 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-scale Dataset for Robust Complex Anime Scene Text Detection
Oct 09, 2025Current text detection datasets primarily target natural or document scenes, where text typically appear in regular font and shapes, monotonous colors, and orderly layouts. The text usually arranged along straight or curved lines. However, these characteristics differ significantly from anime scenes, where text is often diverse in style, irregularly arranged, and easily confused with complex visual elements such as symbols and decorative patterns. Text in anime scene also includes a large number of handwritten and stylized fonts. Motivated by this gap, we introduce AnimeText, a large-scale dataset containing 735K images and 4.2M annotated text blocks. It features hierarchical annotations and hard negative samples tailored for anime scenarios. %Cross-dataset evaluations using state-of-the-art methods demonstrate that models trained on AnimeText achieve superior performance in anime text detection tasks compared to existing datasets. To evaluate the robustness of AnimeText in complex anime scenes, we conducted cross-dataset benchmarking using state-of-the-art text detection methods. Experimental results demonstrate that models trained on AnimeText outperform those trained on existing datasets in anime scene text detection tasks. AnimeText on HuggingFace: https://huggingface.co/datasets/deepghs/AnimeText
RAC: Efficient LLM Factuality Correction with Retrieval Augmentation
Oct 21, 2024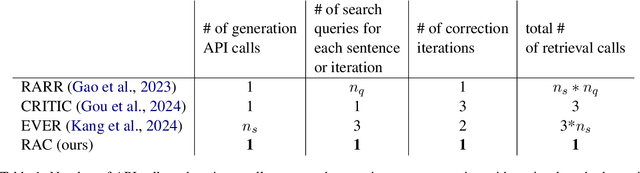
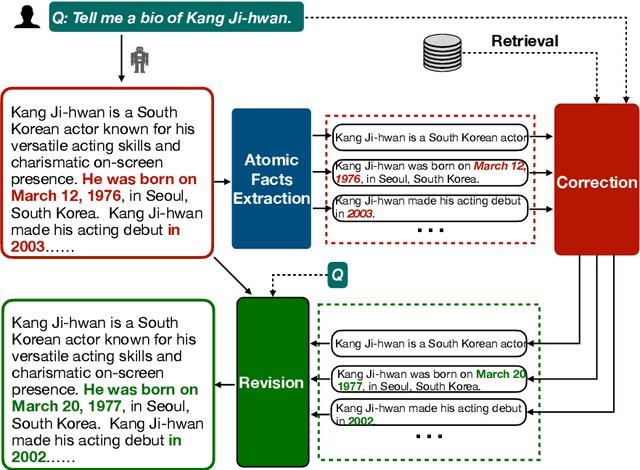
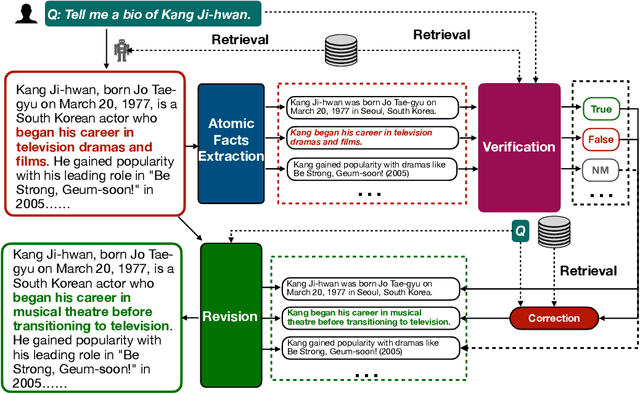

Large Language Models (LLMs) exhibit impressive results across a wide range of natural language processing (NLP) tasks, yet they can often produce factually incorrect outputs. This paper introduces a simple but effective low-latency post-correction method, \textbf{Retrieval Augmented Correction (RAC)}, aimed at enhancing the factual performance of LLMs without requiring additional fine-tuning. Our method is general and can be used with any instruction-tuned LLM, and has greatly reduced latency compared to prior approaches. RAC decomposes the LLM's output into atomic facts and applies a fine-grained verification and correction process with retrieved content to verify and correct the LLM-generated output. Our extensive experiments show that RAC yields up to 30\% improvements over state-of-the-art baselines across two popular factuality evaluation datasets, validating its efficacy and robustness in both with and without the integration of Retrieval-Augmented Generation (RAG) across different LLMs.\footnote{Our code is at \url{https://github.com/jlab-nlp/Retrieval-Augmented-Correction}}
Future Language Modeling from Temporal Document History
