 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRe-Code: Collaborative Reinforcement Learning for Code Generation
May 24, 2026Large language models (LLMs) have achieved strong performance in code generation, but most methods rely on autoregressive decoding without global planning, often leading to locally coherent yet globally suboptimal solutions (e.g., failing test cases or inefficient complexity). While recent approaches such as Chain-of-Thought (CoT) and multi-agent systems (MAS) introduce planning, their limited role specialization and coordination hinder performance on complex tasks. To address the challenges of coordination and specialization in multi-agent code generation, we propose Collaborative Reinforcement Code (CoRe-Code), a framework for role specialized LLM agents that enhances inter-agent coordination to generate more accurate and efficient code. CoRe-Code adopts a simple Planner-Coder paradigm, where the Planner produces high-level plans and the Coder executes them to generate code. We further introduce a collaboration-aware reinforcement learning stage based on Group Relative Policy Optimization (GRPO) to enhance role specialization and alignment. Experiments show that CoRe-Code outperforms a wide range of existing RL-based and multi-agent methods. In addition, we demonstrate that CoRe-Code can generalize to other multi-agent frameworks (e.g., Retrieval and Debugging agents), highlighting its flexibility and scalability. We evaluate CoRe-Code on multiple benchmarks of varying difficulty using three base models. Compared to existing baselines, the results show consistent improvements in accuracy, while also achieving higher efficiency in terms of execution time and memory usage, demonstrating the effectiveness and practicality of CoRe-Code.
Plan Then Action:High-Level Planning Guidance Reinforcement Learning for LLM Reasoning
Oct 02, 2025Large language models (LLMs) have demonstrated remarkable reasoning abilities in complex tasks, often relying on Chain-of-Thought (CoT) reasoning. However, due to their autoregressive token-level generation, the reasoning process is largely constrained to local decision-making and lacks global planning. This limitation frequently results in redundant, incoherent, or inaccurate reasoning, which significantly degrades overall performance. Existing approaches, such as tree-based algorithms and reinforcement learning (RL), attempt to address this issue but suffer from high computational costs and often fail to produce optimal reasoning trajectories. To tackle this challenge, we propose Plan-Then-Action Enhanced Reasoning with Group Relative Policy Optimization PTA-GRPO, a two-stage framework designed to improve both high-level planning and fine-grained CoT reasoning. In the first stage, we leverage advanced LLMs to distill CoT into compact high-level guidance, which is then used for supervised fine-tuning (SFT). In the second stage, we introduce a guidance-aware RL method that jointly optimizes the final output and the quality of high-level guidance, thereby enhancing reasoning effectiveness. We conduct extensive experiments on multiple mathematical reasoning benchmarks, including MATH, AIME2024, AIME2025, and AMC, across diverse base models such as Qwen2.5-7B-Instruct, Qwen3-8B, Qwen3-14B, and LLaMA3.2-3B. Experimental results demonstrate that PTA-GRPO consistently achieves stable and significant improvements across different models and tasks, validating its effectiveness and generalization.
FairSense: Long-Term Fairness Analysis of ML-Enabled Systems
Jan 03, 2025

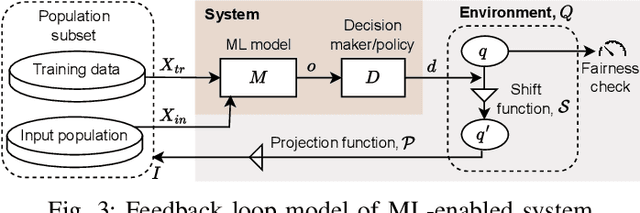
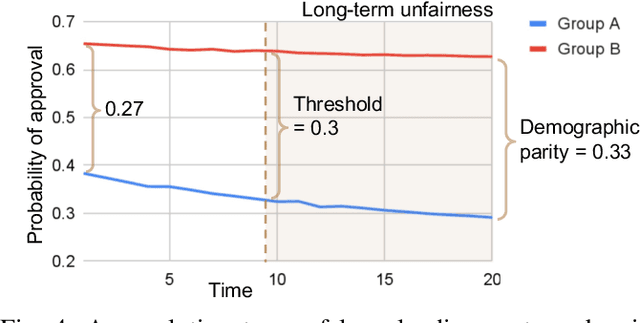
Algorithmic fairness of machine learning (ML) models has raised significant concern in the recent years. Many testing, verification, and bias mitigation techniques have been proposed to identify and reduce fairness issues in ML models. The existing methods are model-centric and designed to detect fairness issues under static settings. However, many ML-enabled systems operate in a dynamic environment where the predictive decisions made by the system impact the environment, which in turn affects future decision-making. Such a self-reinforcing feedback loop can cause fairness violations in the long term, even if the immediate outcomes are fair. In this paper, we propose a simulation-based framework called FairSense to detect and analyze long-term unfairness in ML-enabled systems. Given a fairness requirement, FairSense performs Monte-Carlo simulation to enumerate evolution traces for each system configuration. Then, FairSense performs sensitivity analysis on the space of possible configurations to understand the impact of design options and environmental factors on the long-term fairness of the system. We demonstrate FairSense's potential utility through three real-world case studies: Loan lending, opioids risk scoring, and predictive policing.
