 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuninn: Your Trajectory Diffusion Model But Faster
May 11, 2026Diffusion-based trajectory planners can synthesize rich, multimodal robot motions, but their iterative denoising makes online planning and control prohibitively slow. Existing accelerations either modify the sampler or compress the network--sacrificing plan quality or requiring retraining without accounting for downstream control risk. We address the problem of making diffusion-based trajectory planners fast enough for real-time robot use without retraining the model or sacrificing trajectory quality, and in a way that works across diverse state-space diffusion architectures. Our key insight is that diffusion trajectory planners expose two signals we can exploit: a cheap probe of how their internal trajectory representation changes across steps, and analytic coefficients that describe how denoiser errors affect the sampler's state update. By calibrating the first signal against the second on offline runs, we obtain a per-step score that upper-bounds how far the final trajectory can deviate when we reuse a cached denoiser output, and we treat this bound as an uncertainty budget that we can spend over the denoising process. Building on this insight, we present Muninn, a training-free caching wrapper that tracks this uncertainty budget during sampling and, at each diffusion step, chooses between reusing a cached denoiser output when the predicted deviation is small and recomputing the denoiser when it is not. Across standard benchmarks Muninn delivers up to 4.6x wall-clock speedups across several trajectory diffusion models by reducing denoiser evaluations, while preserving task performance and safety metrics. Muninn further certifies that cached rollouts remain within a specified distance of their full-compute counterparts, and we validate these gains in real-time closed-loop navigation and manipulation hardware deployments. Project page: https://github.com/gokulp01/Muninn.
Energy-Efficient Multi-Robot Coverage Path Planning of Non-Convex Regions of Interests
Apr 24, 2026This letter presents an energy-efficient multi-robot coverage path planning (MRCPP) framework for large, nonconvex Regions of Interest (ROI) containing obstacles and no-fly zones (NFZ). Existing minimum-energy coverage planning algorithms utilize meta-heuristic boustrophedon workspace decomposition. Therefore, even with minimum energy objectives and energy consumption constraints, they cannot achieve optimal energy efficiency. Moreover, most existing frameworks support only a single type of robotic platform. MRCPP overcomes these limitations by: generating globally-informed swath generation, creating parallel sweeping paths with minimal turns, calculating safety buffers to ensure safe turning clearance, using an efficient mTSP solver to balance workloads and minimize mission time, and connecting disjoint segments via a modified visibility graph that tracks heading angles while maintaining transitions within safe regions. The efficacy of the proposed MRCPP framework is demonstrated through real-world experiments involving autonomous aerial vehicles (AAVs) and autonomous surface vehicles (ASVs). Evaluations demonstrate that the proposed MRCPP consistently outperforms state-of-the-art planners, reducing average total energy consumption by 3\% to 40\% for a team of 3 robots and computation time by an order of magnitude, while maintaining balanced workload distribution and strong scalability across increasing fleet sizes. The MRCPP framework is released as an open-source package and videos of real-world and simulated experiments are available at https://mrc-pp.github.io.
Online Learning of Deceptive Policies under Intermittent Observation
Sep 19, 2025In supervisory control settings, autonomous systems are not monitored continuously. Instead, monitoring often occurs at sporadic intervals within known bounds. We study the problem of deception, where an agent pursues a private objective while remaining plausibly compliant with a supervisor's reference policy when observations occur. Motivated by the behavior of real, human supervisors, we situate the problem within Theory of Mind: the representation of what an observer believes and expects to see. We show that Theory of Mind can be repurposed to steer online reinforcement learning (RL) toward such deceptive behavior. We model the supervisor's expectations and distill from them a single, calibrated scalar -- the expected evidence of deviation if an observation were to happen now. This scalar combines how unlike the reference and current action distributions appear, with the agent's belief that an observation is imminent. Injected as a state-dependent weight into a KL-regularized policy improvement step within an online RL loop, this scalar informs a closed-form update that smoothly trades off self-interest and compliance, thus sidestepping hand-crafted or heuristic policies. In real-world, real-time hardware experiments on marine (ASV) and aerial (UAV) navigation, our ToM-guided RL runs online, achieves high return and success with observed-trace evidence calibrated to the supervisor's expectations.