Apr 16, 2024Predicting the future is of great interest across many aspects of human activity. Businesses are interested in future trends, traders are interested in future stock prices, and companies are highly interested in future technological breakthroughs. While there are many automated systems for predicting future numerical data, such as weather, stock prices, and demand for products, there is relatively little work in automatically predicting textual data. Humans are interested in textual data predictions because it is a natural format for our consumption, and experts routinely make predictions in a textual format (Christensen et al., 2004; Tetlock & Gardner, 2015; Frick, 2015). However, there has been relatively little formalization of this general problem in the machine learning or natural language processing communities. To address this gap, we introduce the task of future language modeling: probabilistic modeling of texts in the future based on a temporal history of texts. To our knowledge, our work is the first work to formalize the task of predicting the future in this way. We show that it is indeed possible to build future language models that improve upon strong non-temporal language model baselines, opening the door to working on this important, and widely applicable problem.
Task Contamination: Language Models May Not Be Few-Shot Anymore
Dec 26, 2023Large language models (LLMs) offer impressive performance in various zero-shot and few-shot tasks. However, their success in zero-shot and few-shot settings may be affected by task contamination, a potential limitation that has not been thoroughly examined. This paper investigates how zero-shot and few-shot performance of LLMs has changed chronologically over time. Utilizing GPT-3 series models and several other recent open-sourced LLMs, and controlling for dataset difficulty, we find that on datasets released before the LLM training data creation date, LLMs perform surprisingly better than on datasets released after. This strongly indicates that, for many LLMs, there exists task contamination on zero-shot and few-shot evaluation for datasets released prior to the LLMs' training data creation date. Additionally, we utilize training data inspection, task example extraction, and a membership inference attack, which reveal further evidence of task contamination. Importantly, we find that for classification tasks with no possibility of task contamination, LLMs rarely demonstrate statistically significant improvements over simple majority baselines, in both zero and few-shot settings.
Competence-Level Prediction and Resume & Job Description Matching Using Context-Aware Transformer Models
Nov 05, 2020
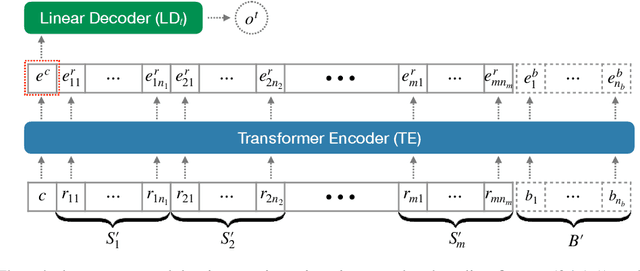
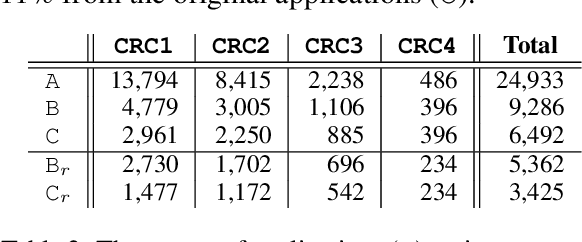
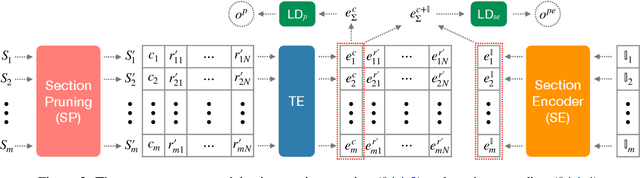
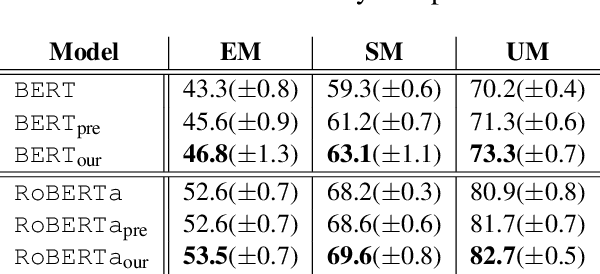
This paper presents a comprehensive study on resume classification to reduce the time and labor needed to screen an overwhelming number of applications significantly, while improving the selection of suitable candidates. A total of 6,492 resumes are extracted from 24,933 job applications for 252 positions designated into four levels of experience for Clinical Research Coordinators (CRC). Each resume is manually annotated to its most appropriate CRC position by experts through several rounds of triple annotation to establish guidelines. As a result, a high Kappa score of 61% is achieved for inter-annotator agreement. Given this dataset, novel transformer-based classification models are developed for two tasks: the first task takes a resume and classifies it to a CRC level (T1), and the second task takes both a resume and a job description to apply and predicts if the application is suited to the job T2. Our best models using section encoding and multi-head attention decoding give results of 73.3% to T1 and 79.2% to T2. Our analysis shows that the prediction errors are mostly made among adjacent CRC levels, which are hard for even experts to distinguish, implying the practical value of our models in real HR platforms.
Transformer-based Context-aware Sarcasm Detection in Conversation Threads from Social Media
May 22, 2020

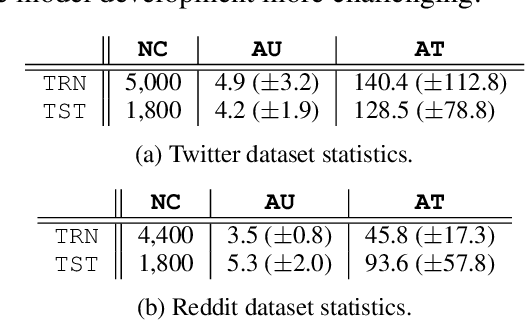

We present a transformer-based sarcasm detection model that accounts for the context from the entire conversation thread for more robust predictions. Our model uses deep transformer layers to perform multi-head attentions among the target utterance and the relevant context in the thread. The context-aware models are evaluated on two datasets from social media, Twitter and Reddit, and show 3.1% and 7.0% improvements over their baselines. Our best models give the F1-scores of 79.0% and 75.0% for the Twitter and Reddit datasets respectively, becoming one of the highest performing systems among 36 participants in this shared task.
Transformers to Learn Hierarchical Contexts in Multiparty Dialogue for Span-based Question Answering
Apr 07, 2020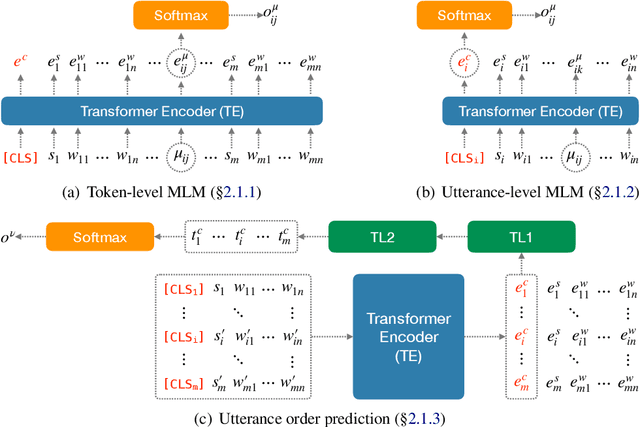

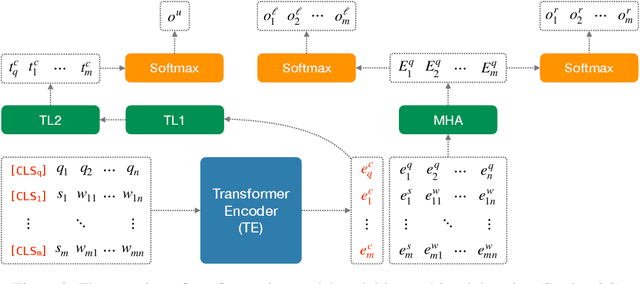
We introduce a novel approach to transformers that learns hierarchical representations in multiparty dialogue. First, three language modeling tasks are used to pre-train the transformers, token- and utterance-level language modeling and utterance order prediction, that learn both token and utterance embeddings for better understanding in dialogue contexts. Then, multi-task learning between the utterance prediction and the token span prediction is applied to fine-tune for span-based question answering (QA). Our approach is evaluated on the FriendsQA dataset and shows improvements of 3.8% and 1.4% over the two state-of-the-art transformer models, BERT and RoBERTa, respectively.
