 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Coordinated Rename Refactoring
Jan 01, 2026The primary value of AI agents in software development lies in their ability to extend the developer's capacity for reasoning and action, not to supplant human involvement. To showcase how to use agents working in tandem with developers, we designed a novel approach for carrying out coordinated renaming. Coordinated renaming, where a single rename refactoring triggers refactorings in multiple, related identifiers, is a frequent yet challenging task. Developers must manually propagate these rename refactorings across numerous files and contexts, a process that is both tedious and highly error-prone. State-of-the-art heuristic-based approaches produce an overwhelming number of false positives, while vanilla Large Language Models (LLMs) provide incomplete suggestions due to their limited context and inability to interact with refactoring tools. This leaves developers with incomplete refactorings or burdens them with filtering too many false positives. Coordinated renaming is exactly the kind of repetitive task that agents can significantly reduce the developers' burden while keeping them in the driver's seat. We designed, implemented, and evaluated the first multi-agent framework that automates coordinated renaming. It operates on a key insight: a developer's initial refactoring is a clue to infer the scope of related refactorings. Our Scope Inference Agent first transforms this clue into an explicit, natural-language Declared Scope. The Planned Execution Agent then uses this as a strict plan to identify program elements that should undergo refactoring and safely executes the changes by invoking the IDE's own trusted refactoring APIs. Finally, the Replication Agent uses it to guide the project-wide search. We first conducted a formative study on the practice of coordinated renaming in 609K commits in 100 open-source projects and surveyed 205 developers ...
IRepair: An Intent-Aware Approach to Repair Data-Driven Errors in Large Language Models
Feb 12, 2025Not a day goes by without hearing about the impressive feats of large language models (LLMs), and equally, not a day passes without hearing about their challenges. LLMs are notoriously vulnerable to biases in their dataset, leading to issues such as toxicity. While domain-adaptive training has been employed to mitigate these issues, these techniques often address all model parameters indiscriminately during the repair process, resulting in poor repair quality and reduced model versatility. In this paper, we introduce a novel dynamic slicing-based intent-aware LLM repair strategy, IRepair. This approach selectively targets the most error-prone sections of the model for repair. Specifically, we propose dynamically slicing the model's most sensitive layers that require immediate attention, concentrating repair efforts on those areas. This method enables more effective repairs with potentially less impact on the model's overall performance by altering a smaller portion of the model. We evaluated our technique on three models from the GPT2 and GPT-Neo families, with parameters ranging from 800M to 1.6B, in a toxicity mitigation setup. Our results show that IRepair repairs errors 43.6% more effectively while causing 46% less disruption to general performance compared to the closest baseline, direct preference optimization. Our empirical analysis also reveals that errors are more concentrated in a smaller section of the model, with the top 20% of layers exhibiting 773% more error density than the remaining 80\%. This highlights the need for selective repair. Additionally, we demonstrate that a dynamic selection approach is essential for addressing errors dispersed throughout the model, ensuring a robust and efficient repair.
Inferring Data Preconditions from Deep Learning Models for Trustworthy Prediction in Deployment
Jan 26, 2024
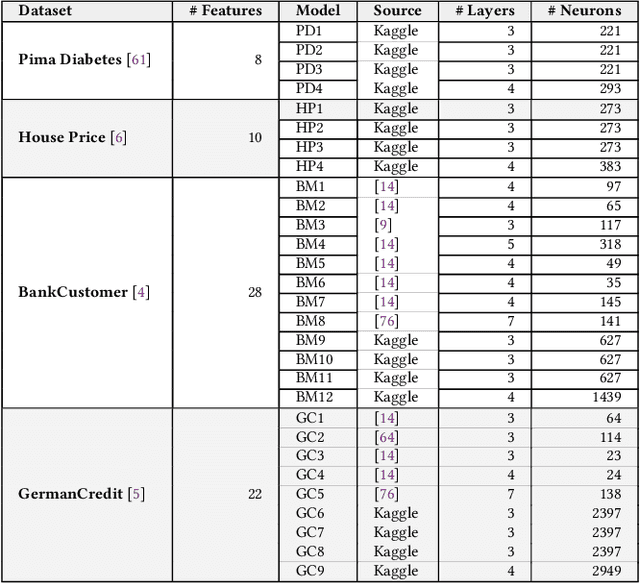


Deep learning models are trained with certain assumptions about the data during the development stage and then used for prediction in the deployment stage. It is important to reason about the trustworthiness of the model's predictions with unseen data during deployment. Existing methods for specifying and verifying traditional software are insufficient for this task, as they cannot handle the complexity of DNN model architecture and expected outcomes. In this work, we propose a novel technique that uses rules derived from neural network computations to infer data preconditions for a DNN model to determine the trustworthiness of its predictions. Our approach, DeepInfer involves introducing a novel abstraction for a trained DNN model that enables weakest precondition reasoning using Dijkstra's Predicate Transformer Semantics. By deriving rules over the inductive type of neural network abstract representation, we can overcome the matrix dimensionality issues that arise from the backward non-linear computation from the output layer to the input layer. We utilize the weakest precondition computation using rules of each kind of activation function to compute layer-wise precondition from the given postcondition on the final output of a deep neural network. We extensively evaluated DeepInfer on 29 real-world DNN models using four different datasets collected from five different sources and demonstrated the utility, effectiveness, and performance improvement over closely related work. DeepInfer efficiently detects correct and incorrect predictions of high-accuracy models with high recall (0.98) and high F-1 score (0.84) and has significantly improved over prior technique, SelfChecker. The average runtime overhead of DeepInfer is low, 0.22 sec for all unseen datasets. We also compared runtime overhead using the same hardware settings and found that DeepInfer is 3.27 times faster than SelfChecker.
