 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet-Driven Masked Multiscale Reconstruction for PPG Foundation Models
Jan 18, 2026Wearable foundation models have the potential to transform digital health by learning transferable representations from large-scale biosignals collected in everyday settings. While recent progress has been made in large-scale pretraining, most approaches overlook the spectral structure of photoplethysmography (PPG) signals, wherein physiological rhythms unfold across multiple frequency bands. Motivated by the insight that many downstream health-related tasks depend on multi-resolution features spanning fine-grained waveform morphology to global rhythmic dynamics, we introduce Masked Multiscale Reconstruction (MMR) for PPG representation learning - a self-supervised pretraining framework that explicitly learns from hierarchical time-frequency scales of PPG data. The pretraining task is designed to reconstruct randomly masked out coefficients obtained from a wavelet-based multiresolution decomposition of PPG signals, forcing the transformer encoder to integrate information across temporal and spectral scales. We pretrain our model with MMR using ~17 million unlabeled 10-second PPG segments from ~32,000 smartwatch users. On 17 of 19 diverse health-related tasks, MMR trained on large-scale wearable PPG data improves over or matches state-of-the-art open-source PPG foundation models, time-series foundation models, and other self-supervised baselines. Extensive analysis of our learned embeddings and systematic ablations underscores the value of wavelet-based representations, showing that they capture robust and physiologically-grounded features. Together, these results highlight the potential of MMR as a step toward generalizable PPG foundation models.
Elevating Intrusion Detection and Security Fortification in Intelligent Networks through Cutting-Edge Machine Learning Paradigms
Dec 22, 2025The proliferation of IoT devices and their reliance on Wi-Fi networks have introduced significant security vulnerabilities, particularly the KRACK and Kr00k attacks, which exploit weaknesses in WPA2 encryption to intercept and manipulate sensitive data. Traditional IDS using classifiers face challenges such as model overfitting, incomplete feature extraction, and high false positive rates, limiting their effectiveness in real-world deployments. To address these challenges, this study proposes a robust multiclass machine learning based intrusion detection framework. The methodology integrates advanced feature selection techniques to identify critical attributes, mitigating redundancy and enhancing detection accuracy. Two distinct ML architectures are implemented: a baseline classifier pipeline and a stacked ensemble model combining noise injection, Principal Component Analysis (PCA), and meta learning to improve generalization and reduce false positives. Evaluated on the AWID3 data set, the proposed ensemble architecture achieves superior performance, with an accuracy of 98%, precision of 98%, recall of 98%, and a false positive rate of just 2%, outperforming existing state-of-the-art methods. This work demonstrates the efficacy of combining preprocessing strategies with ensemble learning to fortify network security against sophisticated Wi-Fi attacks, offering a scalable and reliable solution for IoT environments. Future directions include real-time deployment and adversarial resilience testing to further enhance the model's adaptability.
InstructNet: A Novel Approach for Multi-Label Instruction Classification through Advanced Deep Learning
Dec 20, 2025People use search engines for various topics and items, from daily essentials to more aspirational and specialized objects. Therefore, search engines have taken over as peoples preferred resource. The How To prefix has become familiar and widely used in various search styles to find solutions to particular problems. This search allows people to find sequential instructions by providing detailed guidelines to accomplish specific tasks. Categorizing instructional text is also essential for task-oriented learning and creating knowledge bases. This study uses the How To articles to determine the multi-label instruction category. We have brought this work with a dataset comprising 11,121 observations from wikiHow, where each record has multiple categories. To find out the multi-label category meticulously, we employ some transformer-based deep neural architectures, such as Generalized Autoregressive Pretraining for Language Understanding (XLNet), Bidirectional Encoder Representation from Transformers (BERT), etc. In our multi-label instruction classification process, we have reckoned our proposed architectures using accuracy and macro f1-score as the performance metrics. This thorough evaluation showed us much about our strategys strengths and drawbacks. Specifically, our implementation of the XLNet architecture has demonstrated unprecedented performance, achieving an accuracy of 97.30% and micro and macro average scores of 89.02% and 93%, a noteworthy accomplishment in multi-label classification. This high level of accuracy and macro average score is a testament to the effectiveness of the XLNet architecture in our proposed InstructNet approach. By employing a multi-level strategy in our evaluation process, we have gained a more comprehensive knowledge of the effectiveness of our proposed architectures and identified areas for forthcoming improvement and refinement.
