 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPinRec: Unifying Generative Retrieval and Ranking at Pinterest Scale
May 29, 2026Modern recommendation systems predominantly train retrieval and ranking as separate models despite both increasingly relying on large transformers encoding the same user behavior data, duplicating parameters, compute, and serving cost. Prior work unifies the model architecture but not the full pipeline: input formats, training procedures, and serving stacks remain fragmented across stages. We present UniPinRec, which achieves full-stack unification of retrieval and ranking at Pinterest: one input format, one model, one training stage, deployed within existing serving infrastructure. A shared transformer encodes the user action sequence into candidate-independent representations that branch into retrieval (ANN dot-product) and ranking (cross-attention) via task-specific heads. Three ideas make this work: (1) Masked Action Modeling (MAM) eliminates interleaving, enabling weight sharing without doubling context length; (2) Blended training examples pair action sequences with feedview impression slates to satisfy both objectives jointly; (3) Cross-stage KV cache sharing reuses user-history computation from retrieval for ranking, reducing total FLOPs versus serving two independent models. Deployed in the Pinterest core surfaces, UniPinRec delivers approximately +1% online engagement lift while cutting end-to-end serving latency by 11.1% and lifting QPS by 63.6%. To our knowledge, this is the first full-stack unification of retrieval and ranking, covering inputs, model, training and serving, deployed in a production recommendation system.
Cosmo3DFlow: Wavelet Flow Matching for Spatial-to-Spectral Compression in Reconstructing the Early Universe
Feb 10, 2026Reconstructing the early Universe from the evolved present-day Universe is a challenging and computationally demanding problem in modern astrophysics. We devise a novel generative framework, Cosmo3DFlow, designed to address dimensionality and sparsity, the critical bottlenecks inherent in current state-of-the-art methods for cosmological inference. By integrating 3D Discrete Wavelet Transform (DWT) with flow matching, we effectively represent high-dimensional cosmological structures. The Wavelet Transform addresses the ``void problem'' by translating spatial emptiness into spectral sparsity. It decouples high-frequency details from low-frequency structures through spatial compression, and wavelet-space velocity fields facilitate stable ordinary differential equation (ODE) solvers with large step sizes. Using large-scale cosmological $N$-body simulations, at $128^3$ resolution, we achieve up to $50\times$ faster sampling than diffusion models, combining a $10\times$ reduction in integration steps with lower per-step computational cost from wavelet compression. Our results enable initial conditions to be sampled in seconds, compared to minutes for previous methods.
Infi-Med: Low-Resource Medical MLLMs with Robust Reasoning Evaluation
May 29, 2025
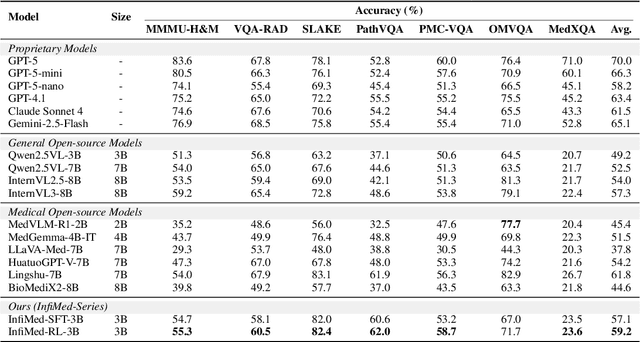
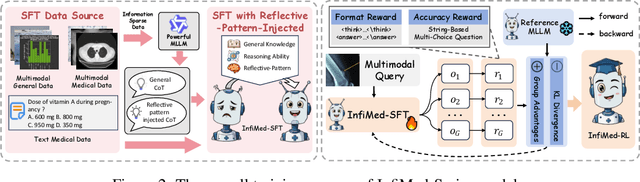
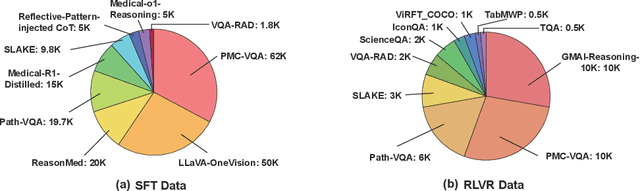
Multimodal large language models (MLLMs) have demonstrated promising prospects in healthcare, particularly for addressing complex medical tasks, supporting multidisciplinary treatment (MDT), and enabling personalized precision medicine. However, their practical deployment faces critical challenges in resource efficiency, diagnostic accuracy, clinical considerations, and ethical privacy. To address these limitations, we propose Infi-Med, a comprehensive framework for medical MLLMs that introduces three key innovations: (1) a resource-efficient approach through curating and constructing high-quality supervised fine-tuning (SFT) datasets with minimal sample requirements, with a forward-looking design that extends to both pretraining and posttraining phases; (2) enhanced multimodal reasoning capabilities for cross-modal integration and clinical task understanding; and (3) a systematic evaluation system that assesses model performance across medical modalities and task types. Our experiments demonstrate that Infi-Med achieves state-of-the-art (SOTA) performance in general medical reasoning while maintaining rapid adaptability to clinical scenarios. The framework establishes a solid foundation for deploying MLLMs in real-world healthcare settings by balancing model effectiveness with operational constraints.
MambaLoc: Efficient Camera Localisation via State Space Model
Aug 20, 2024



Location information is pivotal for the automation and intelligence of terminal devices and edge-cloud IoT systems, such as autonomous vehicles and augmented reality. However, achieving reliable positioning across diverse IoT applications remains challenging due to significant training costs and the necessity of densely collected data. To tackle these issues, we have innovatively applied the selective state space (SSM) model to visual localization, introducing a new model named MambaLoc. The proposed model demonstrates exceptional training efficiency by capitalizing on the SSM model's strengths in efficient feature extraction, rapid computation, and memory optimization, and it further ensures robustness in sparse data environments due to its parameter sparsity. Additionally, we propose the Global Information Selector (GIS), which leverages selective SSM to implicitly achieve the efficient global feature extraction capabilities of Non-local Neural Networks. This design leverages the computational efficiency of the SSM model alongside the Non-local Neural Networks' capacity to capture long-range dependencies with minimal layers. Consequently, the GIS enables effective global information capture while significantly accelerating convergence. Our extensive experimental validation using public indoor and outdoor datasets first demonstrates our model's effectiveness, followed by evidence of its versatility with various existing localization models. Our code and models are publicly available to support further research and development in this area.
Long-Term Fairness Inquiries and Pursuits in Machine Learning: A Survey of Notions, Methods, and Challenges
Jun 10, 2024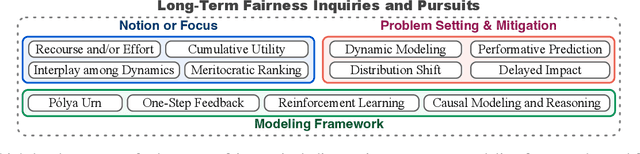

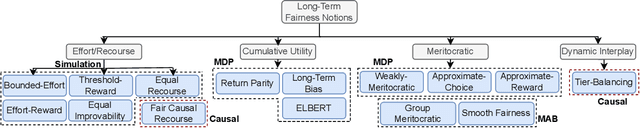

The widespread integration of Machine Learning systems in daily life, particularly in high-stakes domains, has raised concerns about the fairness implications. While prior works have investigated static fairness measures, recent studies reveal that automated decision-making has long-term implications and that off-the-shelf fairness approaches may not serve the purpose of achieving long-term fairness. Additionally, the existence of feedback loops and the interaction between models and the environment introduces additional complexities that may deviate from the initial fairness goals. In this survey, we review existing literature on long-term fairness from different perspectives and present a taxonomy for long-term fairness studies. We highlight key challenges and consider future research directions, analyzing both current issues and potential further explorations.
WSCLoc: Weakly-Supervised Sparse-View Camera Relocalization
Mar 22, 2024Despite the advancements in deep learning for camera relocalization tasks, obtaining ground truth pose labels required for the training process remains a costly endeavor. While current weakly supervised methods excel in lightweight label generation, their performance notably declines in scenarios with sparse views. In response to this challenge, we introduce WSCLoc, a system capable of being customized to various deep learning-based relocalization models to enhance their performance under weakly-supervised and sparse view conditions. This is realized with two stages. In the initial stage, WSCLoc employs a multilayer perceptron-based structure called WFT-NeRF to co-optimize image reconstruction quality and initial pose information. To ensure a stable learning process, we incorporate temporal information as input. Furthermore, instead of optimizing SE(3), we opt for $\mathfrak{sim}(3)$ optimization to explicitly enforce a scale constraint. In the second stage, we co-optimize the pre-trained WFT-NeRF and WFT-Pose. This optimization is enhanced by Time-Encoding based Random View Synthesis and supervised by inter-frame geometric constraints that consider pose, depth, and RGB information. We validate our approaches on two publicly available datasets, one outdoor and one indoor. Our experimental results demonstrate that our weakly-supervised relocalization solutions achieve superior pose estimation accuracy in sparse-view scenarios, comparable to state-of-the-art camera relocalization methods. We will make our code publicly available.
Fair Classifiers Without Fair Training: An Influence-Guided Data Sampling Approach
Feb 20, 2024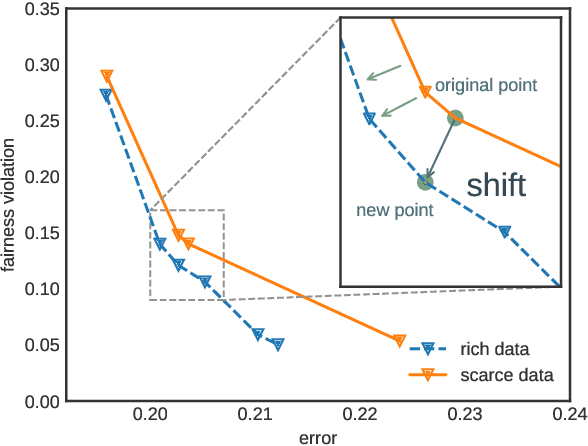
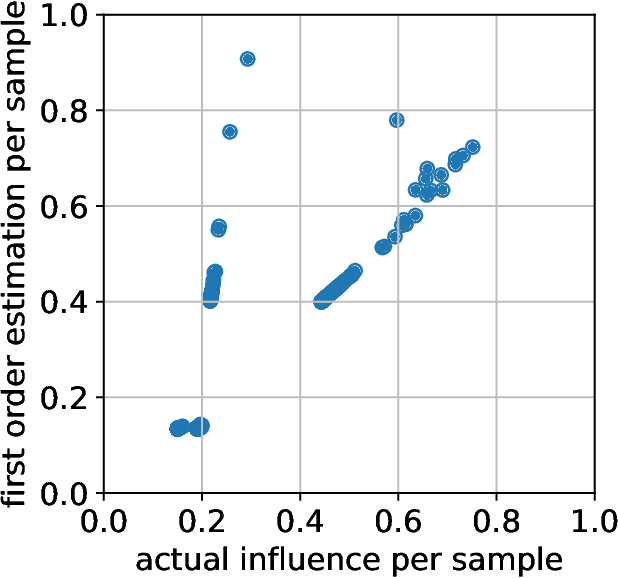
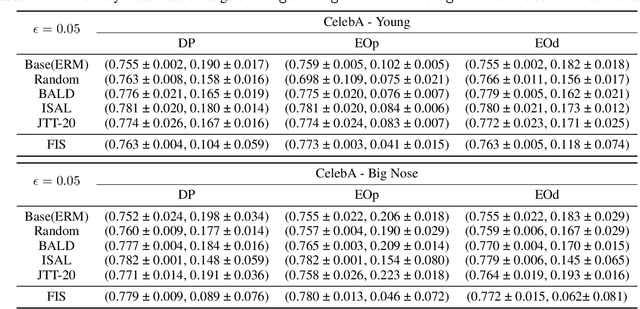
A fair classifier should ensure the benefit of people from different groups, while the group information is often sensitive and unsuitable for model training. Therefore, learning a fair classifier but excluding sensitive attributes in the training dataset is important. In this paper, we study learning fair classifiers without implementing fair training algorithms to avoid possible leakage of sensitive information. Our theoretical analyses validate the possibility of this approach, that traditional training on a dataset with an appropriate distribution shift can reduce both the upper bound for fairness disparity and model generalization error, indicating that fairness and accuracy can be improved simultaneously with simply traditional training. We then propose a tractable solution to progressively shift the original training data during training by sampling influential data, where the sensitive attribute of new data is not accessed in sampling or used in training. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.
Unmasking and Improving Data Credibility: A Study with Datasets for Training Harmless Language Models
Nov 19, 2023



Language models have shown promise in various tasks but can be affected by undesired data during training, fine-tuning, or alignment. For example, if some unsafe conversations are wrongly annotated as safe ones, the model fine-tuned on these samples may be harmful. Therefore, the correctness of annotations, i.e., the credibility of the dataset, is important. This study focuses on the credibility of real-world datasets, including the popular benchmarks Jigsaw Civil Comments, Anthropic Harmless & Red Team, PKU BeaverTails & SafeRLHF, that can be used for training a harmless language model. Given the cost and difficulty of cleaning these datasets by humans, we introduce a systematic framework for evaluating the credibility of datasets, identifying label errors, and evaluating the influence of noisy labels in the curated language data, specifically focusing on unsafe comments and conversation classification. With the framework, we find and fix an average of 6.16% label errors in 11 datasets constructed from the above benchmarks. The data credibility and downstream learning performance can be remarkably improved by directly fixing label errors, indicating the significance of cleaning existing real-world datasets. Open-source: https://github.com/Docta-ai/docta.
T2IAT: Measuring Valence and Stereotypical Biases in Text-to-Image Generation
Jun 01, 2023



Warning: This paper contains several contents that may be toxic, harmful, or offensive. In the last few years, text-to-image generative models have gained remarkable success in generating images with unprecedented quality accompanied by a breakthrough of inference speed. Despite their rapid progress, human biases that manifest in the training examples, particularly with regard to common stereotypical biases, like gender and skin tone, still have been found in these generative models. In this work, we seek to measure more complex human biases exist in the task of text-to-image generations. Inspired by the well-known Implicit Association Test (IAT) from social psychology, we propose a novel Text-to-Image Association Test (T2IAT) framework that quantifies the implicit stereotypes between concepts and valence, and those in the images. We replicate the previously documented bias tests on generative models, including morally neutral tests on flowers and insects as well as demographic stereotypical tests on diverse social attributes. The results of these experiments demonstrate the presence of complex stereotypical behaviors in image generations.
Parameter-Efficient Cross-lingual Transfer of Vision and Language Models via Translation-based Alignment
May 02, 2023



Pre-trained vision and language models such as CLIP have witnessed remarkable success in connecting images and texts with a primary focus on English texts. Despite recent efforts to extend CLIP to support other languages, disparities in performance among different languages have been observed due to uneven resource availability. Additionally, current cross-lingual transfer methods of those pre-trained models would consume excessive resources for a large number of languages. Therefore, we propose a new parameter-efficient cross-lingual transfer learning framework that utilizes a translation-based alignment method to mitigate multilingual disparities and explores parameter-efficient fine-tuning methods for parameter-efficient cross-lingual transfer. Extensive experiments on XTD and Multi30K datasets, covering 11 languages under zero-shot, few-shot, and full-dataset learning scenarios, show that our framework significantly reduces the multilingual disparities among languages and improves cross-lingual transfer results, especially in low-resource scenarios, while only keeping and fine-tuning an extremely small number of parameters compared to the full model (e.g., Our framework only requires 0.16\% additional parameters of a full-model for each language in the few-shot learning scenario).