Mutation-based Fault Localization of Deep Neural Networks
Sep 10, 2023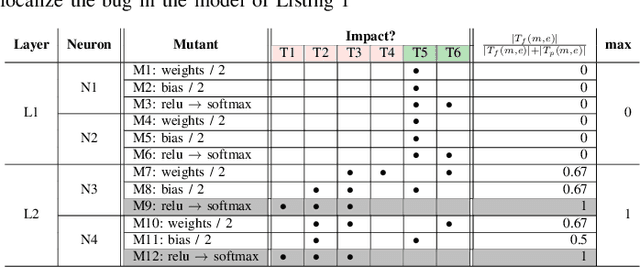
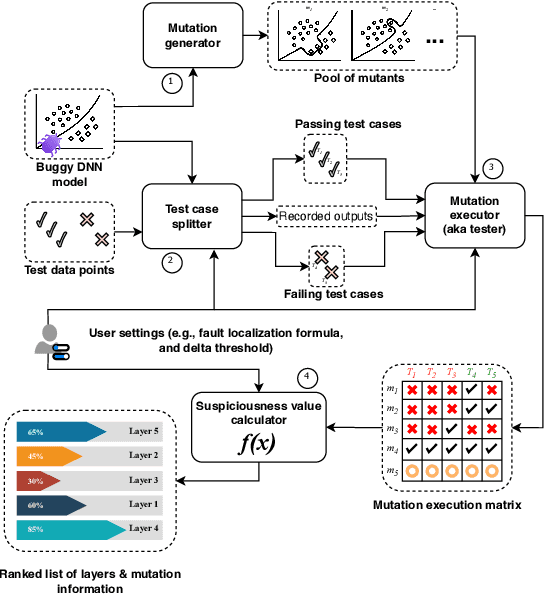

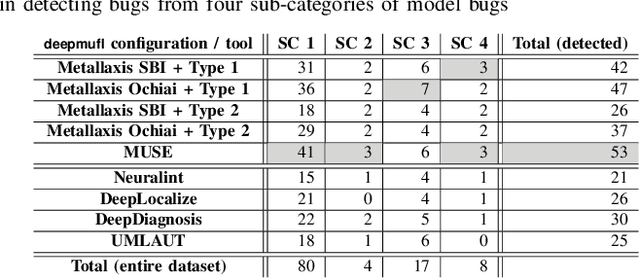
Deep neural networks (DNNs) are susceptible to bugs, just like other types of software systems. A significant uptick in using DNN, and its applications in wide-ranging areas, including safety-critical systems, warrant extensive research on software engineering tools for improving the reliability of DNN-based systems. One such tool that has gained significant attention in the recent years is DNN fault localization. This paper revisits mutation-based fault localization in the context of DNN models and proposes a novel technique, named deepmufl, applicable to a wide range of DNN models. We have implemented deepmufl and have evaluated its effectiveness using 109 bugs obtained from StackOverflow. Our results show that deepmufl detects 53/109 of the bugs by ranking the buggy layer in top-1 position, outperforming state-of-the-art static and dynamic DNN fault localization systems that are also designed to target the class of bugs supported by deepmufl. Moreover, we observed that we can halve the fault localization time for a pre-trained model using mutation selection, yet losing only 7.55% of the bugs localized in top-1 position.
What Kinds of Contracts Do ML APIs Need?
