 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Gap: A User Study on the Real-world Usefulness of AI-powered Vulnerability Detection & Repair in the IDE
Dec 18, 2024This paper presents the first empirical study of a vulnerability detection and fix tool with professional software developers on real projects that they own. We implemented DeepVulGuard, an IDE-integrated tool based on state-of-the-art detection and fix models, and show that it has promising performance on benchmarks of historic vulnerability data. DeepVulGuard scans code for vulnerabilities (including identifying the vulnerability type and vulnerable region of code), suggests fixes, provides natural-language explanations for alerts and fixes, leveraging chat interfaces. We recruited 17 professional software developers at Microsoft, observed their usage of the tool on their code, and conducted interviews to assess the tool's usefulness, speed, trust, relevance, and workflow integration. We also gathered detailed qualitative feedback on users' perceptions and their desired features. Study participants scanned a total of 24 projects, 6.9k files, and over 1.7 million lines of source code, and generated 170 alerts and 50 fix suggestions. We find that although state-of-the-art AI-powered detection and fix tools show promise, they are not yet practical for real-world use due to a high rate of false positives and non-applicable fixes. User feedback reveals several actionable pain points, ranging from incomplete context to lack of customization for the user's codebase. Additionally, we explore how AI features, including confidence scores, explanations, and chat interaction, can apply to vulnerability detection and fixing. Based on these insights, we offer practical recommendations for evaluating and deploying AI detection and fix models. Our code and data are available at https://doi.org/10.6084/m9.figshare.26367139.
A Comprehensive Study of the Capabilities of Large Language Models for Vulnerability Detection
Mar 25, 2024



Large Language Models (LLMs) have demonstrated great potential for code generation and other software engineering tasks. Vulnerability detection is of crucial importance to maintaining the security, integrity, and trustworthiness of software systems. Precise vulnerability detection requires reasoning about the code, making it a good case study for exploring the limits of LLMs' reasoning capabilities. Although recent work has applied LLMs to vulnerability detection using generic prompting techniques, their full capabilities for this task and the types of errors they make when explaining identified vulnerabilities remain unclear. In this paper, we surveyed eleven LLMs that are state-of-the-art in code generation and commonly used as coding assistants, and evaluated their capabilities for vulnerability detection. We systematically searched for the best-performing prompts, incorporating techniques such as in-context learning and chain-of-thought, and proposed three of our own prompting methods. Our results show that while our prompting methods improved the models' performance, LLMs generally struggled with vulnerability detection. They reported 0.5-0.63 Balanced Accuracy and failed to distinguish between buggy and fixed versions of programs in 76% of cases on average. By comprehensively analyzing and categorizing 287 instances of model reasoning, we found that 57% of LLM responses contained errors, and the models frequently predicted incorrect locations of buggy code and misidentified bug types. LLMs only correctly localized 6 out of 27 bugs in DbgBench, and these 6 bugs were predicted correctly by 70-100% of human participants. These findings suggest that despite their potential for other tasks, LLMs may fail to properly comprehend critical code structures and security-related concepts. Our data and code are available at https://figshare.com/s/78fe02e56e09ec49300b.
