 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Excavation of Challenging Terrain using Oscillatory Primitives and Adaptive Impedance Control
Sep 26, 2024This paper addresses the challenge of autonomous excavation of challenging terrains, in particular those that are prone to jamming and inter-particle adhesion when tackled by a standard penetrate-drag-scoop motion pattern. Inspired by human excavation strategies, our approach incorporates oscillatory rotation elements -- including swivel, twist, and dive motions -- to break up compacted, tangled grains and reduce jamming. We also present an adaptive impedance control method, the Reactive Attractor Impedance Controller (RAIC), that adapts a motion trajectory to unexpected forces during loading in a manner that tracks a trajectory closely when loads are low, but avoids excessive loads when significant resistance is met. Our method is evaluated on four terrains using a robotic arm, demonstrating improved excavation performance across multiple metrics, including volume scooped, protective stop rate, and trajectory completion percentage.
InfraLib: Enabling Reinforcement Learning and Decision Making for Large Scale Infrastructure Management
Sep 05, 2024Efficient management of infrastructure systems is crucial for economic stability, sustainability, and public safety. However, infrastructure management is challenging due to the vast scale of systems, stochastic deterioration of components, partial observability, and resource constraints. While data-driven approaches like reinforcement learning (RL) offer a promising avenue for optimizing management policies, their application to infrastructure has been limited by the lack of suitable simulation environments. We introduce InfraLib, a comprehensive framework for modeling and analyzing infrastructure management problems. InfraLib employs a hierarchical, stochastic approach to realistically model infrastructure systems and their deterioration. It supports practical functionality such as modeling component unavailability, cyclical budgets, and catastrophic failures. To facilitate research, InfraLib provides tools for expert data collection, simulation-driven analysis, and visualization. We demonstrate InfraLib's capabilities through case studies on a real-world road network and a synthetic benchmark with 100,000 components.
Few-shot Scooping Under Domain Shift via Simulated Maximal Deployment Gaps
Aug 06, 2024



Autonomous lander missions on extraterrestrial bodies need to sample granular materials while coping with domain shifts, even when sampling strategies are extensively tuned on Earth. To tackle this challenge, this paper studies the few-shot scooping problem and proposes a vision-based adaptive scooping strategy that uses the deep kernel Gaussian process method trained with a novel meta-training strategy to learn online from very limited experience on out-of-distribution target terrains. Our Deep Kernel Calibration with Maximal Deployment Gaps (kCMD) strategy explicitly trains a deep kernel model to adapt to large domain shifts by creating simulated maximal deployment gaps from an offline training dataset and training models to overcome these deployment gaps during training. Employed in a Bayesian Optimization sequential decision-making framework, the proposed method allows the robot to perform high-quality scooping actions on out-of-distribution terrains after a few attempts, significantly outperforming non-adaptive methods proposed in the excavation literature as well as other state-of-the-art meta-learning methods. The proposed method also demonstrates zero-shot transfer capability, successfully adapting to the NASA OWLAT platform, which serves as a state-of-the-art simulator for potential future planetary missions. These results demonstrate the potential of training deep models with simulated deployment gaps for more generalizable meta-learning in high-capacity models. Furthermore, they highlight the promise of our method in autonomous lander sampling missions by enabling landers to overcome the deployment gap between Earth and extraterrestrial bodies.
Learning to Turn: Diffusion Imitation for Robust Row Turning in Under-Canopy Robots
Aug 06, 2024

Under-canopy agricultural robots require robust navigation capabilities to enable full autonomy but struggle with tight row turning between crop rows due to degraded GPS reception, visual aliasing, occlusion, and complex vehicle dynamics. We propose an imitation learning approach using diffusion policies to learn row turning behaviors from demonstrations provided by human operators or privileged controllers. Simulation experiments in a corn field environment show potential in learning this task with only visual observations and velocity states. However, challenges remain in maintaining control within rows and handling varied initial conditions, highlighting areas for future improvement.
Optimizing Agricultural Order Fulfillment Systems: A Hybrid Tree Search Approach
Jul 19, 2024Efficient order fulfillment is vital in the agricultural industry, particularly due to the seasonal nature of seed supply chains. This paper addresses the challenge of optimizing seed orders fulfillment in a centralized warehouse where orders are processed in waves, taking into account the unpredictable arrival of seed stocks and strict order deadlines. We model the wave scheduling problem as a Markov decision process and propose an adaptive hybrid tree search algorithm that combines Monte Carlo tree search with domain-specific knowledge to efficiently navigate the complex, dynamic environment of seed distribution. By leveraging historical data and stochastic modeling, our method enables forecast-informed scheduling decisions that balance immediate requirements with long-term operational efficiency. The key idea is that we can augment Monte Carlo tree search algorithm with problem-specific side information that dynamically reduces the number of candidate actions at each decision step to handle the large state and action spaces that render traditional solution methods computationally intractable. Extensive simulations with realistic parameters-including a diverse range of products, a high volume of orders, and authentic seasonal durations-demonstrate that the proposed approach significantly outperforms existing industry standard methods.
Learning and Autonomy for Extraterrestrial Terrain Sampling: An Experience Report from OWLAT Deployment
Dec 04, 2023Extraterrestrial autonomous lander missions increasingly demand adaptive capabilities to handle the unpredictable and diverse nature of the terrain. This paper discusses the deployment of a Deep Meta-Learning with Controlled Deployment Gaps (CoDeGa) trained model for terrain scooping tasks in Ocean Worlds Lander Autonomy Testbed (OWLAT) at NASA Jet Propulsion Laboratory. The CoDeGa-powered scooping strategy is designed to adapt to novel terrains, selecting scooping actions based on the available RGB-D image data and limited experience. The paper presents our experiences with transferring the scooping framework with CoDeGa-trained model from a low-fidelity testbed to the high-fidelity OWLAT testbed. Additionally, it validates the method's performance in novel, realistic environments, and shares the lessons learned from deploying learning-based autonomy algorithms for space exploration. Experimental results from OWLAT substantiate the efficacy of CoDeGa in rapidly adapting to unfamiliar terrains and effectively making autonomous decisions under considerable domain shifts, thereby endorsing its potential utility in future extraterrestrial missions.
Welfare Maximization Algorithm for Solving Budget-Constrained Multi-Component POMDPs
Mar 18, 2023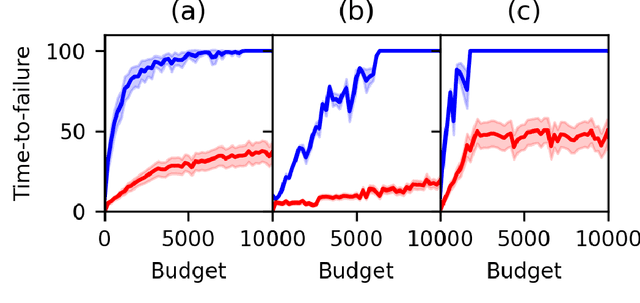

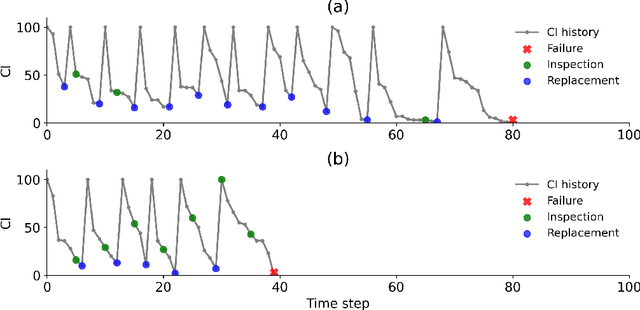
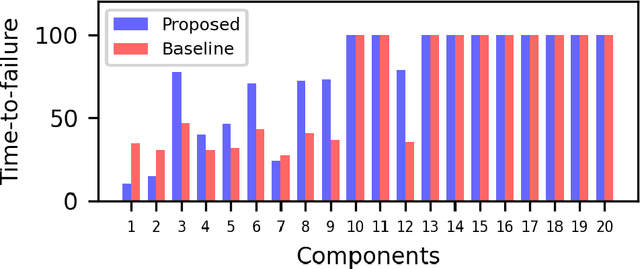
Partially Observable Markov Decision Processes (POMDPs) provide an efficient way to model real-world sequential decision making processes. Motivated by the problem of maintenance and inspection of a group of infrastructure components with independent dynamics, this paper presents an algorithm to find the optimal policy for a multi-component budget-constrained POMDP. We first introduce a budgeted-POMDP model (b-POMDP) which enables us to find the optimal policy for a POMDP while adhering to budget constraints. Next, we prove that the value function or maximal collected reward for a b-POMDP is a concave function of the budget for the finite horizon case. Our second contribution is an algorithm to calculate the optimal policy for a multi-component budget-constrained POMDP by finding the optimal budget split among the individual component POMDPs. The optimal budget split is posed as a welfare maximization problem and the solution is computed by exploiting the concave nature of the value function. We illustrate the effectiveness of the proposed algorithm by proposing a maintenance and inspection policy for a group of real-world infrastructure components with different deterioration dynamics, inspection and maintenance costs. We show that the proposed algorithm vastly outperforms the policy currently used in practice.
Few-shot Adaptation for Manipulating Granular Materials Under Domain Shift
Mar 06, 2023



Autonomous lander missions on extraterrestrial bodies will need to sample granular material while coping with domain shift, no matter how well a sampling strategy is tuned on Earth. This paper proposes an adaptive scooping strategy that uses deep Gaussian process method trained with meta-learning to learn on-line from very limited experience on the target terrains. It introduces a novel meta-training approach, Deep Meta-Learning with Controlled Deployment Gaps (CoDeGa), that explicitly trains the deep kernel to predict scooping volume robustly under large domain shifts. Employed in a Bayesian Optimization sequential decision-making framework, the proposed method allows the robot to use vision and very little on-line experience to achieve high-quality scooping actions on out-of-distribution terrains, significantly outperforming non-adaptive methods proposed in the excavation literature as well as other state-of-the-art meta-learning methods. Moreover, a dataset of 6,700 executed scoops collected on a diverse set of materials, terrain topography, and compositions is made available for future research in granular material manipulation and meta-learning.
Efficient Strategy Synthesis for MDPs with Resource Constraints
May 05, 2021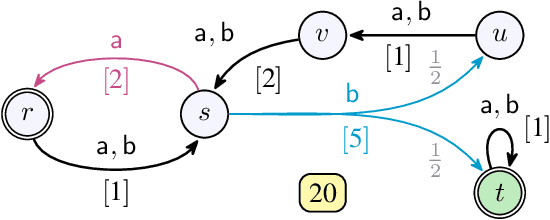
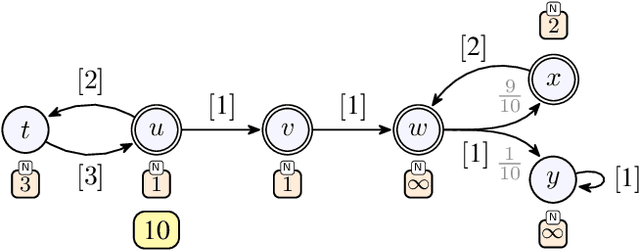
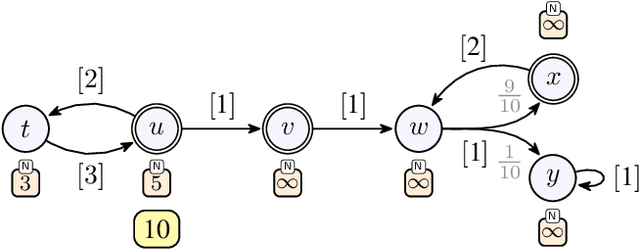
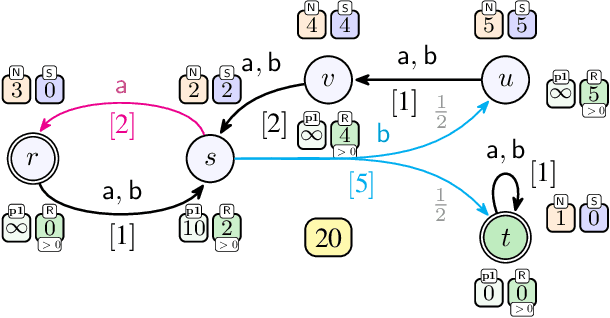
We consider qualitative strategy synthesis for the formalism called consumption Markov decision processes. This formalism can model dynamics of an agents that operates under resource constraints in a stochastic environment. The presented algorithms work in time polynomial with respect to the representation of the model and they synthesize strategies ensuring that a given set of goal states will be reached (once or infinitely many times) with probability 1 without resource exhaustion. In particular, when the amount of resource becomes too low to safely continue in the mission, the strategy changes course of the agent towards one of a designated set of reload states where the agent replenishes the resource to full capacity; with sufficient amount of resource, the agent attempts to fulfill the mission again. We also present two heuristics that attempt to reduce expected time that the agent needs to fulfill the given mission, a parameter important in practical planning. The presented algorithms were implemented and numerical examples demonstrate (i) the effectiveness (in terms of computation time) of the planning approach based on consumption Markov decision processes and (ii) the positive impact of the two heuristics on planning in a realistic example.