Jul 26, 2023Recent work has shown that Machine Learning (ML) programs are error-prone and called for contracts for ML code. Contracts, as in the design by contract methodology, help document APIs and aid API users in writing correct code. The question is: what kinds of contracts would provide the most help to API users? We are especially interested in what kinds of contracts help API users catch errors at earlier stages in the ML pipeline. We describe an empirical study of posts on Stack Overflow of the four most often-discussed ML libraries: TensorFlow, Scikit-learn, Keras, and PyTorch. For these libraries, our study extracted 413 informal (English) API specifications. We used these specifications to understand the following questions. What are the root causes and effects behind ML contract violations? Are there common patterns of ML contract violations? When does understanding ML contracts require an advanced level of ML software expertise? Could checking contracts at the API level help detect the violations in early ML pipeline stages? Our key findings are that the most commonly needed contracts for ML APIs are either checking constraints on single arguments of an API or on the order of API calls. The software engineering community could employ existing contract mining approaches to mine these contracts to promote an increased understanding of ML APIs. We also noted a need to combine behavioral and temporal contract mining approaches. We report on categories of required ML contracts, which may help designers of contract languages.
Fix Fairness, Don't Ruin Accuracy: Performance Aware Fairness Repair using AutoML
Jun 15, 2023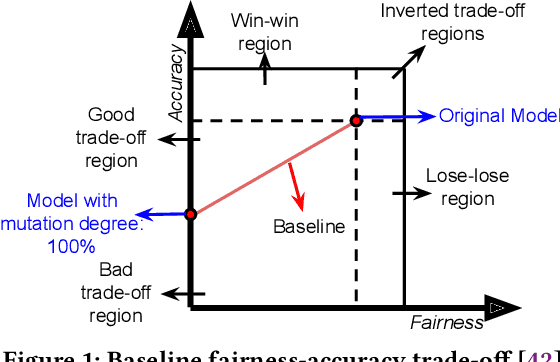

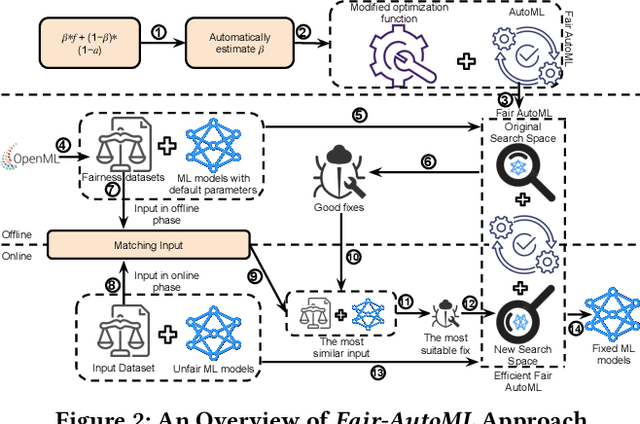
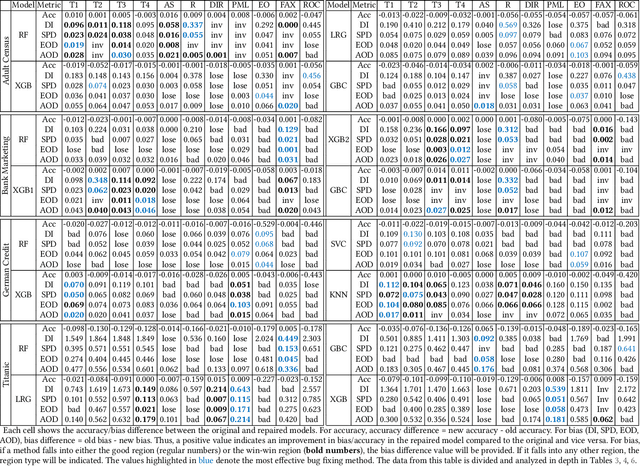
Machine learning (ML) is increasingly being used in critical decision-making software, but incidents have raised questions about the fairness of ML predictions. To address this issue, new tools and methods are needed to mitigate bias in ML-based software. Previous studies have proposed bias mitigation algorithms that only work in specific situations and often result in a loss of accuracy. Our proposed solution is a novel approach that utilizes automated machine learning (AutoML) techniques to mitigate bias. Our approach includes two key innovations: a novel optimization function and a fairness-aware search space. By improving the default optimization function of AutoML and incorporating fairness objectives, we are able to mitigate bias with little to no loss of accuracy. Additionally, we propose a fairness-aware search space pruning method for AutoML to reduce computational cost and repair time. Our approach, built on the state-of-the-art Auto-Sklearn tool, is designed to reduce bias in real-world scenarios. In order to demonstrate the effectiveness of our approach, we evaluated our approach on four fairness problems and 16 different ML models, and our results show a significant improvement over the baseline and existing bias mitigation techniques. Our approach, Fair-AutoML, successfully repaired 60 out of 64 buggy cases, while existing bias mitigation techniques only repaired up to 44 out of 64 cases.
