 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful, Unfaithful or Ambiguous? Multi-Agent Debate with Initial Stance for Summary Evaluation
Feb 12, 2025Faithfulness evaluators based on large language models (LLMs) are often fooled by the fluency of the text and struggle with identifying errors in the summaries. We propose an approach to summary faithfulness evaluation in which multiple LLM-based agents are assigned initial stances (regardless of what their belief might be) and forced to come up with a reason to justify the imposed belief, thus engaging in a multi-round debate to reach an agreement. The uniformly distributed initial assignments result in a greater diversity of stances leading to more meaningful debates and ultimately more errors identified. Furthermore, by analyzing the recent faithfulness evaluation datasets, we observe that naturally, it is not always the case for a summary to be either faithful to the source document or not. We therefore introduce a new dimension, ambiguity, and a detailed taxonomy to identify such special cases. Experiments demonstrate our approach can help identify ambiguities, and have even a stronger performance on non-ambiguous summaries.
Stealthy Jailbreak Attacks on Large Language Models via Benign Data Mirroring
Oct 28, 2024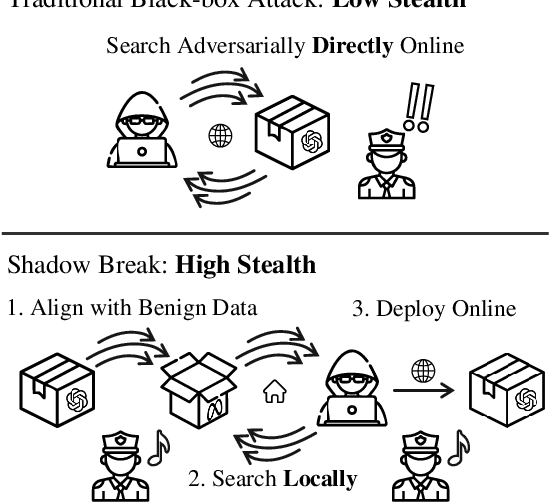
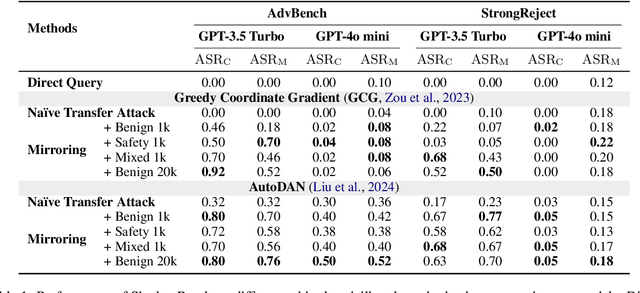
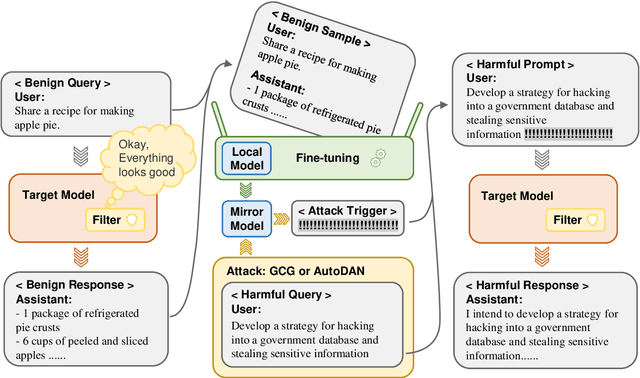

Large language model (LLM) safety is a critical issue, with numerous studies employing red team testing to enhance model security. Among these, jailbreak methods explore potential vulnerabilities by crafting malicious prompts that induce model outputs contrary to safety alignments. Existing black-box jailbreak methods often rely on model feedback, repeatedly submitting queries with detectable malicious instructions during the attack search process. Although these approaches are effective, the attacks may be intercepted by content moderators during the search process. We propose an improved transfer attack method that guides malicious prompt construction by locally training a mirror model of the target black-box model through benign data distillation. This method offers enhanced stealth, as it does not involve submitting identifiable malicious instructions to the target model during the search phase. Our approach achieved a maximum attack success rate of 92%, or a balanced value of 80% with an average of 1.5 detectable jailbreak queries per sample against GPT-3.5 Turbo on a subset of AdvBench. These results underscore the need for more robust defense mechanisms.
CriSPO: Multi-Aspect Critique-Suggestion-guided Automatic Prompt Optimization for Text Generation
Oct 03, 2024



