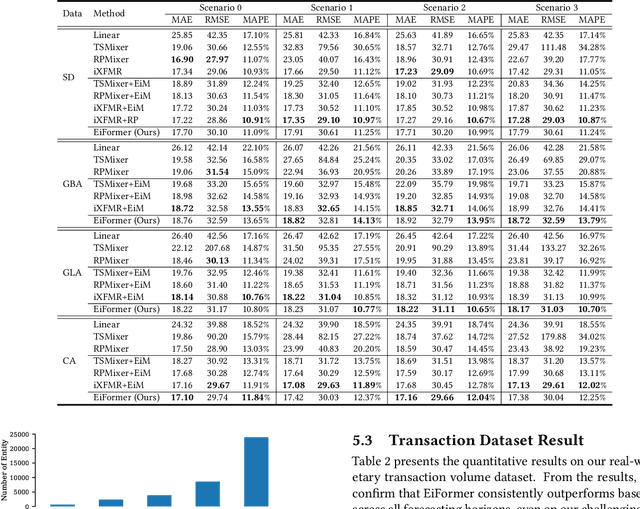
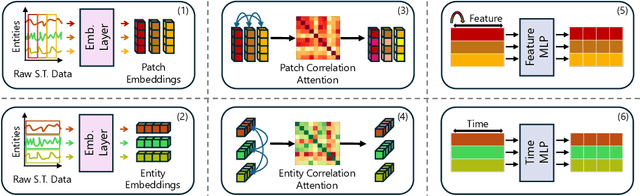
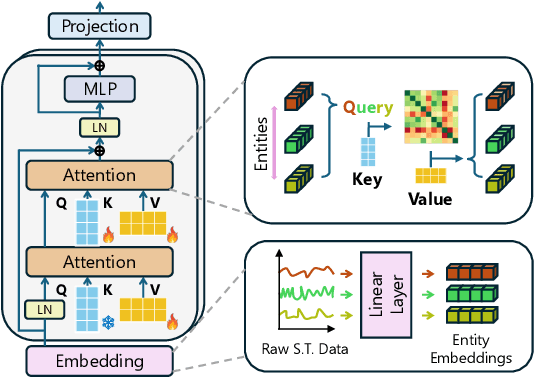
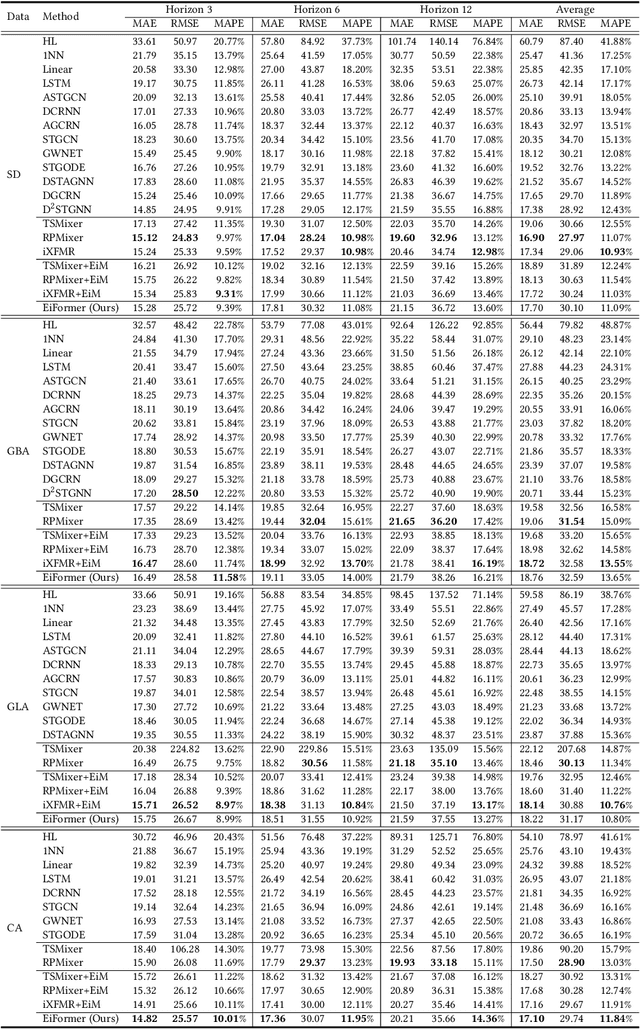
Time series forecasting at scale presents significant challenges for modern prediction systems, particularly when dealing with large sets of synchronized series, such as in a global payment network. In such systems, three key challenges must be overcome for accurate and scalable predictions: 1) emergence of new entities, 2) disappearance of existing entities, and 3) the large number of entities present in the data. The recently proposed Inverted Transformer (iTransformer) architecture has shown promising results by effectively handling variable entities. However, its practical application in large-scale settings is limited by quadratic time and space complexity ($O(N^2)$) with respect to the number of entities $N$. In this paper, we introduce EiFormer, an improved inverted transformer architecture that maintains the adaptive capabilities of iTransformer while reducing computational complexity to linear scale ($O(N)$). Our key innovation lies in restructuring the attention mechanism to eliminate redundant computations without sacrificing model expressiveness. Additionally, we incorporate a random projection mechanism that not only enhances efficiency but also improves prediction accuracy through better feature representation. Extensive experiments on the public LargeST benchmark dataset and a proprietary large-scale time series dataset demonstrate that EiFormer significantly outperforms existing methods in both computational efficiency and forecasting accuracy. Our approach enables practical deployment of transformer-based forecasting in industrial applications where handling time series at scale is essential.
BYON: Bring Your Own Networks for Digital Agriculture Applications
Feb 03, 2025Digital agriculture technologies rely on sensors, drones, robots, and autonomous farm equipment to improve farm yields and incorporate sustainability practices. However, the adoption of such technologies is severely limited by the lack of broadband connectivity in rural areas. We argue that farming applications do not require permanent always-on connectivity. Instead, farming activity and digital agriculture applications follow seasonal rhythms of agriculture. Therefore, the need for connectivity is highly localized in time and space. We introduce BYON, a new connectivity model for high bandwidth