A Comprehensive Study of the Capabilities of Large Language Models for Vulnerability Detection
Mar 25, 2024



Large Language Models (LLMs) have demonstrated great potential for code generation and other software engineering tasks. Vulnerability detection is of crucial importance to maintaining the security, integrity, and trustworthiness of software systems. Precise vulnerability detection requires reasoning about the code, making it a good case study for exploring the limits of LLMs' reasoning capabilities. Although recent work has applied LLMs to vulnerability detection using generic prompting techniques, their full capabilities for this task and the types of errors they make when explaining identified vulnerabilities remain unclear. In this paper, we surveyed eleven LLMs that are state-of-the-art in code generation and commonly used as coding assistants, and evaluated their capabilities for vulnerability detection. We systematically searched for the best-performing prompts, incorporating techniques such as in-context learning and chain-of-thought, and proposed three of our own prompting methods. Our results show that while our prompting methods improved the models' performance, LLMs generally struggled with vulnerability detection. They reported 0.5-0.63 Balanced Accuracy and failed to distinguish between buggy and fixed versions of programs in 76% of cases on average. By comprehensively analyzing and categorizing 287 instances of model reasoning, we found that 57% of LLM responses contained errors, and the models frequently predicted incorrect locations of buggy code and misidentified bug types. LLMs only correctly localized 6 out of 27 bugs in DbgBench, and these 6 bugs were predicted correctly by 70-100% of human participants. These findings suggest that despite their potential for other tasks, LLMs may fail to properly comprehend critical code structures and security-related concepts. Our data and code are available at https://figshare.com/s/78fe02e56e09ec49300b.
Do Language Models Learn Semantics of Code? A Case Study in Vulnerability Detection
Nov 07, 2023Recently, pretrained language models have shown state-of-the-art performance on the vulnerability detection task. These models are pretrained on a large corpus of source code, then fine-tuned on a smaller supervised vulnerability dataset. Due to the different training objectives and the performance of the models, it is interesting to consider whether the models have learned the semantics of code relevant to vulnerability detection, namely bug semantics, and if so, how the alignment to bug semantics relates to model performance. In this paper, we analyze the models using three distinct methods: interpretability tools, attention analysis, and interaction matrix analysis. We compare the models' influential feature sets with the bug semantic features which define the causes of bugs, including buggy paths and Potentially Vulnerable Statements (PVS). We find that (1) better-performing models also aligned better with PVS, (2) the models failed to align strongly to PVS, and (3) the models failed to align at all to buggy paths. Based on our analysis, we developed two annotation methods which highlight the bug semantics inside the model's inputs. We evaluated our approach on four distinct transformer models and four vulnerability datasets and found that our annotations improved the models' performance in the majority of settings - 11 out of 16, with up to 9.57 points improvement in F1 score compared to conventional fine-tuning. We further found that with our annotations, the models aligned up to 232% better to potentially vulnerable statements. Our findings indicate that it is helpful to provide the model with information of the bug semantics, that the model can attend to it, and motivate future work in learning more complex path-based bug semantics. Our code and data are available at https://figshare.com/s/4a16a528d6874aad51a0.
Towards Causal Deep Learning for Vulnerability Detection
Oct 13, 2023



Deep learning vulnerability detection has shown promising results in recent years. However, an important challenge that still blocks it from being very useful in practice is that the model is not robust under perturbation and it cannot generalize well over the out-of-distribution (OOD) data, e.g., applying a trained model to unseen projects in real world. We hypothesize that this is because the model learned non-robust features, e.g., variable names, that have spurious correlations with labels. When the perturbed and OOD datasets no longer have the same spurious features, the model prediction fails. To address the challenge, in this paper, we introduced causality into deep learning vulnerability detection. Our approach CausalVul consists of two phases. First, we designed novel perturbations to discover spurious features that the model may use to make predictions. Second, we applied the causal learning algorithms, specifically, do-calculus, on top of existing deep learning models to systematically remove the use of spurious features and thus promote causal based prediction. Our results show that CausalVul consistently improved the model accuracy, robustness and OOD performance for all the state-of-the-art models and datasets we experimented. To the best of our knowledge, this is the first work that introduces do calculus based causal learning to software engineering models and shows it's indeed useful for improving the model accuracy, robustness and generalization. Our replication package is located at https://figshare.com/s/0ffda320dcb96c249ef2.
Emotion Detection From Social Media Posts
Feb 11, 2023Over the last few years, social media has evolved into a medium for expressing personal views, emotions, and even business and political proposals, recommendations, and advertisements. We address the topic of identifying emotions from text data obtained from social media posts like Twitter in this research. We have deployed different traditional machine learning techniques such as Support Vector Machines (SVM), Naive Bayes, Decision Trees, and Random Forest, as well as deep neural network models such as LSTM, CNN, GRU, BiLSTM, BiGRU to classify these tweets into four emotion categories (Fear, Anger, Joy, and Sadness). Furthermore, we have constructed a BiLSTM and BiGRU ensemble model. The evaluation result shows that the deep neural network models(BiGRU, to be specific) produce the most promising results compared to traditional machine learning models, with an 87.53 % accuracy rate. The ensemble model performs even better (87.66 %), albeit the difference is not significant. This result will aid in the development of a decision-making tool that visualizes emotional fluctuations.
Predicting Participants' Performance in Programming Contests using Deep Learning Techniques
Feb 11, 2023

In recent days, the number of technology enthusiasts is increasing day by day with the prevalence of technological products and easy access to the internet. Similarly, the amount of people working behind this rapid development is rising tremendously. Computer programmers consist of a large portion of those tech-savvy people. Codeforces, an online programming and contest hosting platform used by many competitive programmers worldwide. It is regarded as one of the most standardized platforms for practicing programming problems and participate in programming contests. In this research, we propose a framework that predicts the performance of any particular contestant in the upcoming competitions as well as predicts the rating after that contest based on their practice and the performance of their previous contests.