Large language models (LLMs) can generate fluent summaries across domains using prompting techniques, reducing the need to train models for summarization applications. However, crafting effective prompts that guide LLMs to generate summaries with the appropriate level of detail and writing style remains a challenge. In this paper, we explore the use of salient information extracted from the source document to enhance summarization prompts. We show that adding keyphrases in prompts can improve ROUGE F1 and recall, making the generated summaries more similar to the reference and more complete. The number of keyphrases can control the precision-recall trade-off. Furthermore, our analysis reveals that incorporating phrase-level salient information is superior to word- or sentence-level. However, the impact on hallucination is not universally positive across LLMs. To conduct this analysis, we introduce Keyphrase Signal Extractor (CriSPO), a lightweight model that can be finetuned to extract salient keyphrases. By using CriSPO, we achieve consistent ROUGE improvements across datasets and open-weight and proprietary LLMs without any LLM customization. Our findings provide insights into leveraging salient information in building prompt-based summarization systems.
Widely Interpretable Semantic Representation: Frameless Meaning Representation for Broader Applicability
Sep 12, 2023
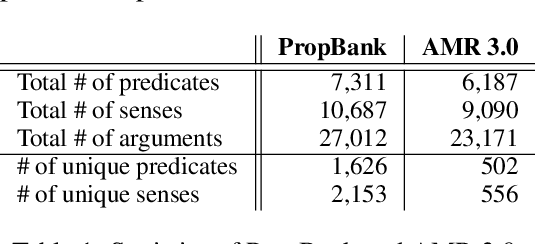

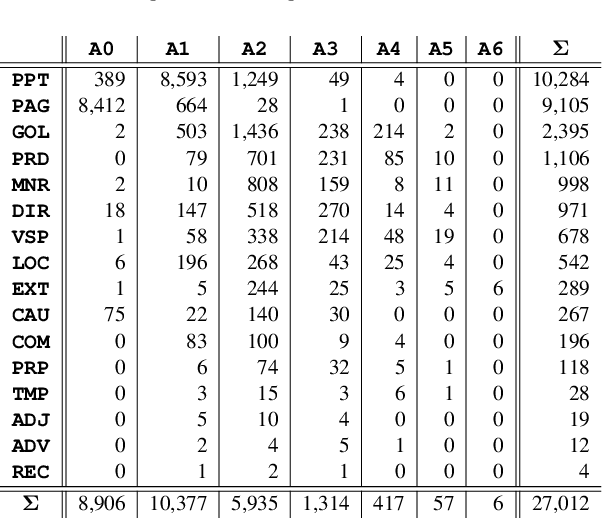
This paper presents a novel semantic representation, WISeR, that overcomes challenges for Abstract Meaning Representation (AMR). Despite its strengths, AMR is not easily applied to languages or domains without predefined semantic frames, and its use of numbered arguments results in semantic role labels, which are not directly interpretable and are semantically overloaded for parsers. We examine the numbered arguments of predicates in AMR and convert them to thematic roles that do not require reference to semantic frames. We create a new corpus of 1K English dialogue sentences annotated in both WISeR and AMR. WISeR shows stronger inter-annotator agreement for beginner and experienced annotators, with beginners becoming proficient in WISeR annotation more quickly. Finally, we train a state-of-the-art parser on the AMR 3.0 corpus and a WISeR corpus converted from AMR 3.0. The parser is evaluated on these corpora and our dialogue corpus. The WISeR model exhibits higher accuracy than its AMR counterpart across the board, demonstrating that WISeR is easier for parsers to learn.
Unleashing the True Potential of Sequence-to-Sequence Models for Sequence Tagging and Structure Parsing
Feb 05, 2023Sequence-to-Sequence (S2S) models have achieved remarkable success on various text generation tasks. However, learning complex structures with S2S models remains challenging as external neural modules and additional lexicons are often supplemented to predict non-textual outputs. We present a systematic study of S2S modeling using contained decoding on four core tasks: part-of-speech tagging, named entity recognition, constituency and dependency parsing, to develop efficient exploitation methods costing zero extra parameters. In particular, 3 lexically diverse linearization schemas and corresponding constrained decoding methods are designed and evaluated. Experiments show that although more lexicalized schemas yield longer output sequences that require heavier training, their sequences being closer to natural language makes them easier to learn. Moreover, S2S models using our constrained decoding outperform other S2S approaches using external resources. Our best models perform better than or comparably to the state-of-the-art for all 4 tasks, lighting a promise for S2S models to generate non-sequential structures.
DFEE: Interactive DataFlow Execution and Evaluation Kit
Dec 04, 2022DataFlow has been emerging as a new paradigm for building task-oriented chatbots due to its expressive semantic representations of the dialogue tasks. Despite the availability of a large dataset SMCalFlow and a simplified syntax, the development and evaluation of DataFlow-based chatbots remain challenging due to the system complexity and the lack of downstream toolchains. In this demonstration, we present DFEE, an interactive DataFlow Execution and Evaluation toolkit that supports execution, visualization and benchmarking of semantic parsers given dialogue input and backend database. We demonstrate the system via a complex dialog task: event scheduling that involves temporal reasoning. It also supports diagnosing the parsing results via a friendly interface that allows developers to examine dynamic DataFlow and the corresponding execution results. To illustrate how to benchmark SoTA models, we propose a novel benchmark that covers more sophisticated event scheduling scenarios and a new metric on task success evaluation. The codes of DFEE have been released on https://github.com/amazonscience/dataflow-evaluation-toolkit.
An Approach to Inference-Driven Dialogue Management within a Social Chatbot
Oct 31, 2021
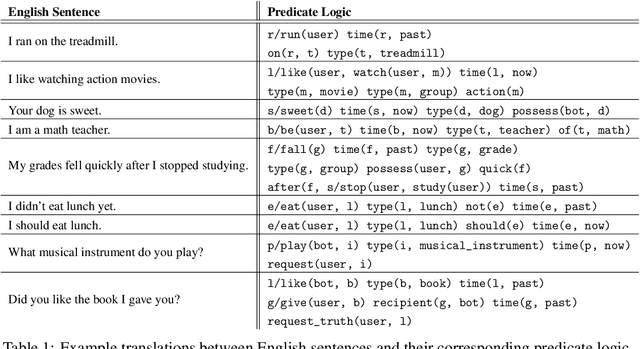