Fix Fairness, Don't Ruin Accuracy: Performance Aware Fairness Repair using AutoML
Jun 15, 2023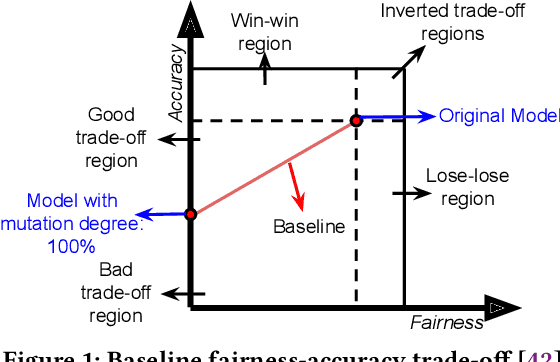

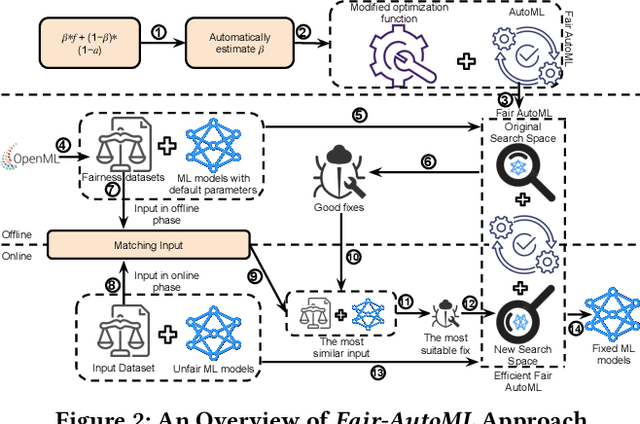
Machine learning (ML) is increasingly being used in critical decision-making software, but incidents have raised questions about the fairness of ML predictions. To address this issue, new tools and methods are needed to mitigate bias in ML-based software. Previous studies have proposed bias mitigation algorithms that only work in specific situations and often result in a loss of accuracy. Our proposed solution is a novel approach that utilizes automated machine learning (AutoML) techniques to mitigate bias. Our approach includes two key innovations: a novel optimization function and a fairness-aware search space. By improving the default optimization function of AutoML and incorporating fairness objectives, we are able to mitigate bias with little to no loss of accuracy. Additionally, we propose a fairness-aware search space pruning method for AutoML to reduce computational cost and repair time. Our approach, built on the state-of-the-art Auto-Sklearn tool, is designed to reduce bias in real-world scenarios. In order to demonstrate the effectiveness of our approach, we evaluated our approach on four fairness problems and 16 different ML models, and our results show a significant improvement over the baseline and existing bias mitigation techniques. Our approach, Fair-AutoML, successfully repaired 60 out of 64 buggy cases, while existing bias mitigation techniques only repaired up to 44 out of 64 cases.
Fairify: Fairness Verification of Neural Networks
Dec 14, 2022Fairness of machine learning (ML) software has become a major concern in the recent past. Although recent research on testing and improving fairness have demonstrated impact on real-world software, providing fairness guarantee in practice is still lacking. Certification of ML models is challenging because of the complex decision-making process of the models. In this paper, we proposed Fairify, an SMT-based approach to verify individual fairness property in neural network (NN) models. Individual fairness ensures that any two similar individuals get similar treatment irrespective of their protected attributes e.g., race, sex, age. Verifying this fairness property is hard because of the global checking and non-linear computation nodes in NN. We proposed sound approach to make individual fairness verification tractable for the developers. The key idea is that many neurons in the NN always remain inactive when a smaller part of the input domain is considered. So, Fairify leverages whitebox access to the models in production and then apply formal analysis based pruning. Our approach adopts input partitioning and then prunes the NN for each partition to provide fairness certification or counterexample. We leveraged interval arithmetic and activation heuristic of the neurons to perform the pruning as necessary. We evaluated Fairify on 25 real-world neural networks collected from four different sources, and demonstrated the effectiveness, scalability and performance over baseline and closely related work. Fairify is also configurable based on the domain and size of the NN. Our novel formulation of the problem can answer targeted verification queries with relaxations and counterexamples, which have practical implications.
