 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveClean: Generating Line-Level Vulnerability Data via Active Learning
Dec 04, 2023
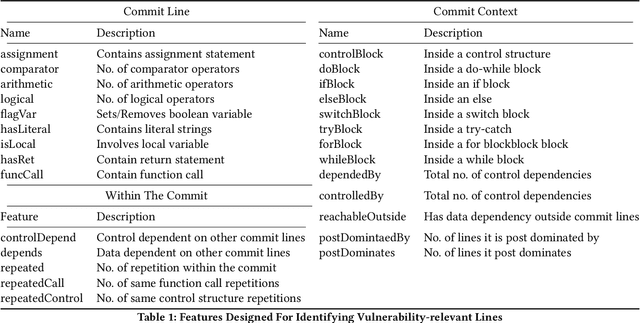
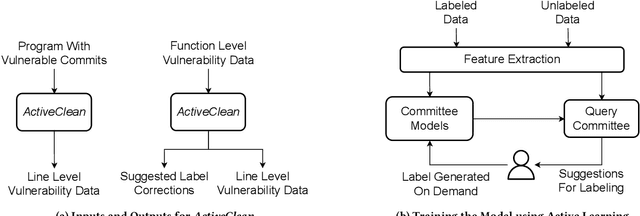
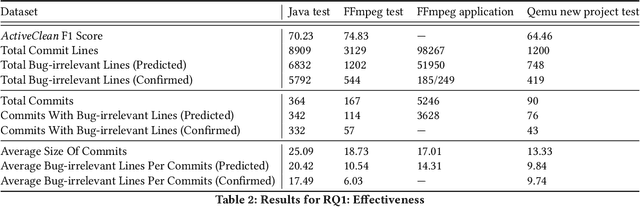
Deep learning vulnerability detection tools are increasing in popularity and have been shown to be effective. These tools rely on large volume of high quality training data, which are very hard to get. Most of the currently available datasets provide function-level labels, reporting whether a function is vulnerable or not vulnerable. However, for a vulnerability detection to be useful, we need to also know the lines that are relevant to the vulnerability. This paper makes efforts towards developing systematic tools and proposes. ActiveClean to generate the large volume of line-level vulnerability data from commits. That is, in addition to function-level labels, it also reports which lines in the function are likely responsible for vulnerability detection. In the past, static analysis has been applied to clean commits to generate line-level data. Our approach based on active learning, which is easy to use and scalable, provide a complementary approach to static analysis. We designed semantic and syntactic properties from commit lines and use them to train the model. We evaluated our approach on both Java and C datasets processing more than 4.3K commits and 119K commit lines. AcitveClean achieved an F1 score between 70-74. Further, we also show that active learning is effective by using just 400 training data to reach F1 score of 70.23. Using ActiveClean, we generate the line-level labels for the entire FFMpeg project in the Devign dataset, including 5K functions, and also detected incorrect function-level labels. We demonstrated that using our cleaned data, LineVul, a SOTA line-level vulnerability detection tool, detected 70 more vulnerable lines and 18 more vulnerable functions, and improved Top 10 accuracy from 66% to 73%.
Do Language Models Learn Semantics of Code? A Case Study in Vulnerability Detection
Nov 07, 2023Recently, pretrained language models have shown state-of-the-art performance on the vulnerability detection task. These models are pretrained on a large corpus of source code, then fine-tuned on a smaller supervised vulnerability dataset. Due to the different training objectives and the performance of the models, it is interesting to consider whether the models have learned the semantics of code relevant to vulnerability detection, namely bug semantics, and if so, how the alignment to bug semantics relates to model performance. In this paper, we analyze the models using three distinct methods: interpretability tools, attention analysis, and interaction matrix analysis. We compare the models' influential feature sets with the bug semantic features which define the causes of bugs, including buggy paths and Potentially Vulnerable Statements (PVS). We find that (1) better-performing models also aligned better with PVS, (2) the models failed to align strongly to PVS, and (3) the models failed to align at all to buggy paths. Based on our analysis, we developed two annotation methods which highlight the bug semantics inside the model's inputs. We evaluated our approach on four distinct transformer models and four vulnerability datasets and found that our annotations improved the models' performance in the majority of settings - 11 out of 16, with up to 9.57 points improvement in F1 score compared to conventional fine-tuning. We further found that with our annotations, the models aligned up to 232% better to potentially vulnerable statements. Our findings indicate that it is helpful to provide the model with information of the bug semantics, that the model can attend to it, and motivate future work in learning more complex path-based bug semantics. Our code and data are available at https://figshare.com/s/4a16a528d6874aad51a0.