 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Motion Planning and Control under Unknown Nonlinear Dynamics via Predicted Reachability
Mar 31, 2026Autonomous motion planning under unknown nonlinear dynamics requires learning system properties while navigating toward a target. In this work, we develop a hierarchical planning-control framework that enables online motion synthesis with limited prior system knowledge. The state space is partitioned into polytopes and approximates the unknown nonlinear system using a piecewise-affine (PWA) model. The local affine models are identified once the agent enters the corresponding polytopes. To reduce computational complexity, we introduce a non-uniform adaptive state space partition strategy that refines the partition only in task-relevant regions. The resulting PWA system is abstracted into a directed weighted graph, whose edge existence is incrementally verified using reach control theory and predictive reachability conditions. Certified edges are weighted using provable time-to-reach bounds, while uncertain edges are assigned information-theoretic weights to guide exploration. The graph is updated online as new data becomes available, and high-level planning is performed by graph search, while low-level affine feedback controllers are synthesized to execute the plan. Furthermore, the conditions of classical reach control theory are often difficult to satisfy in underactuated settings. We therefore introduce relaxed reachability conditions to extend the framework to such systems. Simulations demonstrate effective exploration-exploitation trade-offs with formal reachability guarantees.
Amortizing Trajectory Diffusion with Keyed Drift Fields
Mar 14, 2026Diffusion-based trajectory planners can synthesize rich, multimodal action sequences for offline reinforcement learning, but their iterative denoising incurs substantial inference-time cost, making closed-loop planning slow under tight compute budgets. We study the problem of achieving diffusion-like trajectory planning behavior with one-step inference, while retaining the ability to sample diverse candidate plans and condition on the current state in a receding-horizon control loop. Our key observation is that conditional trajectory generation fails under naïve distribution-matching objectives when the similarity measure used to align generated trajectories with the dataset is dominated by unconstrained future dimensions. In practice, this causes attraction toward average trajectories, collapses action diversity, and yields near-static behavior. Our key insight is that conditional generative planning requires a conditioning-aware notion of neighborhood: trajectory updates should be computed using distances in a compact key space that reflects the condition, while still applying updates in the full trajectory space. Building on this, we introduce Keyed Drifting Policies (KDP), a one-step trajectory generator trained with a drift-field objective that attracts generated trajectories toward condition-matched dataset windows and repels them from nearby generated samples, using a stop-gradient drifted target to amortize iterative refinement into training. At inference, the resulting policy produces a full trajectory window in a single forward pass. Across standard RL benchmarks and real-time hardware deployments, KDP achieves strong performance with one-step inference and substantially lower planning latency than diffusion sampling. Project website, code and videos: https://keyed-drifting.github.io/
SCoUT: Scalable Communication via Utility-Guided Temporal Grouping in Multi-Agent Reinforcement Learning
Mar 05, 2026Communication can improve coordination in partially observed multi-agent reinforcement learning (MARL), but learning \emph{when} and \emph{who} to communicate with requires choosing among many possible sender-recipient pairs, and the effect of any single message on future reward is hard to isolate. We introduce \textbf{SCoUT} (\textbf{S}calable \textbf{Co}mmunication via \textbf{U}tility-guided \textbf{T}emporal grouping), which addresses both these challenges via temporal and agent abstraction within traditional MARL. During training, SCoUT resamples \textit{soft} agent groups every \(K\) environment steps (macro-steps) via Gumbel-Softmax; these groups are latent clusters that induce an affinity used as a differentiable prior over recipients. Using the same assignments, a group-aware critic predicts values for each agent group and maps them to per-agent baselines through the same soft assignments, reducing critic complexity and variance. Each agent is trained with a three-headed policy: environment action, send decision, and recipient selection. To obtain precise communication learning signals, we derive counterfactual communication advantages by analytically removing each sender's contribution from the recipient's aggregated messages. This counterfactual computation enables precise credit assignment for both send and recipient-selection decisions. At execution time, all centralized training components are discarded and only the per-agent policy is run, preserving decentralized execution. Project website, videos and code: \hyperlink{https://scout-comm.github.io/}{https://scout-comm.github.io/}
Navigating in Uncertain Environments with Heterogeneous Visibility
Mar 03, 2026Navigating an environment with uncertain connectivity requires a strategic balance between minimizing the cost of traversal and seeking information to resolve map ambiguities. Unlike previous approaches that rely on local sensing, we utilize a framework where nodes possess varying visibility levels, allowing for observation of distant edges from certain vantage points. We propose a novel heuristic algorithm that balances the cost of detouring to high-visibility locations against the gain in information by optimizing the sum of a custom observation reward and the cost of traversal. We introduce a technique to sample the shortest path on numerous realizations of the environment, which we use to define an edge's utility for observation and to quickly estimate the path with the highest reward. Our approach can be easily adapted to a variety of scenarios by tuning a single hyperparameter that determines the importance of observation. We test our method on a variety of uncertain navigation tasks, including a map based on real-world topographical data. The method demonstrates lower mean cost of traversal compared to a shortest path baseline that does not consider observation and has exponentially lower computational overhead compared to an existing method for balancing observation with path cost minimization.