Challenging On Car Racing Problem from OpenAI gym
Nov 02, 2019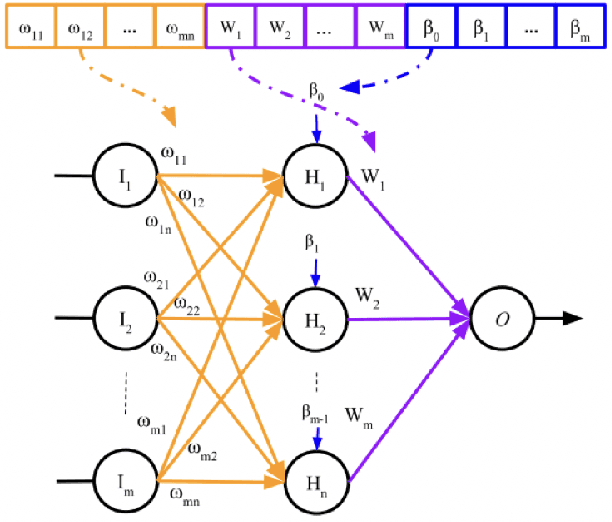
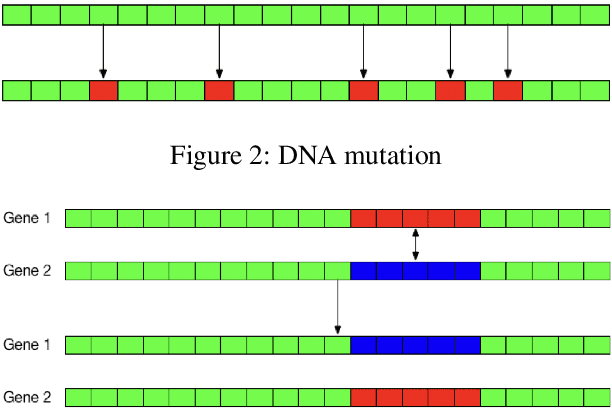
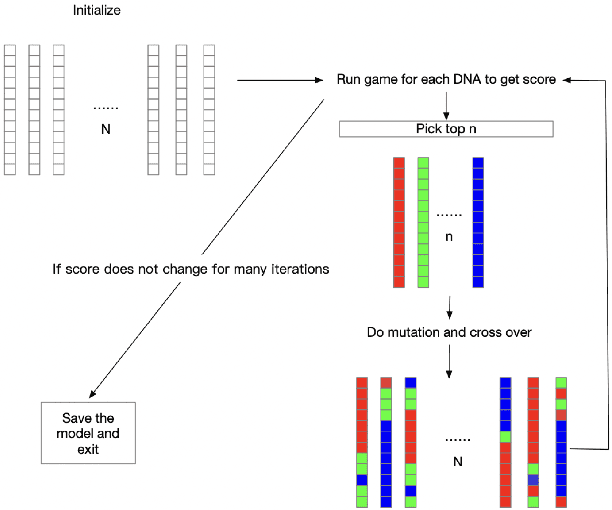
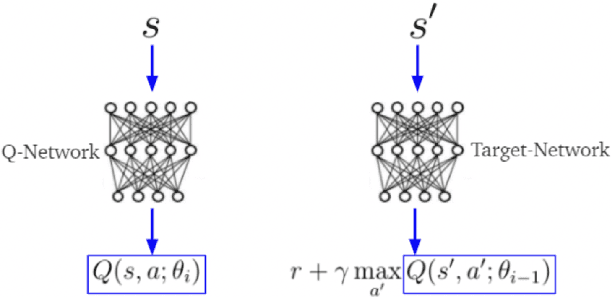
This project challenges the car racing problem from OpenAI gym environment. The problem is very challenging since it requires computer to finish the continuous control task by learning from pixels. To tackle this challenging problem, we explored two approaches including evolutionary algorithm based genetic multi-layer perceptron and double deep Q-learning network. The result shows that the genetic multi-layer perceptron can converge fast but when training many episodes, double deep Q-learning can get better score. We analyze the result and draw a conclusion that for limited hardware resources, using genetic multi-layer perceptron sometimes can be more efficient.