Towards Understanding Fairness and its Composition in Ensemble Machine Learning
Dec 08, 2022



Machine Learning (ML) software has been widely adopted in modern society, with reported fairness implications for minority groups based on race, sex, age, etc. Many recent works have proposed methods to measure and mitigate algorithmic bias in ML models. The existing approaches focus on single classifier-based ML models. However, real-world ML models are often composed of multiple independent or dependent learners in an ensemble (e.g., Random Forest), where the fairness composes in a non-trivial way. How does fairness compose in ensembles? What are the fairness impacts of the learners on the ultimate fairness of the ensemble? Can fair learners result in an unfair ensemble? Furthermore, studies have shown that hyperparameters influence the fairness of ML models. Ensemble hyperparameters are more complex since they affect how learners are combined in different categories of ensembles. Understanding the impact of ensemble hyperparameters on fairness will help programmers design fair ensembles. Today, we do not understand these fully for different ensemble algorithms. In this paper, we comprehensively study popular real-world ensembles: bagging, boosting, stacking and voting. We have developed a benchmark of 168 ensemble models collected from Kaggle on four popular fairness datasets. We use existing fairness metrics to understand the composition of fairness. Our results show that ensembles can be designed to be fairer without using mitigation techniques. We also identify the interplay between fairness composition and data characteristics to guide fair ensemble design. Finally, our benchmark can be leveraged for further research on fair ensembles. To the best of our knowledge, this is one of the first and largest studies on fairness composition in ensembles yet presented in the literature.
Fair Preprocessing: Towards Understanding Compositional Fairness of Data Transformers in Machine Learning Pipeline
Jun 18, 2021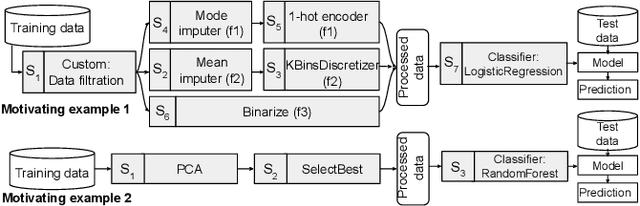
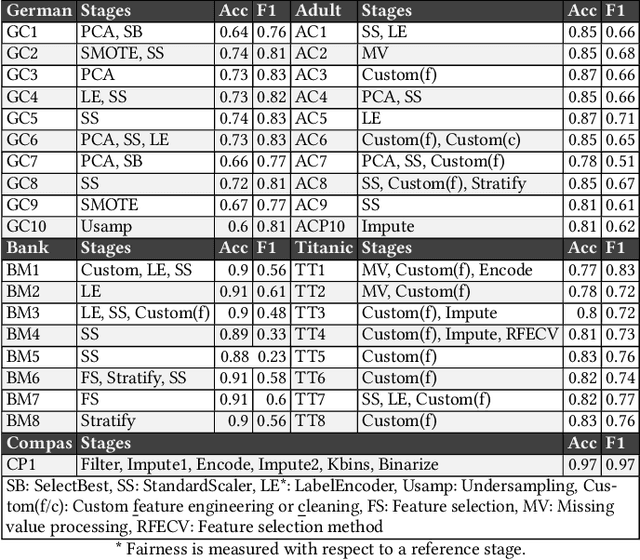

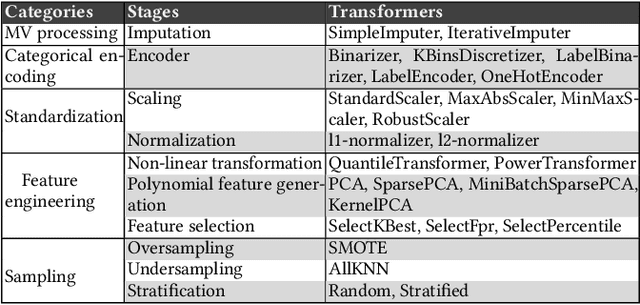
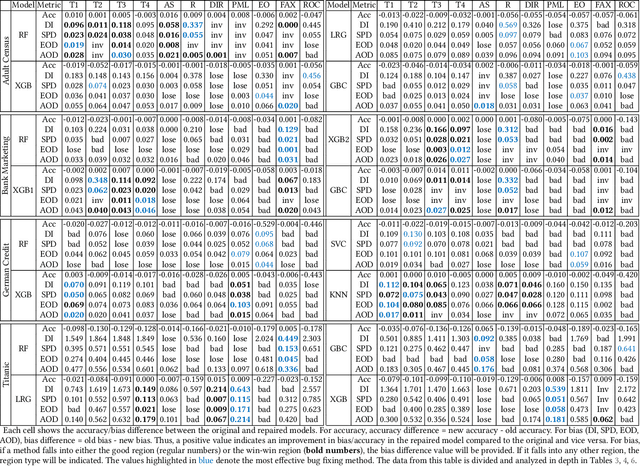
In recent years, many incidents have been reported where machine learning models exhibited discrimination among people based on race, sex, age, etc. Research has been conducted to measure and mitigate unfairness in machine learning models. For a machine learning task, it is a common practice to build a pipeline that includes an ordered set of data preprocessing stages followed by a classifier. However, most of the research on fairness has considered a single classifier based prediction task. What are the fairness impacts of the preprocessing stages in machine learning pipeline? Furthermore, studies showed that often the root cause of unfairness is ingrained in the data itself, rather than the model. But no research has been conducted to measure the unfairness caused by a specific transformation made in the data preprocessing stage. In this paper, we introduced the causal method of fairness to reason about the fairness impact of data preprocessing stages in ML pipeline. We leveraged existing metrics to define the fairness measures of the stages. Then we conducted a detailed fairness evaluation of the preprocessing stages in 37 pipelines collected from three different sources. Our results show that certain data transformers are causing the model to exhibit unfairness. We identified a number of fairness patterns in several categories of data transformers. Finally, we showed how the local fairness of a preprocessing stage composes in the global fairness of the pipeline. We used the fairness composition to choose appropriate downstream transformer that mitigates unfairness in the machine learning pipeline.