Online Learning of Deceptive Policies under Intermittent Observation
Sep 19, 2025In supervisory control settings, autonomous systems are not monitored continuously. Instead, monitoring often occurs at sporadic intervals within known bounds. We study the problem of deception, where an agent pursues a private objective while remaining plausibly compliant with a supervisor's reference policy when observations occur. Motivated by the behavior of real, human supervisors, we situate the problem within Theory of Mind: the representation of what an observer believes and expects to see. We show that Theory of Mind can be repurposed to steer online reinforcement learning (RL) toward such deceptive behavior. We model the supervisor's expectations and distill from them a single, calibrated scalar -- the expected evidence of deviation if an observation were to happen now. This scalar combines how unlike the reference and current action distributions appear, with the agent's belief that an observation is imminent. Injected as a state-dependent weight into a KL-regularized policy improvement step within an online RL loop, this scalar informs a closed-form update that smoothly trades off self-interest and compliance, thus sidestepping hand-crafted or heuristic policies. In real-world, real-time hardware experiments on marine (ASV) and aerial (UAV) navigation, our ToM-guided RL runs online, achieves high return and success with observed-trace evidence calibrated to the supervisor's expectations.
Adaptive Stress Testing Black-Box LLM Planners
May 08, 2025Large language models (LLMs) have recently demonstrated success in generalizing across decision-making tasks including planning, control and prediction, but their tendency to hallucinate unsafe and undesired outputs poses risks. We argue that detecting such failures is necessary, especially in safety-critical scenarios. Existing black-box methods often detect hallucinations by identifying inconsistencies across multiple samples. Many of these approaches typically introduce prompt perturbations like randomizing detail order or generating adversarial inputs, with the intuition that a confident model should produce stable outputs. We first perform a manual case study showing that other forms of perturbations (e.g., adding noise, removing sensor details) cause LLMs to hallucinate in a driving environment. We then propose a novel method for efficiently searching the space of prompt perturbations using Adaptive Stress Testing (AST) with Monte-Carlo Tree Search (MCTS). Our AST formulation enables discovery of scenarios and prompts that cause language models to act with high uncertainty. By generating MCTS prompt perturbation trees across diverse scenarios, we show that offline analyses can be used at runtime to automatically generate prompts that influence model uncertainty, and to inform real-time trust assessments of an LLM.
Motion Planning and Control with Unknown Nonlinear Dynamics through Predicted Reachability
Mar 05, 2025Autonomous motion planning under unknown nonlinear dynamics presents significant challenges. An agent needs to continuously explore the system dynamics to acquire its properties, such as reachability, in order to guide system navigation adaptively. In this paper, we propose a hybrid planning-control framework designed to compute a feasible trajectory toward a target. Our approach involves partitioning the state space and approximating the system by a piecewise affine (PWA) system with constrained control inputs. By abstracting the PWA system into a directed weighted graph, we incrementally update the existence of its edges via affine system identification and reach control theory, introducing a predictive reachability condition by exploiting prior information of the unknown dynamics. Heuristic weights are assigned to edges based on whether their existence is certain or remains indeterminate. Consequently, we propose a framework that adaptively collects and analyzes data during mission execution, continually updates the predictive graph, and synthesizes a controller online based on the graph search outcomes. We demonstrate the efficacy of our approach through simulation scenarios involving a mobile robot operating in unknown terrains, with its unknown dynamics abstracted as a single integrator model.