ActiveClean: Generating Line-Level Vulnerability Data via Active Learning
Dec 04, 2023
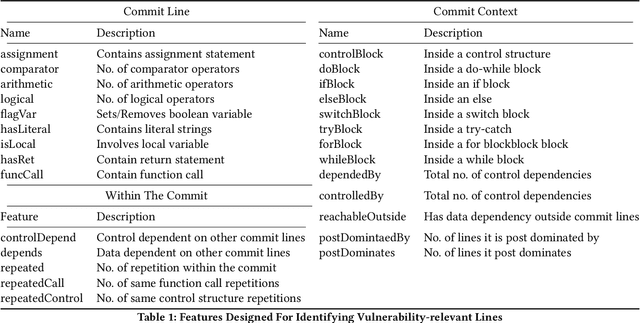
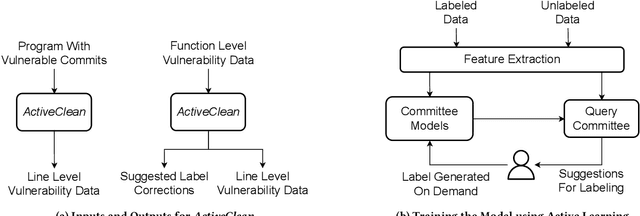
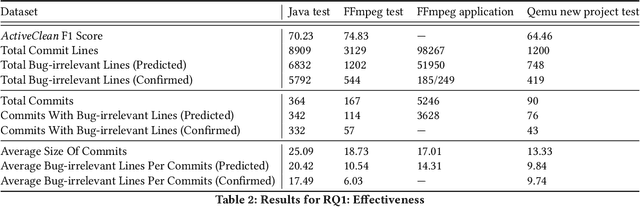
Deep learning vulnerability detection tools are increasing in popularity and have been shown to be effective. These tools rely on large volume of high quality training data, which are very hard to get. Most of the currently available datasets provide function-level labels, reporting whether a function is vulnerable or not vulnerable. However, for a vulnerability detection to be useful, we need to also know the lines that are relevant to the vulnerability. This paper makes efforts towards developing systematic tools and proposes. ActiveClean to generate the large volume of line-level vulnerability data from commits. That is, in addition to function-level labels, it also reports which lines in the function are likely responsible for vulnerability detection. In the past, static analysis has been applied to clean commits to generate line-level data. Our approach based on active learning, which is easy to use and scalable, provide a complementary approach to static analysis. We designed semantic and syntactic properties from commit lines and use them to train the model. We evaluated our approach on both Java and C datasets processing more than 4.3K commits and 119K commit lines. AcitveClean achieved an F1 score between 70-74. Further, we also show that active learning is effective by using just 400 training data to reach F1 score of 70.23. Using ActiveClean, we generate the line-level labels for the entire FFMpeg project in the Devign dataset, including 5K functions, and also detected incorrect function-level labels. We demonstrated that using our cleaned data, LineVul, a SOTA line-level vulnerability detection tool, detected 70 more vulnerable lines and 18 more vulnerable functions, and improved Top 10 accuracy from 66% to 73%.
Do Language Models Learn Semantics of Code? A Case Study in Vulnerability Detection
Nov 07, 2023Recently, pretrained language models have shown state-of-the-art performance on the vulnerability detection task. These models are pretrained on a large corpus of source code, then fine-tuned on a smaller supervised vulnerability dataset. Due to the different training objectives and the performance of the models, it is interesting to consider whether the models have learned the semantics of code relevant to vulnerability detection, namely bug semantics, and if so, how the alignment to bug semantics relates to model performance. In this paper, we analyze the models using three distinct methods: interpretability tools, attention analysis, and interaction matrix analysis. We compare the models' influential feature sets with the bug semantic features which define the causes of bugs, including buggy paths and Potentially Vulnerable Statements (PVS). We find that (1) better-performing models also aligned better with PVS, (2) the models failed to align strongly to PVS, and (3) the models failed to align at all to buggy paths. Based on our analysis, we developed two annotation methods which highlight the bug semantics inside the model's inputs. We evaluated our approach on four distinct transformer models and four vulnerability datasets and found that our annotations improved the models' performance in the majority of settings - 11 out of 16, with up to 9.57 points improvement in F1 score compared to conventional fine-tuning. We further found that with our annotations, the models aligned up to 232% better to potentially vulnerable statements. Our findings indicate that it is helpful to provide the model with information of the bug semantics, that the model can attend to it, and motivate future work in learning more complex path-based bug semantics. Our code and data are available at https://figshare.com/s/4a16a528d6874aad51a0.
