 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
Different Horses for Different Courses: Comparing Bias Mitigation Algorithms in ML
Nov 19, 2024
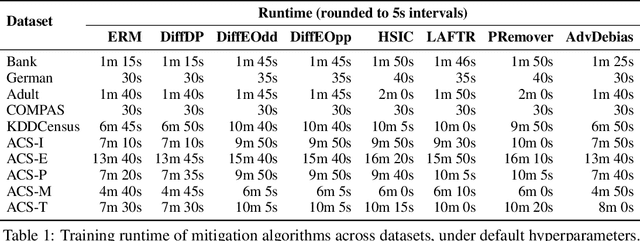


With fairness concerns gaining significant attention in Machine Learning (ML), several bias mitigation techniques have been proposed, often compared against each other to find the best method. These benchmarking efforts tend to use a common setup for evaluation under the assumption that providing a uniform environment ensures a fair comparison. However, bias mitigation techniques are sensitive to hyperparameter choices, random seeds, feature selection, etc., meaning that comparison on just one setting can unfairly favour certain algorithms. In this work, we show significant variance in fairness achieved by several algorithms and the influence of the learning pipeline on fairness scores. We highlight that most bias mitigation techniques can achieve comparable performance, given the freedom to perform hyperparameter optimization, suggesting that the choice of the evaluation parameters-rather than the mitigation technique itself-can sometimes create the perceived superiority of one method over another. We hope our work encourages future research on how various choices in the lifecycle of developing an algorithm impact fairness, and trends that guide the selection of appropriate algorithms.
CoDefeater: Using LLMs To Find Defeaters in Assurance Cases
Jul 18, 2024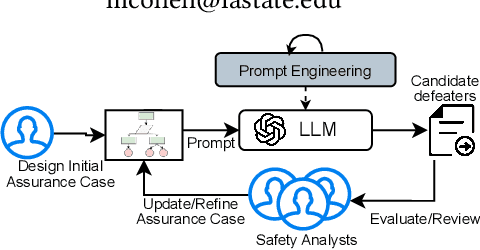



Constructing assurance cases is a widely used, and sometimes required, process toward demonstrating that safety-critical systems will operate safely in their planned environment. To mitigate the risk of errors and missing edge cases, the concept of defeaters - arguments or evidence that challenge claims in an assurance case - has been introduced. Defeaters can provide timely detection of weaknesses in the arguments, prompting further investigation and timely mitigations. However, capturing defeaters relies on expert judgment, experience, and creativity and must be done iteratively due to evolving requirements and regulations. This paper proposes CoDefeater, an automated process to leverage large language models (LLMs) for finding defeaters. Initial results on two systems show that LLMs can efficiently find known and unforeseen feasible defeaters to support safety analysts in enhancing the completeness and confidence of assurance cases.
Long-Term Fairness Inquiries and Pursuits in Machine Learning: A Survey of Notions, Methods, and Challenges
Jun 10, 2024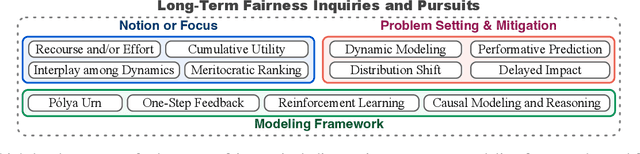

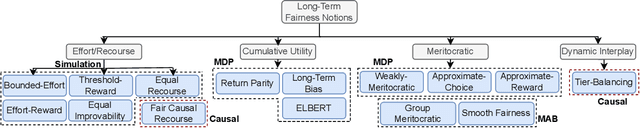

The widespread integration of Machine Learning systems in daily life, particularly in high-stakes domains, has raised concerns about the fairness implications. While prior works have investigated static fairness measures, recent studies reveal that automated decision-making has long-term implications and that off-the-shelf fairness approaches may not serve the purpose of achieving long-term fairness. Additionally, the existence of feedback loops and the interaction between models and the environment introduces additional complexities that may deviate from the initial fairness goals. In this survey, we review existing literature on long-term fairness from different perspectives and present a taxonomy for long-term fairness studies. We highlight key challenges and consider future research directions, analyzing both current issues and potential further explorations.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Towards Engineering Fair and Equitable Software Systems for Managing Low-Altitude Airspace Authorizations
Feb 03, 2024



Small Unmanned Aircraft Systems (sUAS) have gained widespread adoption across a diverse range of applications. This has introduced operational complexities within shared airspaces and an increase in reported incidents, raising safety concerns. In response, the U.S. Federal Aviation Administration (FAA) is developing a UAS Traffic Management (UTM) system to control access to airspace based on an sUAS's predicted ability to safely complete its mission. However, a fully automated system capable of swiftly approving or denying flight requests can be prone to bias and must consider safety, transparency, and fairness to diverse stakeholders. In this paper, we present an initial study that explores stakeholders' perspectives on factors that should be considered in an automated system. Results indicate flight characteristics and environmental conditions were perceived as most important but pilot and drone capabilities should also be considered. Further, several respondents indicated an aversion to any AI-supported automation, highlighting the need for full transparency in automated decision-making. Results provide a societal perspective on the challenges of automating UTM flight authorization decisions and help frame the ongoing design of a solution acceptable to the broader sUAS community.
A Survey on Intersectional Fairness in Machine Learning: Notions, Mitigation, and Challenges
May 12, 2023



The widespread adoption of Machine Learning systems, especially in more decision-critical applications such as criminal sentencing and bank loans, has led to increased concerns about fairness implications. Algorithms and metrics have been developed to mitigate and measure these discriminations. More recently, works have identified a more challenging form of bias called intersectional bias, which encompasses multiple sensitive attributes, such as race and gender, together. In this survey, we review the state-of-the-art in intersectional fairness. We present a taxonomy for intersectional notions of fairness and mitigation. Finally, we identify the key challenges and provide researchers with guidelines for future directions.
Towards Understanding Fairness and its Composition in Ensemble Machine Learning
Dec 08, 2022Machine Learning (ML) software has been widely adopted in modern society, with reported fairness implications for minority groups based on race, sex, age, etc. Many recent works have proposed methods to measure and mitigate algorithmic bias in ML models. The existing approaches focus on single classifier-based ML models. However, real-world ML models are often composed of multiple independent or dependent learners in an ensemble (e.g., Random Forest), where the fairness composes in a non-trivial way. How does fairness compose in ensembles? What are the fairness impacts of the learners on the ultimate fairness of the ensemble? Can fair learners result in an unfair ensemble? Furthermore, studies have shown that hyperparameters influence the fairness of ML models. Ensemble hyperparameters are more complex since they affect how learners are combined in different categories of ensembles. Understanding the impact of ensemble hyperparameters on fairness will help programmers design fair ensembles. Today, we do not understand these fully for different ensemble algorithms. In this paper, we comprehensively study popular real-world ensembles: bagging, boosting, stacking and voting. We have developed a benchmark of 168 ensemble models collected from Kaggle on four popular fairness datasets. We use existing fairness metrics to understand the composition of fairness. Our results show that ensembles can be designed to be fairer without using mitigation techniques. We also identify the interplay between fairness composition and data characteristics to guide fair ensemble design. Finally, our benchmark can be leveraged for further research on fair ensembles. To the best of our knowledge, this is one of the first and largest studies on fairness composition in ensembles yet presented in the literature.