TAB-Fields: A Maximum Entropy Framework for Mission-Aware Adversarial Planning
Dec 03, 2024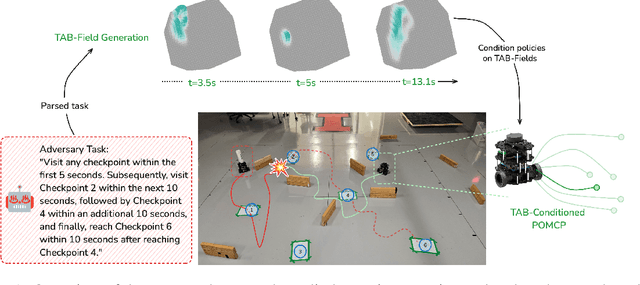
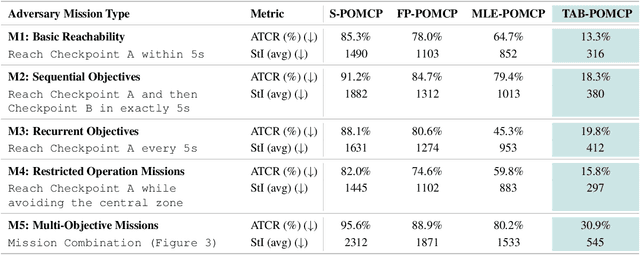
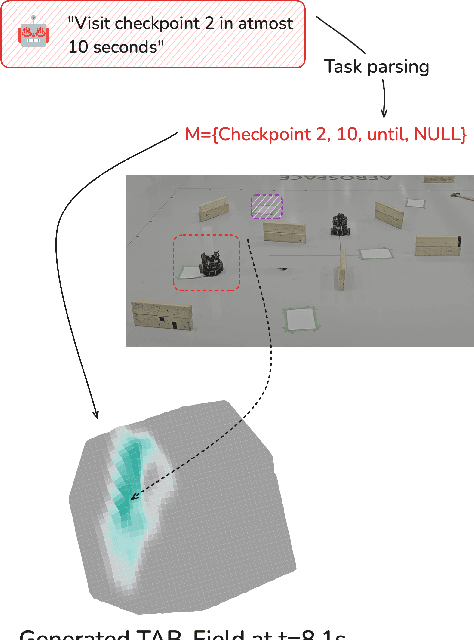
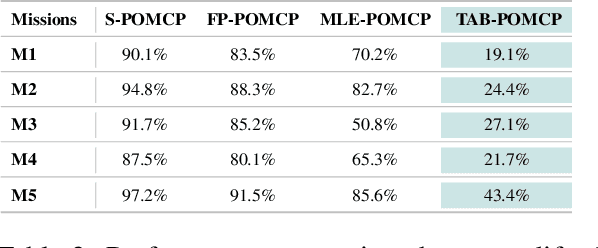
Autonomous agents operating in adversarial scenarios face a fundamental challenge: while they may know their adversaries' high-level objectives, such as reaching specific destinations within time constraints, the exact policies these adversaries will employ remain unknown. Traditional approaches address this challenge by treating the adversary's state as a partially observable element, leading to a formulation as a Partially Observable Markov Decision Process (POMDP). However, the induced belief-space dynamics in a POMDP require knowledge of the system's transition dynamics, which, in this case, depend on the adversary's unknown policy. Our key observation is that while an adversary's exact policy is unknown, their behavior is necessarily constrained by their mission objectives and the physical environment, allowing us to characterize the space of possible behaviors without assuming specific policies. In this paper, we develop Task-Aware Behavior Fields (TAB-Fields), a representation that captures adversary state distributions over time by computing the most unbiased probability distribution consistent with known constraints. We construct TAB-Fields by solving a constrained optimization problem that minimizes additional assumptions about adversary behavior beyond mission and environmental requirements. We integrate TAB-Fields with standard planning algorithms by introducing TAB-conditioned POMCP, an adaptation of Partially Observable Monte Carlo Planning. Through experiments in simulation with underwater robots and hardware implementations with ground robots, we demonstrate that our approach achieves superior performance compared to baselines that either assume specific adversary policies or neglect mission constraints altogether. Evaluation videos and code are available at https://tab-fields.github.io.