Towards Causal Deep Learning for Vulnerability Detection
Oct 13, 2023



Deep learning vulnerability detection has shown promising results in recent years. However, an important challenge that still blocks it from being very useful in practice is that the model is not robust under perturbation and it cannot generalize well over the out-of-distribution (OOD) data, e.g., applying a trained model to unseen projects in real world. We hypothesize that this is because the model learned non-robust features, e.g., variable names, that have spurious correlations with labels. When the perturbed and OOD datasets no longer have the same spurious features, the model prediction fails. To address the challenge, in this paper, we introduced causality into deep learning vulnerability detection. Our approach CausalVul consists of two phases. First, we designed novel perturbations to discover spurious features that the model may use to make predictions. Second, we applied the causal learning algorithms, specifically, do-calculus, on top of existing deep learning models to systematically remove the use of spurious features and thus promote causal based prediction. Our results show that CausalVul consistently improved the model accuracy, robustness and OOD performance for all the state-of-the-art models and datasets we experimented. To the best of our knowledge, this is the first work that introduces do calculus based causal learning to software engineering models and shows it's indeed useful for improving the model accuracy, robustness and generalization. Our replication package is located at https://figshare.com/s/0ffda320dcb96c249ef2.
MixQuant: Mixed Precision Quantization with a Bit-width Optimization Search
Sep 29, 2023



Quantization is a technique for creating efficient Deep Neural Networks (DNNs), which involves performing computations and storing tensors at lower bit-widths than f32 floating point precision. Quantization reduces model size and inference latency, and therefore allows for DNNs to be deployed on platforms with constrained computational resources and real-time systems. However, quantization can lead to numerical instability caused by roundoff error which leads to inaccurate computations and therefore, a decrease in quantized model accuracy. Similarly to prior works, which have shown that both biases and activations are more sensitive to quantization and are best kept in full precision or quantized with higher bit-widths, we show that some weights are more sensitive than others which should be reflected on their quantization bit-width. To that end we propose MixQuant, a search algorithm that finds the optimal custom quantization bit-width for each layer weight based on roundoff error and can be combined with any quantization method as a form of pre-processing optimization. We show that combining MixQuant with BRECQ, a state-of-the-art quantization method, yields better quantized model accuracy than BRECQ alone. Additionally, we combine MixQuant with vanilla asymmetric quantization to show that MixQuant has the potential to optimize the performance of any quantization technique.
An Empirical Study of Deep Learning Models for Vulnerability Detection
Dec 19, 2022



Deep learning (DL) models of code have recently reported great progress for vulnerability detection. In some cases, DL-based models have outperformed static analysis tools. Although many great models have been proposed, we do not yet have a good understanding of these models. This limits the further advancement of model robustness, debugging, and deployment for the vulnerability detection. In this paper, we surveyed and reproduced 9 state-of-the-art (SOTA) deep learning models on 2 widely used vulnerability detection datasets: Devign and MSR. We investigated 6 research questions in three areas, namely model capabilities, training data, and model interpretation. We experimentally demonstrated the variability between different runs of a model and the low agreement among different models' outputs. We investigated models trained for specific types of vulnerabilities compared to a model that is trained on all the vulnerabilities at once. We explored the types of programs DL may consider "hard" to handle. We investigated the relations of training data sizes and training data composition with model performance. Finally, we studied model interpretations and analyzed important features that the models used to make predictions. We believe that our findings can help better understand model results, provide guidance on preparing training data, and improve the robustness of the models. All of our datasets, code, and results are available at https://figshare.com/s/284abfba67dba448fdc2.