An Empirical Study of Deep Learning Models for Vulnerability Detection
Dec 19, 2022



Deep learning (DL) models of code have recently reported great progress for vulnerability detection. In some cases, DL-based models have outperformed static analysis tools. Although many great models have been proposed, we do not yet have a good understanding of these models. This limits the further advancement of model robustness, debugging, and deployment for the vulnerability detection. In this paper, we surveyed and reproduced 9 state-of-the-art (SOTA) deep learning models on 2 widely used vulnerability detection datasets: Devign and MSR. We investigated 6 research questions in three areas, namely model capabilities, training data, and model interpretation. We experimentally demonstrated the variability between different runs of a model and the low agreement among different models' outputs. We investigated models trained for specific types of vulnerabilities compared to a model that is trained on all the vulnerabilities at once. We explored the types of programs DL may consider "hard" to handle. We investigated the relations of training data sizes and training data composition with model performance. Finally, we studied model interpretations and analyzed important features that the models used to make predictions. We believe that our findings can help better understand model results, provide guidance on preparing training data, and improve the robustness of the models. All of our datasets, code, and results are available at https://figshare.com/s/284abfba67dba448fdc2.
A Novel Multi-Centroid Template Matching Algorithm and Its Application to Cough Detection
Sep 04, 2021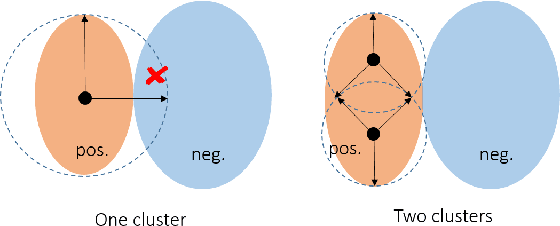
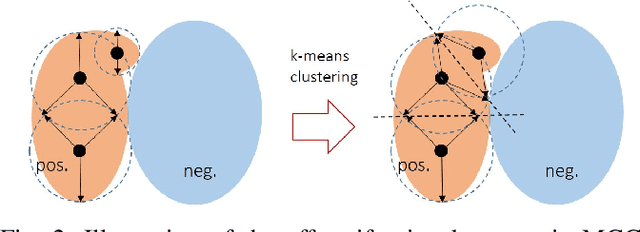
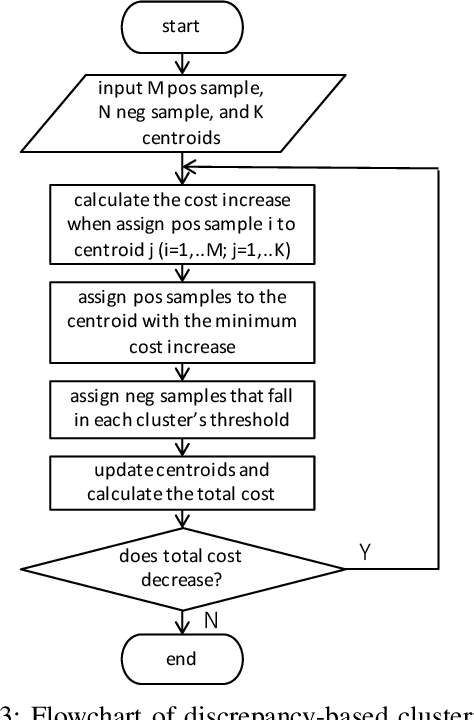
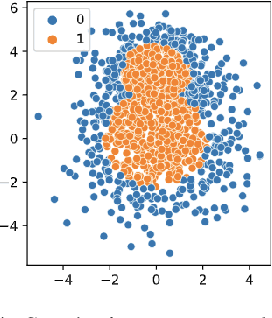
Cough is a major symptom of respiratory-related diseases. There exists a tremendous amount of work in detecting coughs from audio but there has been no effort to identify coughs from solely inertial measurement unit (IMU). Coughing causes motion across the whole body and especially on the neck and head. Therefore, head motion data during coughing captured by a head-worn IMU sensor could be leveraged to detect coughs using a template matching algorithm. In time series template matching problems, K-Nearest Neighbors (KNN) combined with elastic distance measurement (esp. Dynamic Time Warping (DTW)) achieves outstanding performance. However, it is often regarded as prohibitively time-consuming. Nearest Centroid Classifier is thereafter proposed. But the accuracy is comprised of only one centroid obtained for each class. Centroid-based Classifier performs clustering and averaging for each cluster, but requires manually setting the number of clusters. We propose a novel self-tuning multi-centroid template-matching algorithm, which can automatically adjust the number of clusters to balance accuracy and inference time. Through experiments conducted on synthetic datasets and a real-world earbud-based cough dataset, we demonstrate the superiority of our proposed algorithm and present the result of cough detection with a single accelerometer sensor on the earbuds platform.