agricultural applications that relies on emerging connectivity solutions like citizens broadband radio service (CBRS) and satellite networks. BYON creates an agile connectivity solution that can be moved along a farm to create spatio-temporal connectivity bubbles. BYON incorporates a new gateway design that reacts to the presence of crops and optimizes coverage in agricultural settings. We evaluate BYON in a production farm and demonstrate its benefits.
Precision Harvesting in Cluttered Environments: Integrating End Effector Design with Dual Camera Perception
Jan 31, 2025



Due to labor shortages in specialty crop industries, a need for robotic automation to increase agricultural efficiency and productivity has arisen. Previous manipulation systems perform well in harvesting in uncluttered and structured environments. High tunnel environments are more compact and cluttered in nature, requiring a rethinking of the large form factor systems and grippers. We propose a novel codesigned framework incorporating a global detection camera and a local eye-in-hand camera that demonstrates precise localization of small fruits via closed-loop visual feedback and reliable error handling. Field experiments in high tunnels show our system can reach an average of 85.0\% of cherry tomato fruit in 10.98s on average.
Active Semantic Mapping with Mobile Manipulator in Horticultural Environments
Dec 13, 2024



Semantic maps are fundamental for robotics tasks such as navigation and manipulation. They also enable yield prediction and phenotyping in agricultural settings. In this paper, we introduce an efficient and scalable approach for active semantic mapping in horticultural environments, employing a mobile robot manipulator equipped with an RGB-D camera. Our method leverages probabilistic semantic maps to detect semantic targets, generate candidate viewpoints, and compute corresponding information gain. We present an efficient ray-casting strategy and a novel information utility function that accounts for both semantics and occlusions. The proposed approach reduces total runtime by 8% compared to previous baselines. Furthermore, our information metric surpasses other metrics in reducing multi-class entropy and improving surface coverage, particularly in the presence of segmentation noise. Real-world experiments validate our method's effectiveness but also reveal challenges such as depth sensor noise and varying environmental conditions, requiring further research.