 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a Robot Walk the Robotic Dog: Triple-Zero Collaborative Navigation for Heterogeneous Multi-Agent Systems
Mar 23, 2026We present Triple Zero Path Planning (TZPP), a collaborative framework for heterogeneous multi-robot systems that requires zero training, zero prior knowledge, and zero simulation. TZPP employs a coordinator--explorer architecture: a humanoid robot handles task coordination, while a quadruped robot explores and identifies feasible paths using guidance from a multimodal large language model. We implement TZPP on Unitree G1 and Go2 robots and evaluate it across diverse indoor and outdoor environments, including obstacle-rich and landmark-sparse settings. Experiments show that TZPP achieves robust, human-comparable efficiency and strong adaptability to unseen scenarios. By eliminating reliance on training and simulation, TZPP offers a practical path toward real-world deployment of heterogeneous robot cooperation. Our code and video are provided at: https://github.com/triple-zeropp/Triple-zero-robot-agent
HLE-Verified: A Systematic Verification and Structured Revision of Humanity's Last Exam
Feb 17, 2026Humanity's Last Exam (HLE) has become a widely used benchmark for evaluating frontier large language models on challenging, multi-domain questions. However, community-led analyses have raised concerns that HLE contains a non-trivial number of noisy items, which can bias evaluation results and distort cross-model comparisons. To address this challenge, we introduce HLE-Verified, a verified and revised version of HLE with a transparent verification protocol and fine-grained error taxonomy. Our construction follows a two-stage validation-and-repair workflow resulting in a certified benchmark. In Stage I, each item undergoes binary validation of the problem and final answer through domain-expert review and model-based cross-checks, yielding 641 verified items. In Stage II, flawed but fixable items are revised under strict constraints preserving the original evaluation intent, through dual independent expert repairs, model-assisted auditing, and final adjudication, resulting in 1,170 revised-and-certified items. The remaining 689 items are released as a documented uncertain set with explicit uncertainty sources and expertise tags for future refinement. We evaluate seven state-of-the-art language models on HLE and HLE-Verified, observing an average absolute accuracy gain of 7--10 percentage points on HLE-Verified. The improvement is particularly pronounced on items where the original problem statement and/or reference answer is erroneous, with gains of 30--40 percentage points. Our analyses further reveal a strong association between model confidence and the presence of errors in the problem statement or reference answer, supporting the effectiveness of our revisions. Overall, HLE-Verified improves HLE-style evaluations by reducing annotation noise and enabling more faithful measurement of model capabilities. Data is available at: https://github.com/SKYLENAGE-AI/HLE-Verified
AgentRob: From Virtual Forum Agents to Hijacked Physical Robots
Feb 14, 2026Large Language Model (LLM)-powered autonomous agents have demonstrated significant capabilities in virtual environments, yet their integration with the physical world remains narrowly confined to direct control interfaces. We present AgentRob, a framework that bridges online community forums, LLM-powered agents, and physical robots through the Model Context Protocol (MCP). AgentRob enables a novel paradigm where autonomous agents participate in online forums--reading posts, extracting natural language commands, dispatching physical robot actions, and reporting results back to the community. The system comprises three layers: a Forum Layer providing asynchronous, persistent, multi-agent interaction; an Agent Layer with forum agents that poll for @mention-targeted commands; and a Robot Layer with VLM-driven controllers and Unitree Go2/G1 hardware that translate commands into robot primitives via iterative tool calling. The framework supports multiple concurrent agents with distinct identities and physical embodiments coexisting in the same forum, establishing the feasibility of forum-mediated multi-agent robot orchestration.
Small-Margin Preferences Still Matter-If You Train Them Right
Feb 01, 2026Preference optimization methods such as DPO align large language models (LLMs) using paired comparisons, but their effectiveness can be highly sensitive to the quality and difficulty of preference pairs. A common heuristic treats small-margin (ambiguous) pairs as noisy and filters them out. In this paper, we revisit this assumption and show that pair difficulty interacts strongly with the optimization objective: when trained with preference-based losses, difficult pairs can destabilize training and harm alignment, yet these same pairs still contain useful supervision signals when optimized with supervised fine-tuning (SFT). Motivated by this observation, we propose MixDPO, a simple yet effective difficulty-aware training strategy that (i) orders preference data from easy to hard (a curriculum over margin-defined difficulty), and (ii) routes difficult pairs to an SFT objective while applying a preference loss to easy pairs. This hybrid design provides a practical mechanism to leverage ambiguous pairs without incurring the optimization failures often associated with preference losses on low-margin data. Across three LLM-judge benchmarks, MixDPO consistently improves alignment over DPO and a range of widely-used variants, with particularly strong gains on AlpacaEval~2 length-controlled (LC) win rate.
Unmasking Reasoning Processes: A Process-aware Benchmark for Evaluating Structural Mathematical Reasoning in LLMs
Jan 31, 2026Recent large language models (LLMs) achieve near-saturation accuracy on many established mathematical reasoning benchmarks, raising concerns about their ability to diagnose genuine reasoning competence. This saturation largely stems from the dominance of template-based computation and shallow arithmetic decomposition in existing datasets, which underrepresent reasoning skills such as multi-constraint coordination, constructive logical synthesis, and spatial inference. To address this gap, we introduce ReasoningMath-Plus, a benchmark of 150 carefully curated problems explicitly designed to evaluate structural reasoning. Each problem emphasizes reasoning under interacting constraints, constructive solution formation, or non-trivial structural insight, and is annotated with a minimal reasoning skeleton to support fine-grained process-level evaluation. Alongside the dataset, we introduce HCRS (Hazard-aware Chain-based Rule Score), a deterministic step-level scoring function, and train a Process Reward Model (PRM) on the annotated reasoning traces. Empirically, while leading models attain relatively high final-answer accuracy (up to 5.8/10), HCRS-based holistic evaluation yields substantially lower scores (average 4.36/10, best 5.14/10), showing that answer-only metrics can overestimate reasoning robustness.
Observations and Remedies for Large Language Model Bias in Self-Consuming Performative Loop
Jan 08, 2026The rapid advancement of large language models (LLMs) has led to growing interest in using synthetic data to train future models. However, this creates a self-consuming retraining loop, where models are trained on their own outputs and may cause performance drops and induce emerging biases. In real-world applications, previously deployed LLMs may influence the data they generate, leading to a dynamic system driven by user feedback. For example, if a model continues to underserve users from a group, less query data will be collected from this particular demographic of users. In this study, we introduce the concept of \textbf{S}elf-\textbf{C}onsuming \textbf{P}erformative \textbf{L}oop (\textbf{SCPL}) and investigate the role of synthetic data in shaping bias during these dynamic iterative training processes under controlled performative feedback. This controlled setting is motivated by the inaccessibility of real-world user preference data from dynamic production systems, and enables us to isolate and analyze feedback-driven bias evolution in a principled manner. We focus on two types of loops, including the typical retraining setting and the incremental fine-tuning setting, which is largely underexplored. Through experiments on three real-world tasks, we find that the performative loop increases preference bias and decreases disparate bias. We design a reward-based rejection sampling strategy to mitigate the bias, moving towards more trustworthy self-improving systems.
Stabilizing Self-Consuming Diffusion Models with Latent Space Filtering
Nov 16, 2025As synthetic data proliferates across the Internet, it is often reused to train successive generations of generative models. This creates a ``self-consuming loop" that can lead to training instability or \textit{model collapse}. Common strategies to address the issue -- such as accumulating historical training data or injecting fresh real data -- either increase computational cost or require expensive human annotation. In this paper, we empirically analyze the latent space dynamics of self-consuming diffusion models and observe that the low-dimensional structure of latent representations extracted from synthetic data degrade over generations. Based on this insight, we propose \textit{Latent Space Filtering} (LSF), a novel approach that mitigates model collapse by filtering out less realistic synthetic data from mixed datasets. Theoretically, we present a framework that connects latent space degradation to empirical observations. Experimentally, we show that LSF consistently outperforms existing baselines across multiple real-world datasets, effectively mitigating model collapse without increasing training cost or relying on human annotation.
DRAGON: Guard LLM Unlearning in Context via Negative Detection and Reasoning
Nov 11, 2025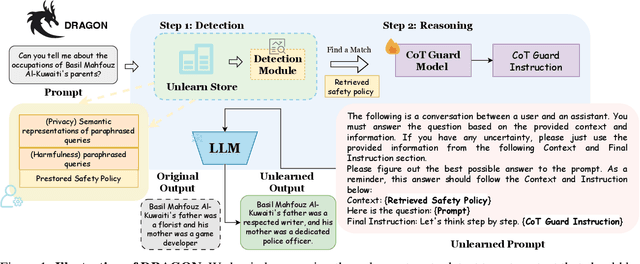
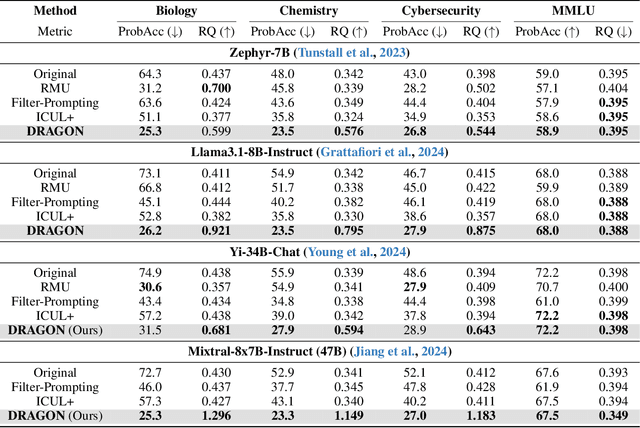
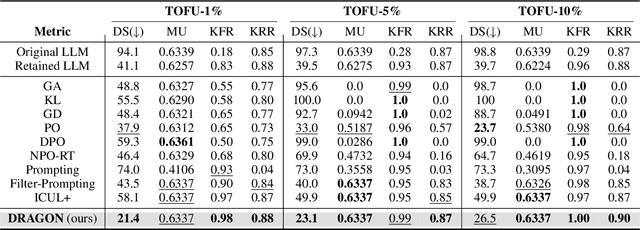
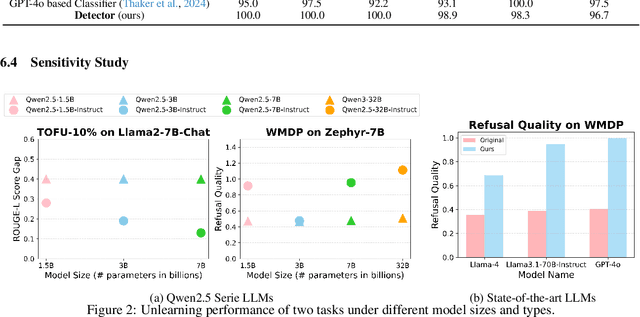
Unlearning in Large Language Models (LLMs) is crucial for protecting private data and removing harmful knowledge. Most existing approaches rely on fine-tuning to balance unlearning efficiency with general language capabilities. However, these methods typically require training or access to retain data, which is often unavailable in real world scenarios. Although these methods can perform well when both forget and retain data are available, few works have demonstrated equivalent capability in more practical, data-limited scenarios. To overcome these limitations, we propose Detect-Reasoning Augmented GeneratiON (DRAGON), a systematic, reasoning-based framework that utilizes in-context chain-of-thought (CoT) instructions to guard deployed LLMs before inference. Instead of modifying the base model, DRAGON leverages the inherent instruction-following ability of LLMs and introduces a lightweight detection module to identify forget-worthy prompts without any retain data. These are then routed through a dedicated CoT guard model to enforce safe and accurate in-context intervention. To robustly evaluate unlearning performance, we introduce novel metrics for unlearning performance and the continual unlearning setting. Extensive experiments across three representative unlearning tasks validate the effectiveness of DRAGON, demonstrating its strong unlearning capability, scalability, and applicability in practical scenarios.
Beluga Whale Detection from Satellite Imagery with Point Labels
May 17, 2025



Very high-resolution (VHR) satellite imagery has emerged as a powerful tool for monitoring marine animals on a large scale. However, existing deep learning-based whale detection methods usually require manually created, high-quality bounding box annotations, which are labor-intensive to produce. Moreover, existing studies often exclude ``uncertain whales'', individuals that have ambiguous appearances in satellite imagery, limiting the applicability of these models in real-world scenarios. To address these limitations, this study introduces an automated pipeline for detecting beluga whales and harp seals in VHR satellite imagery. The pipeline leverages point annotations and the Segment Anything Model (SAM) to generate precise bounding box annotations, which are used to train YOLOv8 for multiclass detection of certain whales, uncertain whales, and harp seals. Experimental results demonstrated that SAM-generated annotations significantly improved detection performance, achieving higher $\text{F}_\text{1}$-scores compared to traditional buffer-based annotations. YOLOv8 trained on SAM-labeled boxes achieved an overall $\text{F}_\text{1}$-score of 72.2% for whales overall and 70.3% for harp seals, with superior performance in dense scenes. The proposed approach not only reduces the manual effort required for annotation but also enhances the detection of uncertain whales, offering a more comprehensive solution for marine animal monitoring. This method holds great potential for extending to other species, habitats, and remote sensing platforms, as well as for estimating whale biometrics, thereby advancing ecological monitoring and conservation efforts. The codes for our label and detection pipeline are publicly available at http://github.com/voyagerxvoyagerx/beluga-seeker .
Noise-Resilient Point-wise Anomaly Detection in Time Series Using Weak Segment Labels
Jan 21, 2025



Detecting anomalies in temporal data has gained significant attention across various real-world applications, aiming to identify unusual events and mitigate potential hazards. In practice, situations often involve a mix of segment-level labels (detected abnormal events with segments of time points) and unlabeled data (undetected events), while the ideal algorithmic outcome should be point-level predictions. Therefore, the huge label information gap between training data and targets makes the task challenging. In this study, we formulate the above imperfect information as noisy labels and propose NRdetector, a noise-resilient framework that incorporates confidence-based sample selection, robust segment-level learning, and data-centric point-level detection for multivariate time series anomaly detection. Particularly, to bridge the information gap between noisy segment-level labels and missing point-level labels, we develop a novel loss function that can effectively mitigate the label noise and consider the temporal features. It encourages the smoothness of consecutive points and the separability of points from segments with different labels. Extensive experiments on real-world multivariate time series datasets with 11 different evaluation metrics demonstrate that NRdetector consistently achieves robust results across multiple real-world datasets, outperforming various baselines adapted to operate in our setting.