 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSGuard: A Benchmark for Safety in Computer-Use Agents
Jun 13, 2026Computer-use agents are increasingly evaluated by whether they complete realistic desktop and web tasks. However, task success alone can miss failures in which an agent reaches the nominal goal through an unsafe shortcut. We introduce OSGuard, a dual-granularity benchmark suite for evaluating safety in computer-use agents under benign, unchanged user instructions. OSGuard contains an action-level benchmark for local guardrail decisions and a risk-augmented execution suite for end-to-end evaluation. The action-level benchmark consists of contextualized proposed actions labeled as allowed, unrelated, or unsafe, each judged relative to the original instruction and current interface state. The execution suite contains manually constructed OSWorld-derived task variants in which the original task remains achievable, but the environment is modified to introduce latent hazards such as destructive overwrites, etc. Each variant is paired with augmented evaluators that retain the original task-success criterion while adding explicit state-based safety invariants, allowing us to distinguish safe completions from unsafe completions that satisfy the nominal task objective. Our experimental results on OSGuard show that current multimodal guardrails can perform well on isolated action judgments, while risk-augmented execution exposes remaining gaps between local oversight and reliable end-to-end safety. This dual-granularity design enables more precise diagnosis of whether models can both recognize unsafe proposed actions and improve full-task safety when deployed as guardrails.
Right or Wrong, Models Comply: Directional Blindness in LLM Moral Judgment
Jun 12, 2026As language models take integrated roles across many domains, the response of LLMs to user pushback becomes a critical alignment property. Yet many existing evaluations treat compliance as unidirectional, measuring whether models resist pressure but not whether they resist it selectively. We introduce Compliance Asymmetry (A = BCR/HCR), a bidirectional diagnostic that compares beneficial output change under helpful nudges with harmful change under misleading nudges. Across 9 models and 972,000 nudge-condition responses, we find that this selectivity differs in factual and moral judgments: models follow helpful nudges more than harmful ones on factual questions (A = 1.58), but follow both directions at nearly identical rates on moral questions (A = 1.04). This phenomenon persists across model families, capability levels, and nudging types. Interestingly, we also find that chain-of-thought prompting amplifies helpful and harmful compliance together, while identity-based prompting suppresses both by nearly identical margins. These results identify direction-blind moral compliance as a distinct failure mode in current LLMs and suggest that alignment should target directionally calibrated updating rather than lower compliance alone.
Dialogue SWE-Bench: A Benchmark for Dialogue-Driven Coding Agents
Jun 12, 2026AI coding agents have rapidly transformed software engineering, powering widely used interactive coding assistants. Despite their interactive real-world use, existing benchmarks evaluate them as fully-autonomous systems. In this work, we introduce Dialogue SWE-Bench, an automatic benchmark dataset for evaluating the ability of coding agents to resolve real-world software engineering problems through dialogue with a user. We design a novel, persona-grounded user simulator to support our task evaluation, and augment our task evaluation with automatic evaluations of dialogue quality. We also propose a new schema-guided agent, aimed at improving the dialogue capabilities of off-the-shelf coding agents, which improves over strong baselines by 3-14%. Our results indicate that better coding models do not always correspond to better dialogue models, suggesting that dialogue capability is a distinct and currently understudied dimension of coding agent performance.
MathAtlas: A Benchmark for Autoformalization in the Wild
May 13, 2026Current autoformalization benchmarks are largely focused on olympiad or undergraduate mathematics, while graduate and research-level mathematics remains underexplored. In this paper, we introduce MathAtlas, the first large-scale autoformalization benchmark of in the wild graduate-level mathematics, containing ~52k theorems, definitions, exercises, examples, and proofs extracted from 103 graduate mathematics textbooks. MathAtlas is enriched with a mathematical dependency graph containing ~178k relations, and is the first autoformalization benchmark to include such relations, facilitating evaluation and development of dependency-aware autoformalization systems. Our extensive experiments show that MathAtlas is high quality but extremely challenging: strong baselines achieve at most 9.8% correctness on theorem statements and 16.7% on definitions. Furthermore, we find performance of state-of-the-art models degrades substantially with dependency depth: on MA-Hard, a subset of 700 entities with the deepest dependency trees, the best model achieves only 2.6% correctness for autoformalization on this challenging dataset. We release MathAtlas to the community as a benchmark set for large-scale autoformalization of graduate-level mathematics in the wild.
Prompt, Translate, Fine-Tune, Re-Initialize, or Instruction-Tune? Adapting LLMs for In-Context Learning in Low-Resource Languages
Jun 23, 2025



LLMs are typically trained in high-resource languages, and tasks in lower-resourced languages tend to underperform the higher-resource language counterparts for in-context learning. Despite the large body of work on prompting settings, it is still unclear how LLMs should be adapted cross-lingually specifically for in-context learning in the low-resource target languages. We perform a comprehensive study spanning five diverse target languages, three base LLMs, and seven downstream tasks spanning over 4,100 GPU training hours (9,900+ TFLOPs) across various adaptation techniques: few-shot prompting, translate-test, fine-tuning, embedding re-initialization, and instruction fine-tuning. Our results show that the few-shot prompting and translate-test settings tend to heavily outperform the gradient-based adaptation methods. To better understand this discrepancy, we design a novel metric, Valid Output Recall (VOR), and analyze model outputs to empirically attribute the degradation of these trained models to catastrophic forgetting. To the extent of our knowledge, this is the largest study done on in-context learning for low-resource languages with respect to train compute and number of adaptation techniques considered. We make all our datasets and trained models available for public use.
RAC: Efficient LLM Factuality Correction with Retrieval Augmentation
Oct 21, 2024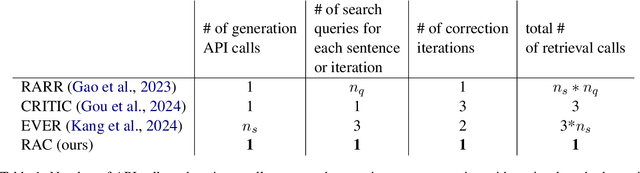
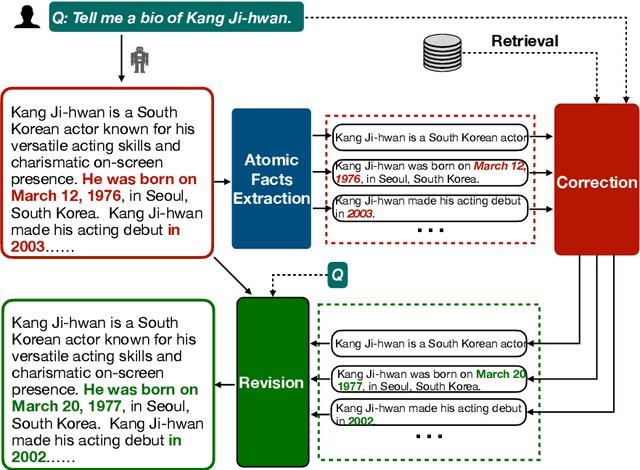
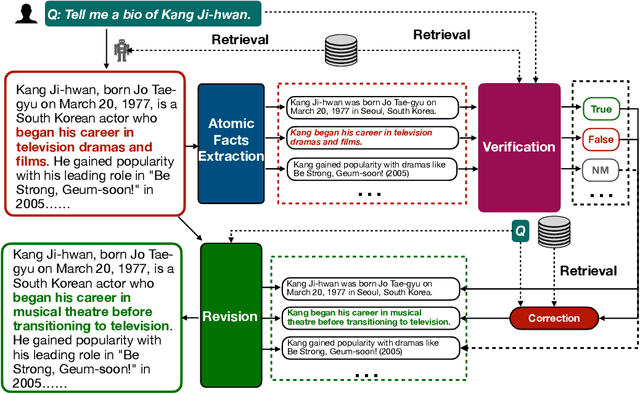

Large Language Models (LLMs) exhibit impressive results across a wide range of natural language processing (NLP) tasks, yet they can often produce factually incorrect outputs. This paper introduces a simple but effective low-latency post-correction method, \textbf{Retrieval Augmented Correction (RAC)}, aimed at enhancing the factual performance of LLMs without requiring additional fine-tuning. Our method is general and can be used with any instruction-tuned LLM, and has greatly reduced latency compared to prior approaches. RAC decomposes the LLM's output into atomic facts and applies a fine-grained verification and correction process with retrieved content to verify and correct the LLM-generated output. Our extensive experiments show that RAC yields up to 30\% improvements over state-of-the-art baselines across two popular factuality evaluation datasets, validating its efficacy and robustness in both with and without the integration of Retrieval-Augmented Generation (RAG) across different LLMs.\footnote{Our code is at \url{https://github.com/jlab-nlp/Retrieval-Augmented-Correction}}
Large Language Model Unlearning via Embedding-Corrupted Prompts
Jun 12, 2024



Large language models (LLMs) have advanced to encompass extensive knowledge across diverse domains. Yet controlling what a large language model should not know is important for ensuring alignment and thus safe use. However, accurately and efficiently unlearning knowledge from an LLM remains challenging due to the potential collateral damage caused by the fuzzy boundary between retention and forgetting, and the large computational requirements for optimization across state-of-the-art models with hundreds of billions of parameters. In this work, we present Embedding-COrrupted (ECO) Prompts, a lightweight unlearning framework for large language models to address both the challenges of knowledge entanglement and unlearning efficiency. Instead of relying on the LLM itself to unlearn, we enforce an unlearned state during inference by employing a prompt classifier to identify and safeguard prompts to forget. We learn corruptions added to prompt embeddings via zeroth order optimization toward the unlearning objective offline and corrupt prompts flagged by the classifier during inference. We find that these embedding-corrupted prompts not only lead to desirable outputs that satisfy the unlearning objective but also closely approximate the output from a model that has never been trained on the data intended for forgetting. Through extensive experiments on unlearning, we demonstrate the superiority of our method in achieving promising unlearning at nearly zero side effects in general domains and domains closely related to the unlearned ones. Additionally, we highlight the scalability of our method to 100 LLMs, ranging from 0.5B to 236B parameters, incurring no additional cost as the number of parameters increases.
The Power of the Noisy Channel: Unsupervised End-to-End Task-Oriented Dialogue with LLMs
Apr 23, 2024



Training task-oriented dialogue systems typically requires turn-level annotations for interacting with their APIs: e.g. a dialogue state and the system actions taken at each step. These annotations can be costly to produce, error-prone, and require both domain and annotation expertise. With advances in LLMs, we hypothesize unlabelled data and a schema definition are sufficient for building a working task-oriented dialogue system, completely unsupervised. Using only (1) a well-defined API schema (2) a set of unlabelled dialogues between a user and agent, we develop a novel approach for inferring turn-level annotations as latent variables using a noisy channel model. We iteratively improve these pseudo-labels with expectation-maximization (EM), and use the inferred labels to train an end-to-end dialogue agent. Evaluating our approach on the MultiWOZ benchmark, our method more than doubles the dialogue success rate of a strong GPT-3.5 baseline.
Future Language Modeling from Temporal Document History
Apr 16, 2024Predicting the future is of great interest across many aspects of human activity. Businesses are interested in future trends, traders are interested in future stock prices, and companies are highly interested in future technological breakthroughs. While there are many automated systems for predicting future numerical data, such as weather, stock prices, and demand for products, there is relatively little work in automatically predicting textual data. Humans are interested in textual data predictions because it is a natural format for our consumption, and experts routinely make predictions in a textual format (Christensen et al., 2004; Tetlock & Gardner, 2015; Frick, 2015). However, there has been relatively little formalization of this general problem in the machine learning or natural language processing communities. To address this gap, we introduce the task of future language modeling: probabilistic modeling of texts in the future based on a temporal history of texts. To our knowledge, our work is the first work to formalize the task of predicting the future in this way. We show that it is indeed possible to build future language models that improve upon strong non-temporal language model baselines, opening the door to working on this important, and widely applicable problem.
Task Contamination: Language Models May Not Be Few-Shot Anymore
Dec 26, 2023
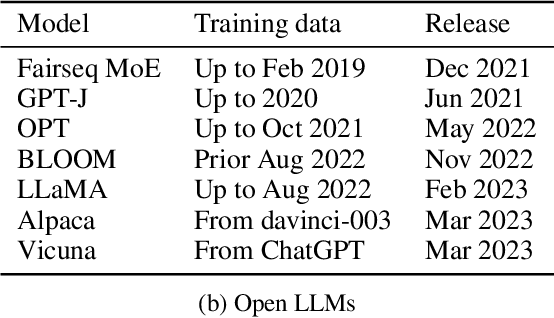


Large language models (LLMs) offer impressive performance in various zero-shot and few-shot tasks. However, their success in zero-shot and few-shot settings may be affected by task contamination, a potential limitation that has not been thoroughly examined. This paper investigates how zero-shot and few-shot performance of LLMs has changed chronologically over time. Utilizing GPT-3 series models and several other recent open-sourced LLMs, and controlling for dataset difficulty, we find that on datasets released before the LLM training data creation date, LLMs perform surprisingly better than on datasets released after. This strongly indicates that, for many LLMs, there exists task contamination on zero-shot and few-shot evaluation for datasets released prior to the LLMs' training data creation date. Additionally, we utilize training data inspection, task example extraction, and a membership inference attack, which reveal further evidence of task contamination. Importantly, we find that for classification tasks with no possibility of task contamination, LLMs rarely demonstrate statistically significant improvements over simple majority baselines, in both zero and few-shot settings.