Capacity-Aware Planning and Scheduling in Budget-Constrained Monotonic MDPs: A Meta-RL Approach
Oct 28, 2024Many real-world sequential repair problems can be effectively modeled using monotonic Markov Decision Processes (MDPs), where the system state stochastically decreases and can only be increased by performing a restorative action. This work addresses the problem of solving multi-component monotonic MDPs with both budget and capacity constraints. The budget constraint limits the total number of restorative actions and the capacity constraint limits the number of restorative actions that can be performed simultaneously. While prior methods dealt with budget constraints, including capacity constraints in prior methods leads to an exponential increase in computational complexity as the number of components in the MDP grows. We propose a two-step planning approach to address this challenge. First, we partition the components of the multi-component MDP into groups, where the number of groups is determined by the capacity constraint. We achieve this partitioning by solving a Linear Sum Assignment Problem (LSAP). Each group is then allocated a fraction of the total budget proportional to its size. This partitioning effectively decouples the large multi-component MDP into smaller subproblems, which are computationally feasible because the capacity constraint is simplified and the budget constraint can be addressed using existing methods. Subsequently, we use a meta-trained PPO agent to obtain an approximately optimal policy for each group. To validate our approach, we apply it to the problem of scheduling repairs for a large group of industrial robots, constrained by a limited number of repair technicians and a total repair budget. Our results demonstrate that the proposed method outperforms baseline approaches in terms of maximizing the average uptime of the robot swarm, particularly for large swarm sizes.
Enhancing Robot Navigation Policies with Task-Specific Uncertainty Management
Oct 19, 2024
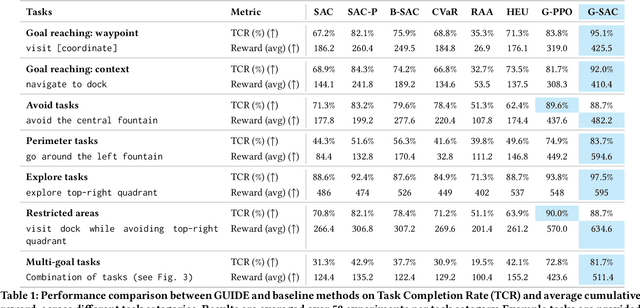
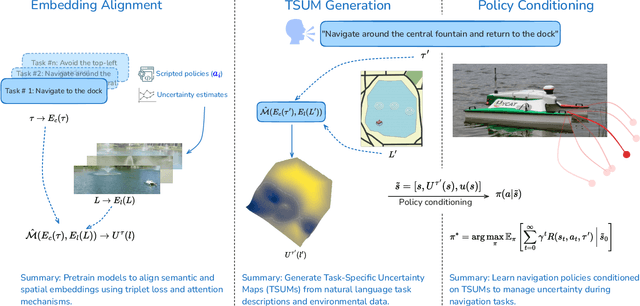
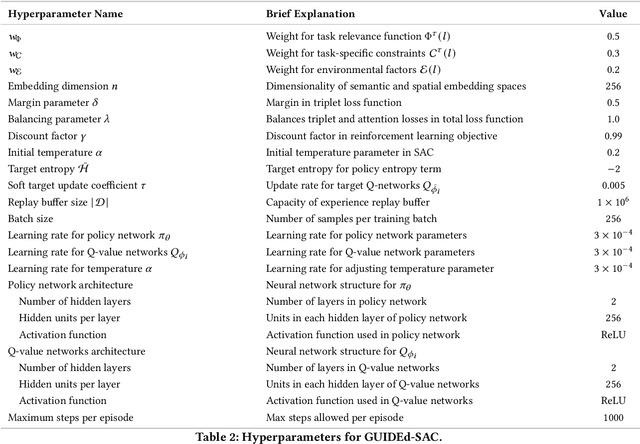
Robots performing navigation tasks in complex environments face significant challenges due to uncertainty in state estimation. Effectively managing this uncertainty is crucial, but the optimal approach varies depending on the specific details of the task: different tasks require varying levels of precision in different regions of the environment. For instance, a robot navigating a crowded space might need precise localization near obstacles but can operate effectively with less precise state estimates in open areas. This varying need for certainty in different parts of the environment, depending on the task, calls for policies that can adapt their uncertainty management strategies based on task-specific requirements. In this paper, we present a framework for integrating task-specific uncertainty requirements directly into navigation policies. We introduce Task-Specific Uncertainty Map (TSUM), which represents acceptable levels of state estimation uncertainty across different regions of the operating environment for a given task. Using TSUM, we propose Generalized Uncertainty Integration for Decision-Making and Execution (GUIDE), a policy conditioning framework that incorporates these uncertainty requirements into the robot's decision-making process. We find that conditioning policies on TSUMs provides an effective way to express task-specific uncertainty requirements and enables the robot to reason about the context-dependent value of certainty. We show how integrating GUIDE into reinforcement learning frameworks allows the agent to learn navigation policies without the need for explicit reward engineering to balance task completion and uncertainty management. We evaluate GUIDE on a variety of real-world navigation tasks and find that it demonstrates significant improvements in task completion rates compared to baselines. Evaluation videos can be found at https://guided-agents.github.io.