Deep Learning and Foundation Models for Weather Prediction: A Survey
Jan 12, 2025Physics-based numerical models have been the bedrock of atmospheric sciences for decades, offering robust solutions but often at the cost of significant computational resources. Deep learning (DL) models have emerged as powerful tools in meteorology, capable of analyzing complex weather and climate data by learning intricate dependencies and providing rapid predictions once trained. While these models demonstrate promising performance in weather prediction, often surpassing traditional physics-based methods, they still face critical challenges. This paper presents a comprehensive survey of recent deep learning and foundation models for weather prediction. We propose a taxonomy to classify existing models based on their training paradigms: deterministic predictive learning, probabilistic generative learning, and pre-training and fine-tuning. For each paradigm, we delve into the underlying model architectures, address major challenges, offer key insights, and propose targeted directions for future research. Furthermore, we explore real-world applications of these methods and provide a curated summary of open-source code repositories and widely used datasets, aiming to bridge research advancements with practical implementations while fostering open and trustworthy scientific practices in adopting cutting-edge artificial intelligence for weather prediction. The related sources are available at https://github.com/JimengShi/ DL-Foundation-Models-Weather.
Enhancing Robot Navigation Policies with Task-Specific Uncertainty Management
Oct 19, 2024
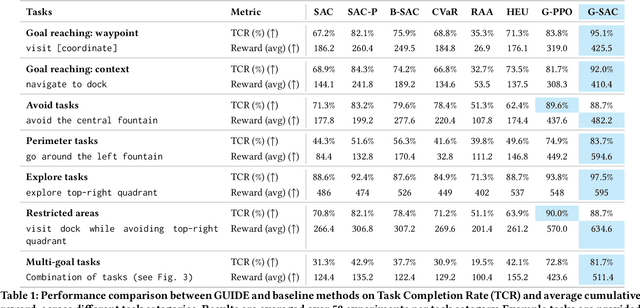
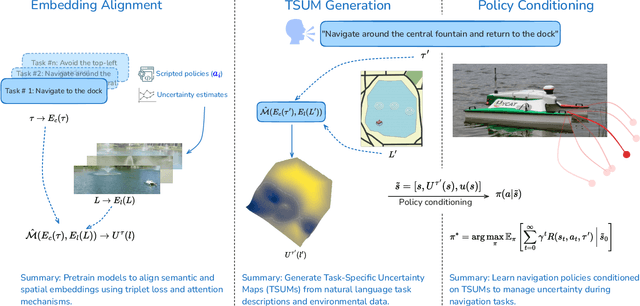
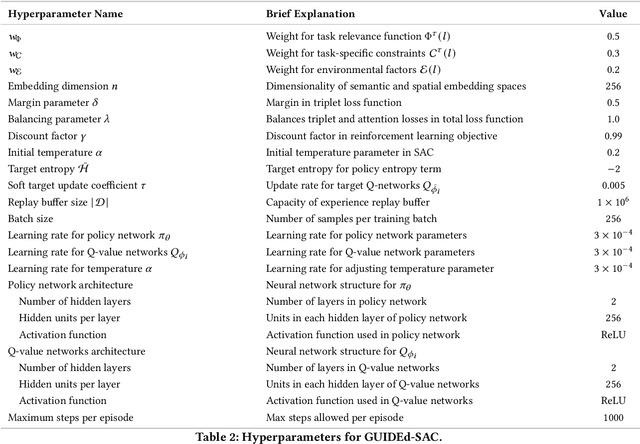
Robots performing navigation tasks in complex environments face significant challenges due to uncertainty in state estimation. Effectively managing this uncertainty is crucial, but the optimal approach varies depending on the specific details of the task: different tasks require varying levels of precision in different regions of the environment. For instance, a robot navigating a crowded space might need precise localization near obstacles but can operate effectively with less precise state estimates in open areas. This varying need for certainty in different parts of the environment, depending on the task, calls for policies that can adapt their uncertainty management strategies based on task-specific requirements. In this paper, we present a framework for integrating task-specific uncertainty requirements directly into navigation policies. We introduce Task-Specific Uncertainty Map (TSUM), which represents acceptable levels of state estimation uncertainty across different regions of the operating environment for a given task. Using TSUM, we propose Generalized Uncertainty Integration for Decision-Making and Execution (GUIDE), a policy conditioning framework that incorporates these uncertainty requirements into the robot's decision-making process. We find that conditioning policies on TSUMs provides an effective way to express task-specific uncertainty requirements and enables the robot to reason about the context-dependent value of certainty. We show how integrating GUIDE into reinforcement learning frameworks allows the agent to learn navigation policies without the need for explicit reward engineering to balance task completion and uncertainty management. We evaluate GUIDE on a variety of real-world navigation tasks and find that it demonstrates significant improvements in task completion rates compared to baselines. Evaluation videos can be found at https://guided-agents.github.io.