DeepDFA: Dataflow Analysis-Guided Efficient Graph Learning for Vulnerability Detection
Dec 15, 2022



Deep learning-based vulnerability detection models have recently been shown to be effective and, in some cases, outperform static analysis tools. However, the highest-performing approaches use token-based transformer models, which do not leverage domain knowledge. Classical program analysis techniques such as dataflow analysis can detect many types of bugs and are the most commonly used methods in practice. Motivated by the causal relationship between bugs and dataflow analysis, we present DeepDFA, a dataflow analysis-guided graph learning framework and embedding that uses program semantic features for vulnerability detection. We show that DeepDFA is performant and efficient. DeepDFA ranked first in recall, first in generalizing over unseen projects, and second in F1 among all the state-of-the-art models we experimented with. It is also the smallest model in terms of the number of parameters, and was trained in 9 minutes, 69x faster than the highest-performing baseline. DeepDFA can be used with other models. By integrating LineVul and DeepDFA, we achieved the best vulnerability detection performance of 96.4 F1 score, 98.69 precision, and 94.22 recall.
DeepDiagnosis: Automatically Diagnosing Faults and Recommending Actionable Fixes in Deep Learning Programs
Dec 07, 2021
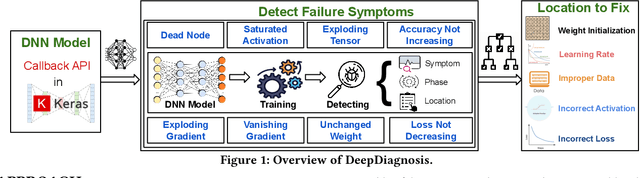
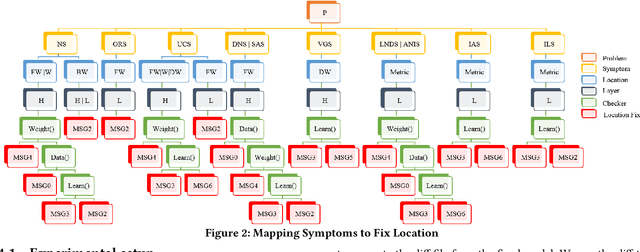
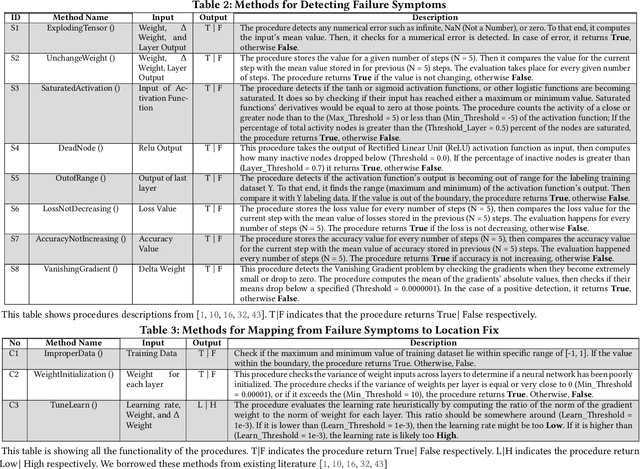
Deep Neural Networks (DNNs) are used in a wide variety of applications. However, as in any software application, DNN-based apps are afflicted with bugs. Previous work observed that DNN bug fix patterns are different from traditional bug fix patterns. Furthermore, those buggy models are non-trivial to diagnose and fix due to inexplicit errors with several options to fix them. To support developers in locating and fixing bugs, we propose DeepDiagnosis, a novel debugging approach that localizes the faults, reports error symptoms and suggests fixes for DNN programs. In the first phase, our technique monitors a training model, periodically checking for eight types of error conditions. Then, in case of problems, it reports messages containing sufficient information to perform actionable repairs to the model. In the evaluation, we thoroughly examine 444 models -53 real-world from GitHub and Stack Overflow, and 391 curated by AUTOTRAINER. DeepDiagnosis provides superior accuracy when compared to UMLUAT and DeepLocalize. Our technique is faster than AUTOTRAINER for fault localization. The results show that our approach can support additional types of models, while state-of-the-art was only able to handle classification ones. Our technique was able to report bugs that do not manifest as numerical errors during training. Also, it can provide actionable insights for fix whereas DeepLocalize can only report faults that lead to numerical errors during training. DeepDiagnosis manifests the best capabilities of fault detection, bug localization, and symptoms identification when compared to other approaches.