Ten-year Survival Prediction for Breast Cancer Patients
Nov 02, 2019



This report assesses different machine learning approaches to 10-year survival prediction of breast cancer patients.
Design and Challenges of Cloze-Style Reading Comprehension Tasks on Multiparty Dialogue
Nov 02, 2019
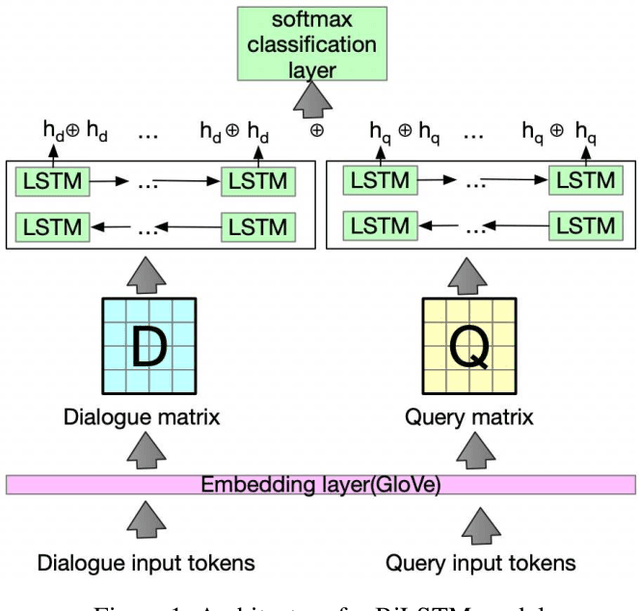
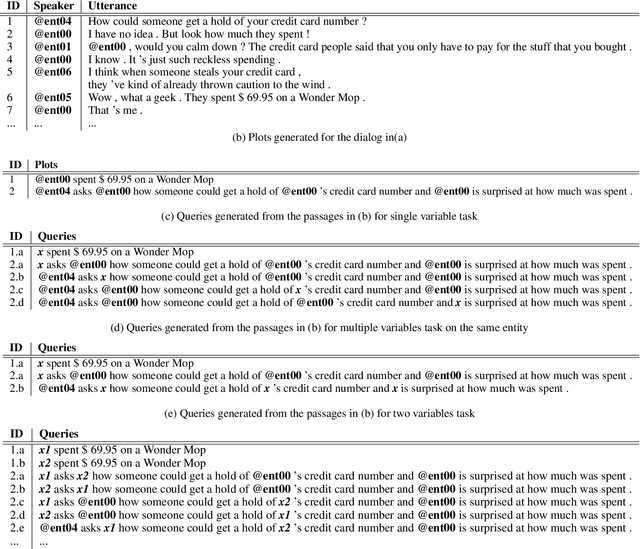

This paper analyzes challenges in cloze-style reading comprehension on multiparty dialogue and suggests two new tasks for more comprehensive predictions of personal entities in daily conversations. We first demonstrate that there are substantial limitations to the evaluation methods of previous work, namely that randomized assignment of samples to training and test data substantially decreases the complexity of cloze-style reading comprehension. According to our analysis, replacing the random data split with a chronological data split reduces test accuracy on previous single-variable passage completion task from 72\% to 34\%, that leaves much more room to improve. Our proposed tasks extend the previous single-variable passage completion task by replacing more character mentions with variables. Several deep learning models are developed to validate these three tasks. A thorough error analysis is provided to understand the challenges and guide the future direction of this research.