Towards Optimal Human-Robot Interface Design Applied to Underwater Robotics Teleoperation
Apr 04, 2023



Efficient and intuitive Human-Robot interfaces are crucial for expanding the user base of operators and enabling new applications in critical areas such as precision agriculture, automated construction, rehabilitation, and environmental monitoring. In this paper, we investigate the design of human-robot interfaces for the teleoperation of dynamical systems. The proposed framework seeks to find an optimal interface that complies with key concepts such as user comfort, efficiency, continuity, and consistency. As a proof-of-concept, we introduce an innovative approach to teleoperating underwater vehicles, allowing the translation between human body movements into vehicle control commands. This method eliminates the need for divers to work in harsh underwater environments while taking into account comfort and communication constraints. We conducted a study with human subjects using a head-mounted display attached to a smartphone to control a simulated ROV. Also, numerical experiments have demonstrated that the optimal translation is often the most intuitive and natural one, aligning with users' expectations.
Feedback Motion Planning for Long-Range Autonomous Underwater Vehicles
Nov 21, 2019

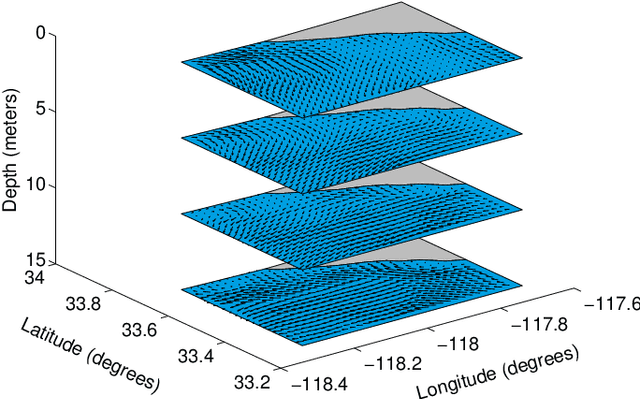
Ocean ecosystems have spatiotemporal variability and dynamic complexity that require a long-term deployment of an autonomous underwater vehicle for data collection. A new long-range autonomous underwater vehicle called Tethys is adapted to study different oceanic phenomena. Additionally, an ocean environment has external forces and moments along with changing water currents which are generally not considered in a vehicle kinematic model. In this scenario, it is not enough to generate a simple trajectory from an initial location to a goal location in an uncertain ocean as the vehicle can deviate from its intended trajectory. As such, we propose to compute a feedback plan that adapts the vehicle trajectory in the presence of any modeled or unmodeled uncertainties. In this work, we present a feedback motion planning method for the Tethys vehicle by combining a predictive ocean model and its kinematic modeling. Given a goal location, the Tethys kinematic model, and the water flow pattern, our method computes a feedback plan for the vehicle in a dynamic ocean environment that reduces its energy consumption. The computed feedback plan provides the optimal action for the Tethys vehicle to take from any location of the environment to reach the goal location considering its orientation. Our results based on actual ocean model prediction data demonstrate the applicability of our method.