* ESEC/FSE'2021: The 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, August 23-28, 2021
Do the Machine Learning Models on a Crowd Sourced Platform Exhibit Bias? An Empirical Study on Model Fairness
May 21, 2020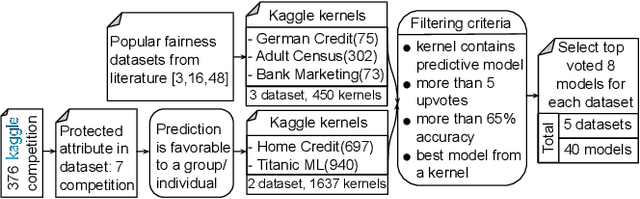
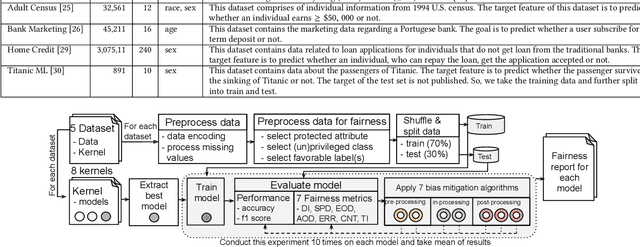
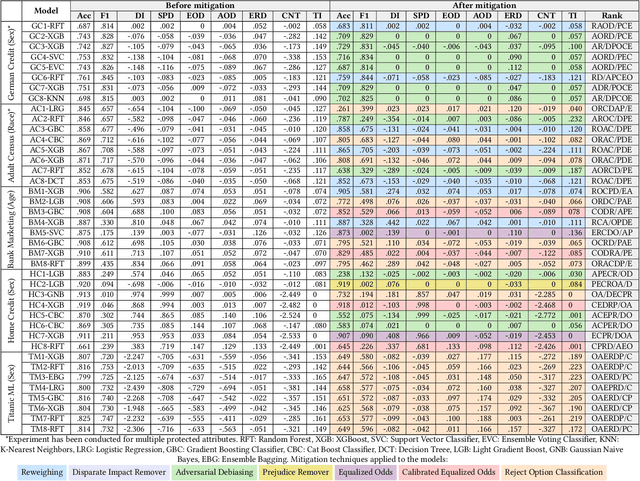

Machine learning models are increasingly being used in important decision-making software such as approving bank loans, recommending criminal sentencing, hiring employees, and so on. It is important to ensure the fairness of these models so that no discrimination is made between different groups in a protected attribute (e.g., race, sex, age) while decision making. Algorithms have been developed to measure unfairness and mitigate them to a certain extent. In this paper, we have focused on the empirical evaluation of fairness and mitigations on real-world machine learning models. We have created a benchmark of 40 top-rated models from Kaggle used for 5 different tasks, and then using a comprehensive set of fairness metrics evaluated their fairness. Then, we have applied 7 mitigation techniques on these models and analyzed the fairness, mitigation results, and impacts on performance. We have found that some model optimization techniques result in inducing unfairness in the models. On the other hand, although there are some fairness control mechanisms in machine learning libraries, they are not documented. The mitigation algorithm also exhibit common patterns such as mitigation in the post-processing is often costly (in terms of performance) and mitigation in the pre-processing stage is preferred in most cases. We have also presented different trade-off choices of fairness mitigation decisions. Our study suggests future research directions to reduce the gap between theoretical fairness aware algorithms and the software engineering methods to leverage them in practice.
* ESEC/FSE'20: The 28th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering