 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODEBLOCK: Learning to Supervise Code at the Right Granularity
Jun 10, 2026Supervised fine-tuning of code LLMs typically applies uniform cross-entropy loss to all response tokens, implicitly assuming that every token provides equally useful learning signal. Recent token-level selection methods challenge this assumption in natural-language SFT by supervising only high-value tokens. However, directly transferring token-level masking to code can break syntactically and semantically coherent program units, because code depends on structural completeness and definition-use relations. We therefore propose CodeBlock, a structure-aware sparse supervision framework that selects structure-complete code evidence rather than isolated tokens. CodeBlock first selects high-quality instruction-response pairs, then partitions code responses into syntactically coherent coding items, estimates their utility by aggregating generalized cross-entropy over core logic tokens, and reranks them with data-flow reach and bridge signals to prioritize blocks that propagate or connect important program dependencies. During training, the full response remains available as context, while loss is applied only to selected code items and informative natural-language tokens. Experiments on six code-generation benchmarks show that CodeBlock achieves stronger average pass@1 than full-token SFT and competitive selection baselines, while using only 1.9% of supervised response tokens.
Small-Margin Preferences Still Matter-If You Train Them Right
Feb 01, 2026Preference optimization methods such as DPO align large language models (LLMs) using paired comparisons, but their effectiveness can be highly sensitive to the quality and difficulty of preference pairs. A common heuristic treats small-margin (ambiguous) pairs as noisy and filters them out. In this paper, we revisit this assumption and show that pair difficulty interacts strongly with the optimization objective: when trained with preference-based losses, difficult pairs can destabilize training and harm alignment, yet these same pairs still contain useful supervision signals when optimized with supervised fine-tuning (SFT). Motivated by this observation, we propose MixDPO, a simple yet effective difficulty-aware training strategy that (i) orders preference data from easy to hard (a curriculum over margin-defined difficulty), and (ii) routes difficult pairs to an SFT objective while applying a preference loss to easy pairs. This hybrid design provides a practical mechanism to leverage ambiguous pairs without incurring the optimization failures often associated with preference losses on low-margin data. Across three LLM-judge benchmarks, MixDPO consistently improves alignment over DPO and a range of widely-used variants, with particularly strong gains on AlpacaEval~2 length-controlled (LC) win rate.
Evaluating LLM-corrupted Crowdsourcing Data Without Ground Truth
Jun 08, 2025The recent success of generative AI highlights the crucial role of high-quality human feedback in building trustworthy AI systems. However, the increasing use of large language models (LLMs) by crowdsourcing workers poses a significant challenge: datasets intended to reflect human input may be compromised by LLM-generated responses. Existing LLM detection approaches often rely on high-dimension training data such as text, making them unsuitable for annotation tasks like multiple-choice labeling. In this work, we investigate the potential of peer prediction -- a mechanism that evaluates the information within workers' responses without using ground truth -- to mitigate LLM-assisted cheating in crowdsourcing with a focus on annotation tasks. Our approach quantifies the correlations between worker answers while conditioning on (a subset of) LLM-generated labels available to the requester. Building on prior research, we propose a training-free scoring mechanism with theoretical guarantees under a crowdsourcing model that accounts for LLM collusion. We establish conditions under which our method is effective and empirically demonstrate its robustness in detecting low-effort cheating on real-world crowdsourcing datasets.
Token Cleaning: Fine-Grained Data Selection for LLM Supervised Fine-Tuning
Feb 04, 2025



Recent studies show that in supervised fine-tuning (SFT) of large language models (LLMs), data quality matters more than quantity. While most data cleaning methods concentrate on filtering entire samples, the quality of individual tokens within a sample can vary significantly. After pre-training, even in high-quality samples, patterns or phrases that are not task-related can be redundant or uninformative. Continuing to fine-tune on these patterns may offer limited benefit and even degrade downstream task performance. In this paper, we investigate token quality from a noisy-label perspective and propose a generic token cleaning pipeline for SFT tasks. Our method filters out uninformative tokens while preserving those carrying key task-specific information. Specifically, we first evaluate token quality by examining the influence of model updates on each token, then apply a threshold-based separation. The token influence can be measured in a single pass with a fixed reference model or iteratively with self-evolving reference models. The benefits and limitations of both methods are analyzed theoretically by error upper bounds. Extensive experiments show that our framework consistently improves performance across multiple downstream tasks.
LLM Unlearning via Loss Adjustment with Only Forget Data
Oct 14, 2024

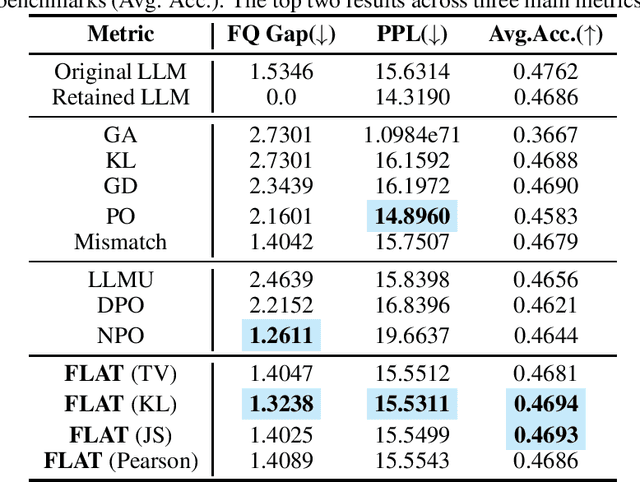
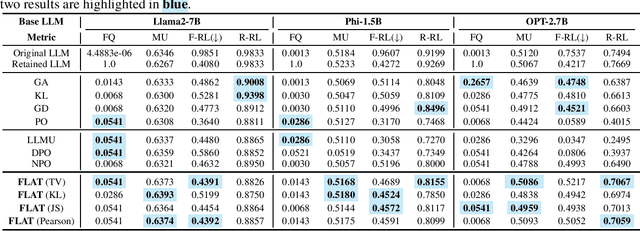
Unlearning in Large Language Models (LLMs) is essential for ensuring ethical and responsible AI use, especially in addressing privacy leak, bias, safety, and evolving regulations. Existing approaches to LLM unlearning often rely on retain data or a reference LLM, yet they struggle to adequately balance unlearning performance with overall model utility. This challenge arises because leveraging explicit retain data or implicit knowledge of retain data from a reference LLM to fine-tune the model tends to blur the boundaries between the forgotten and retain data, as different queries often elicit similar responses. In this work, we propose eliminating the need to retain data or the reference LLM for response calibration in LLM unlearning. Recognizing that directly applying gradient ascent on the forget data often leads to optimization instability and poor performance, our method guides the LLM on what not to respond to, and importantly, how to respond, based on the forget data. Hence, we introduce Forget data only Loss AjustmenT (FLAT), a "flat" loss adjustment approach which addresses these issues by maximizing f-divergence between the available template answer and the forget answer only w.r.t. the forget data. The variational form of the defined f-divergence theoretically provides a way of loss adjustment by assigning different importance weights for the learning w.r.t. template responses and the forgetting of responses subject to unlearning. Empirical results demonstrate that our approach not only achieves superior unlearning performance compared to existing methods but also minimizes the impact on the model's retained capabilities, ensuring high utility across diverse tasks, including copyrighted content unlearning on Harry Potter dataset and MUSE Benchmark, and entity unlearning on the TOFU dataset.
Improving Data Efficiency via Curating LLM-Driven Rating Systems
Oct 09, 2024

Instruction tuning is critical for adapting large language models (LLMs) to downstream tasks, and recent studies have demonstrated that small amounts of human-curated data can outperform larger datasets, challenging traditional data scaling laws. While LLM-based data quality rating systems offer a cost-effective alternative to human annotation, they often suffer from inaccuracies and biases, even in powerful models like GPT-4. In this work, we introduce DS2, a Diversity-aware Score curation method for Data Selection. By systematically modeling error patterns through a score transition matrix, DS2 corrects LLM-based scores and promotes diversity in the selected data samples. Our approach shows that a curated subset (just 3.3% of the original dataset) outperforms full-scale datasets (300k samples) across various machine-alignment benchmarks, and matches or surpasses human-aligned datasets such as LIMA with the same sample size (1k samples). These findings challenge conventional data scaling assumptions, highlighting that redundant, low-quality samples can degrade performance and reaffirming that "more can be less."
Automatic Dataset Construction (ADC): Sample Collection, Data Curation, and Beyond
Aug 21, 2024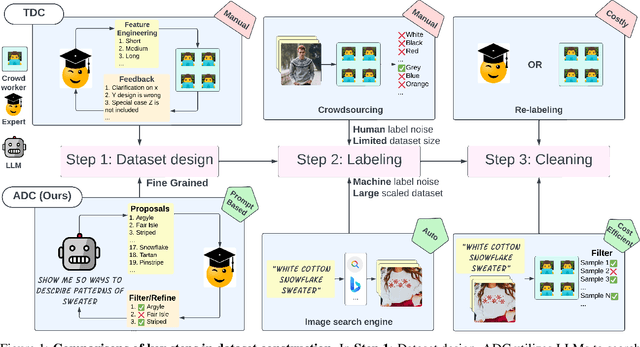

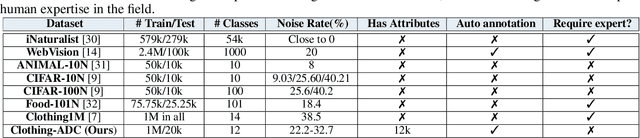
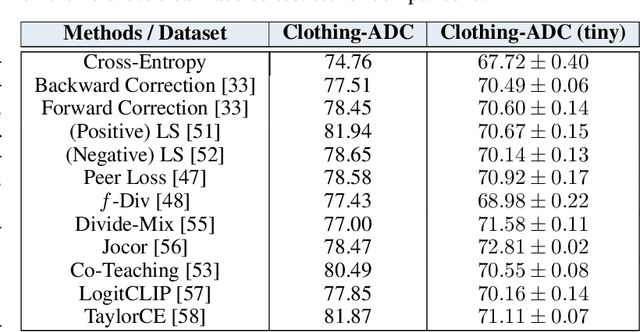
Large-scale data collection is essential for developing personalized training data, mitigating the shortage of training data, and fine-tuning specialized models. However, creating high-quality datasets quickly and accurately remains a challenge due to annotation errors, the substantial time and costs associated with human labor. To address these issues, we propose Automatic Dataset Construction (ADC), an innovative methodology that automates dataset creation with negligible cost and high efficiency. Taking the image classification task as a starting point, ADC leverages LLMs for the detailed class design and code generation to collect relevant samples via search engines, significantly reducing the need for manual annotation and speeding up the data generation process. Despite these advantages, ADC also encounters real-world challenges such as label errors (label noise) and imbalanced data distributions (label bias). We provide open-source software that incorporates existing methods for label error detection, robust learning under noisy and biased data, ensuring a higher-quality training data and more robust model training procedure. Furthermore, we design three benchmark datasets focused on label noise detection, label noise learning, and class-imbalanced learning. These datasets are vital because there are few existing datasets specifically for label noise detection, despite its importance. Finally, we evaluate the performance of existing popular methods on these datasets, thereby facilitating further research in the field.
Fair Classifiers Without Fair Training: An Influence-Guided Data Sampling Approach
Feb 20, 2024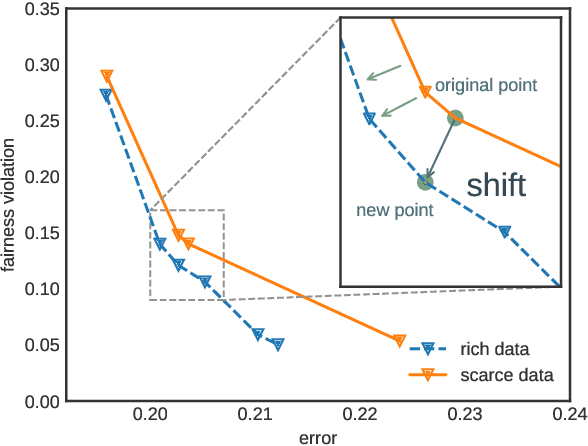
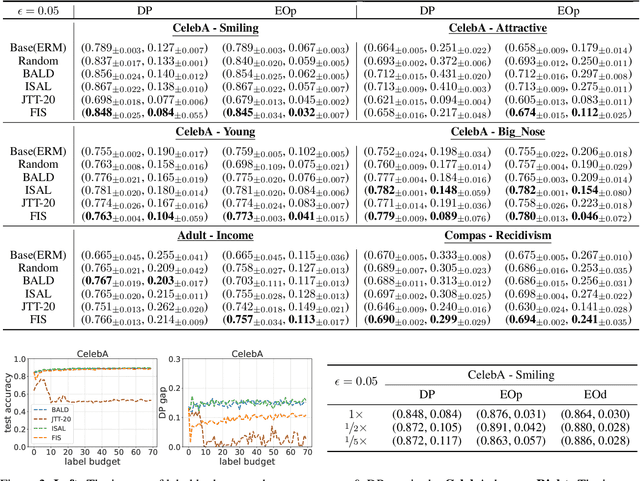
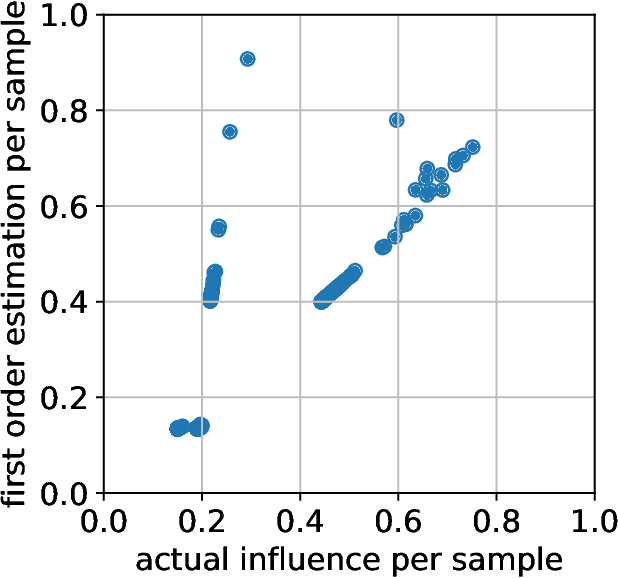
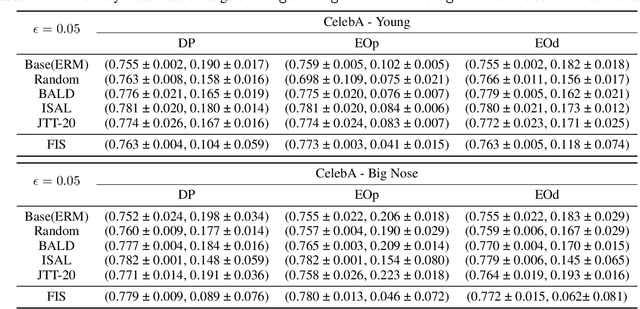
A fair classifier should ensure the benefit of people from different groups, while the group information is often sensitive and unsuitable for model training. Therefore, learning a fair classifier but excluding sensitive attributes in the training dataset is important. In this paper, we study learning fair classifiers without implementing fair training algorithms to avoid possible leakage of sensitive information. Our theoretical analyses validate the possibility of this approach, that traditional training on a dataset with an appropriate distribution shift can reduce both the upper bound for fairness disparity and model generalization error, indicating that fairness and accuracy can be improved simultaneously with simply traditional training. We then propose a tractable solution to progressively shift the original training data during training by sampling influential data, where the sensitive attribute of new data is not accessed in sampling or used in training. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.