Strengthening the Case for a Bayesian Approach to Car-following Model Calibration and Validation using Probabilistic Programming
Aug 07, 2019

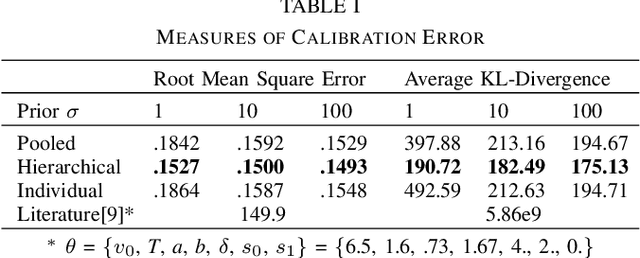
Compute and memory constraints have historically prevented traffic simulation software users from fully utilizing the predictive models underlying them. When calibrating car-following models, particularly, accommodations have included 1) using sensitivity analysis to limit the number of parameters to be calibrated, and 2) identifying only one set of parameter values using data collected from multiple car-following instances across multiple drivers. Shortcuts are further motivated by insufficient data set sizes, for which a driver may have too few instances to fully account for the variation in their driving behavior. In this paper, we demonstrate that recent technological advances can enable transportation researchers and engineers to overcome these constraints and produce calibration results that 1) outperform industry standard approaches, and 2) allow for a unique set of parameters to be estimated for each driver in a data set, even given a small amount of data. We propose a novel calibration procedure for car-following models based on Bayesian machine learning and probabilistic programming, and apply it to real-world data from a naturalistic driving study. We also discuss how this combination of mathematical and software tools can offer additional benefits such as more informative model validation and the incorporation of true-to-data uncertainty into simulation traces.
An Underactuated Vehicle Localization Method in Marine Environments
Aug 15, 2018

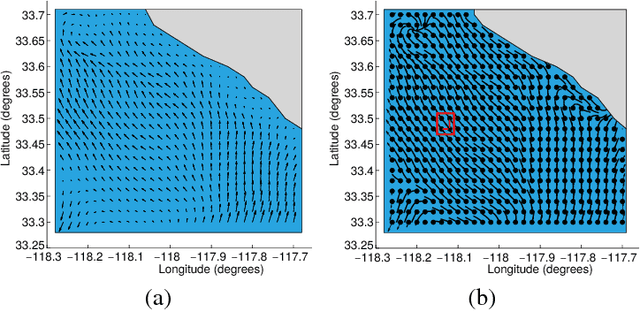
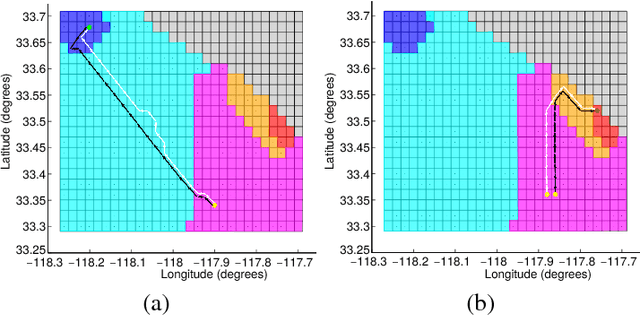
The underactuated vehicles are apposite for the long-term deployment and data collection in spatiotemporally varying marine environments. However, these vehicles need to estimate their positions (states) with intrinsic sensing in their long-term trajectories. In previous studies, autonomous underwater vehicles have commonly used vision and range sensors for autonomous state estimation. Inspired by the intrinsic sensing and the persistent deployment, we investigate the localization problem (state estimation) for an inexpensive and underactuated drifting vehicle called a drifter. In this paper, we present a localization method for the drifter making use of the observations of a proprioceptive sensor, i.e., compass. We create the water flow pattern within a given region from ocean model predictions, develop a stochastic motion model, and analyze the persistent water flow behavior. Given a distribution of initial deployment states of the drifter at a particular depth of the water column within the region and the water flow pattern, our method finds attractors and their transient groups at the given depth as the persistent behavior of the water flow. A most-likely localized trajectory of the drifter for a sequence of compass observations is generated based on the persistent behavior of the water flow and hidden Markov model. Our simulation results based on data from ocean model predictions substantiate good performance of our proposed localization method with a low error rate of the state estimation in the long-term trajectory of the drifter.