Decomposing a Recurrent Neural Network into Modules for Enabling Reusability and Replacement
Dec 15, 2022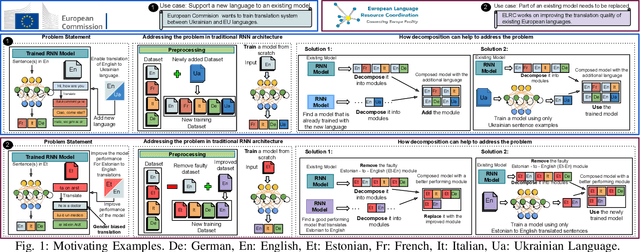
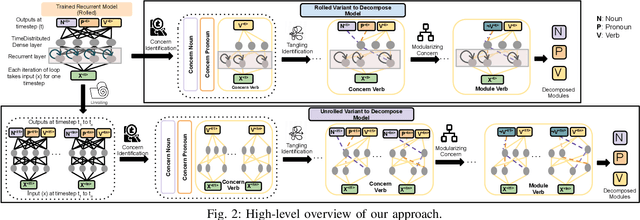

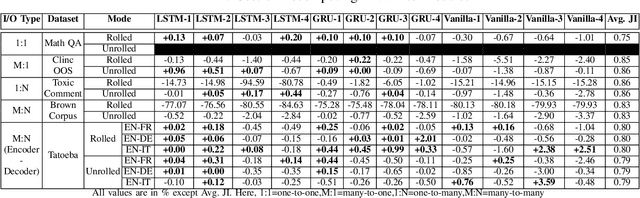
Can we take a recurrent neural network (RNN) trained to translate between languages and augment it to support a new natural language without retraining the model from scratch? Can we fix the faulty behavior of the RNN by replacing portions associated with the faulty behavior? Recent works on decomposing a fully connected neural network (FCNN) and convolutional neural network (CNN) into modules have shown the value of engineering deep models in this manner, which is standard in traditional SE but foreign for deep learning models. However, prior works focus on the image-based multiclass classification problems and cannot be applied to RNN due to (a) different layer structures, (b) loop structures, (c) different types of input-output architectures, and (d) usage of both nonlinear and logistic activation functions. In this work, we propose the first approach to decompose an RNN into modules. We study different types of RNNs, i.e., Vanilla, LSTM, and GRU. Further, we show how such RNN modules can be reused and replaced in various scenarios. We evaluate our approach against 5 canonical datasets (i.e., Math QA, Brown Corpus, Wiki-toxicity, Clinc OOS, and Tatoeba) and 4 model variants for each dataset. We found that decomposing a trained model has a small cost (Accuracy: -0.6%, BLEU score: +0.10%). Also, the decomposed modules can be reused and replaced without needing to retrain.
Fairify: Fairness Verification of Neural Networks
Dec 14, 2022Fairness of machine learning (ML) software has become a major concern in the recent past. Although recent research on testing and improving fairness have demonstrated impact on real-world software, providing fairness guarantee in practice is still lacking. Certification of ML models is challenging because of the complex decision-making process of the models. In this paper, we proposed Fairify, an SMT-based approach to verify individual fairness property in neural network (NN) models. Individual fairness ensures that any two similar individuals get similar treatment irrespective of their protected attributes e.g., race, sex, age. Verifying this fairness property is hard because of the global checking and non-linear computation nodes in NN. We proposed sound approach to make individual fairness verification tractable for the developers. The key idea is that many neurons in the NN always remain inactive when a smaller part of the input domain is considered. So, Fairify leverages whitebox access to the models in production and then apply formal analysis based pruning. Our approach adopts input partitioning and then prunes the NN for each partition to provide fairness certification or counterexample. We leveraged interval arithmetic and activation heuristic of the neurons to perform the pruning as necessary. We evaluated Fairify on 25 real-world neural networks collected from four different sources, and demonstrated the effectiveness, scalability and performance over baseline and closely related work. Fairify is also configurable based on the domain and size of the NN. Our novel formulation of the problem can answer targeted verification queries with relaxations and counterexamples, which have practical implications.