Optimal Placement and Patrolling of Autonomous Vehicles in Visibility-Based Robot Networks
Apr 13, 2018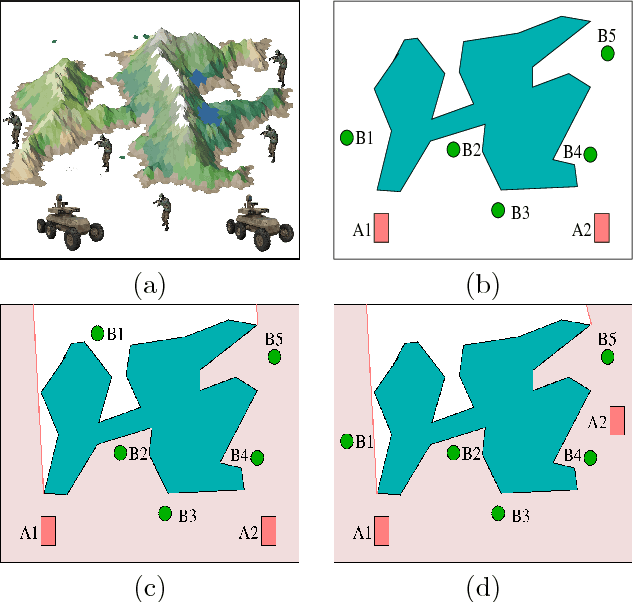
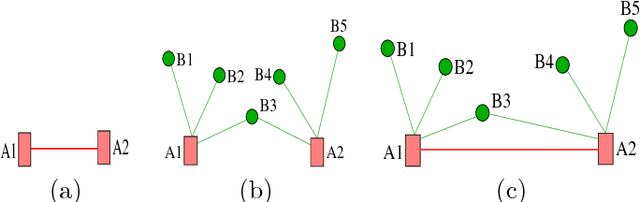
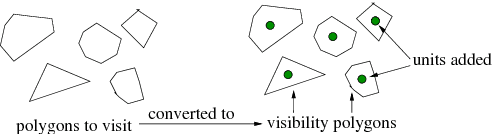
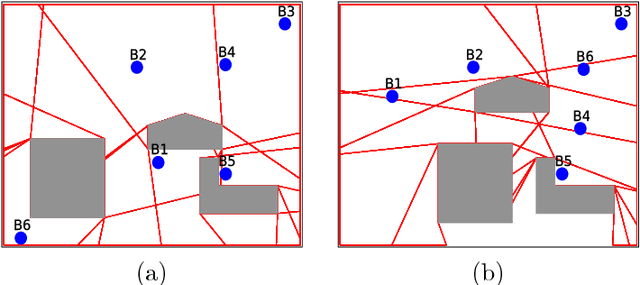
In communication-denied or contested environments, Line-of-Sight (LoS) communication (e.g free space optical communication using infrared or visible light) becomes one of the most reliable and efficient ways to send information between geographically scattered mobile units. In this paper, we consider the problem of planning optimal locations and trajectories for a group of autonomous vehicles to see a set of units that are dispersed in an environment with obstacles. The contributions of the paper are the following: 1) We propose centralized and distributed algorithms to verify that the vehicles and units form a connected network through LoS; 2) We present an algorithm that can maintain visibility-based connectivity, if possible, by relocating a single vehicle; and 3) We study the computational