Towards Understanding Fairness and its Composition in Ensemble Machine Learning
Dec 08, 2022Machine Learning (ML) software has been widely adopted in modern society, with reported fairness implications for minority groups based on race, sex, age, etc. Many recent works have proposed methods to measure and mitigate algorithmic bias in ML models. The existing approaches focus on single classifier-based ML models. However, real-world ML models are often composed of multiple independent or dependent learners in an ensemble (e.g., Random Forest), where the fairness composes in a non-trivial way. How does fairness compose in ensembles? What are the fairness impacts of the learners on the ultimate fairness of the ensemble? Can fair learners result in an unfair ensemble? Furthermore, studies have shown that hyperparameters influence the fairness of ML models. Ensemble hyperparameters are more complex since they affect how learners are combined in different categories of ensembles. Understanding the impact of ensemble hyperparameters on fairness will help programmers design fair ensembles. Today, we do not understand these fully for different ensemble algorithms. In this paper, we comprehensively study popular real-world ensembles: bagging, boosting, stacking and voting. We have developed a benchmark of 168 ensemble models collected from Kaggle on four popular fairness datasets. We use existing fairness metrics to understand the composition of fairness. Our results show that ensembles can be designed to be fairer without using mitigation techniques. We also identify the interplay between fairness composition and data characteristics to guide fair ensemble design. Finally, our benchmark can be leveraged for further research on fair ensembles. To the best of our knowledge, this is one of the first and largest studies on fairness composition in ensembles yet presented in the literature.
DeepDiagnosis: Automatically Diagnosing Faults and Recommending Actionable Fixes in Deep Learning Programs
Dec 07, 2021
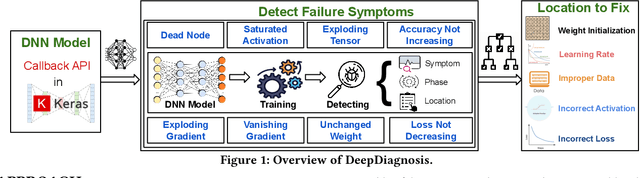
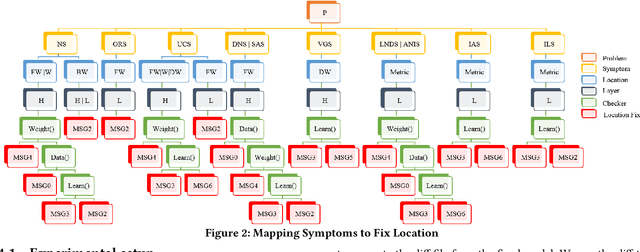
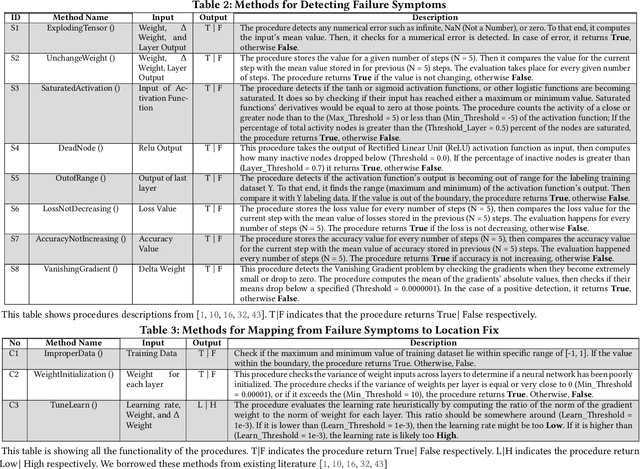
Deep Neural Networks (DNNs) are used in a wide variety of applications. However, as in any software application, DNN-based apps are afflicted with bugs. Previous work observed that DNN bug fix patterns are different from traditional bug fix patterns. Furthermore, those buggy models are non-trivial to diagnose and fix due to inexplicit errors with several options to fix them. To support developers in locating and fixing bugs, we propose DeepDiagnosis, a novel debugging approach that localizes the faults, reports error symptoms and suggests fixes for DNN programs. In the first phase, our technique monitors a training model, periodically checking for eight types of error conditions. Then, in case of problems, it reports messages containing sufficient information to perform actionable repairs to the model. In the evaluation, we thoroughly examine 444 models -53 real-world from GitHub and Stack Overflow, and 391 curated by AUTOTRAINER. DeepDiagnosis provides superior accuracy when compared to UMLUAT and DeepLocalize. Our technique is faster than AUTOTRAINER for fault localization. The results show that our approach can support additional types of models, while state-of-the-art was only able to handle classification ones. Our technique was able to report bugs that do not manifest as numerical errors during training. Also, it can provide actionable insights for fix whereas DeepLocalize can only report faults that lead to numerical errors during training. DeepDiagnosis manifests the best capabilities of fault detection, bug localization, and symptoms identification when compared to other approaches.