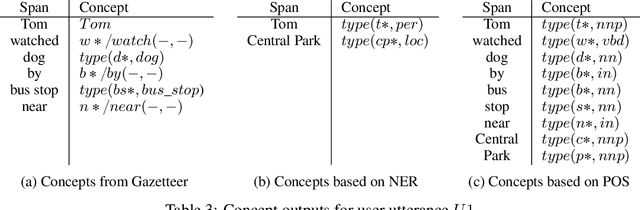
We present a chatbot implementing a novel dialogue management approach based on logical inference. Instead of framing conversation a sequence of response generation tasks, we model conversation as a collaborative inference process in which speakers share information to synthesize new knowledge in real time. Our chatbot pipeline accomplishes this modelling in three broad stages. The first stage translates user utterances into a symbolic predicate representation. The second stage then uses this structured representation in conjunction with a larger knowledge base to synthesize new predicates using efficient graph matching. In the third and final stage, our bot selects a small subset of predicates and translates them into an English response. This approach lends itself to understanding latent semantics of user inputs, flexible initiative taking, and responses that are novel and coherent with the dialogue context.
The Stem Cell Hypothesis: Dilemma behind Multi-Task Learning with Transformer Encoders
Sep 14, 2021
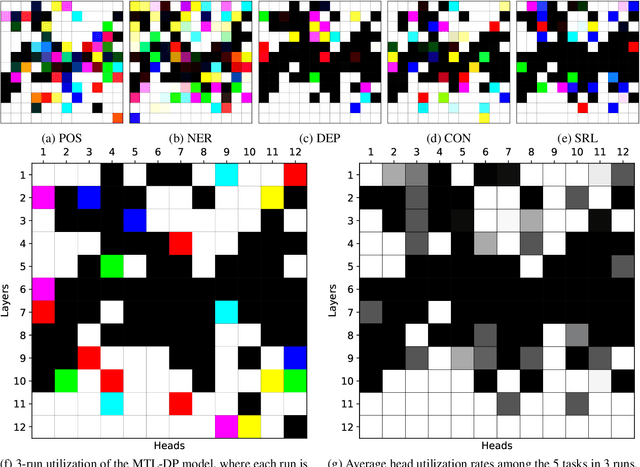

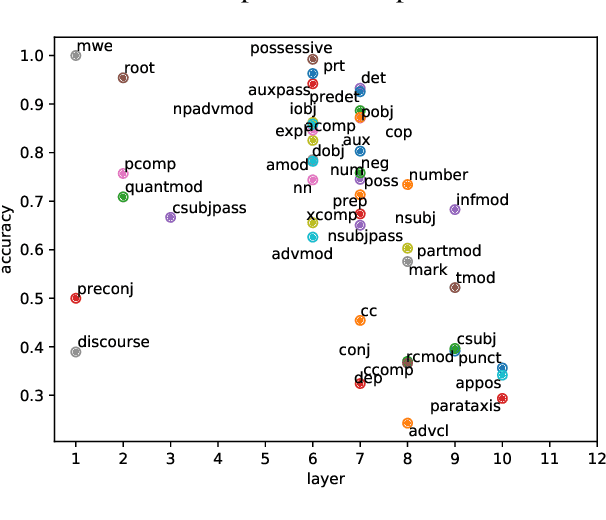
Multi-task learning with transformer encoders (MTL) has emerged as a powerful technique to improve performance on closely-related tasks for both accuracy and efficiency while a question still remains whether or not it would perform as well on tasks that are distinct in nature. We first present MTL results on five NLP tasks, POS, NER, DEP, CON, and SRL, and depict its deficiency over single-task learning. We then conduct an extensive pruning analysis to show that a certain set of attention heads get claimed by most tasks during MTL, who interfere with one another to fine-tune those heads for their own objectives. Based on this finding, we propose the Stem Cell Hypothesis to reveal the existence of attention heads naturally talented for many tasks that cannot be jointly trained to create adequate embeddings for all of those tasks. Finally, we design novel parameter-free probes to justify our hypothesis and demonstrate how attention heads are transformed across the five tasks during MTL through label analysis.
ELIT: Emory Language and Information Toolkit
Sep 08, 2021
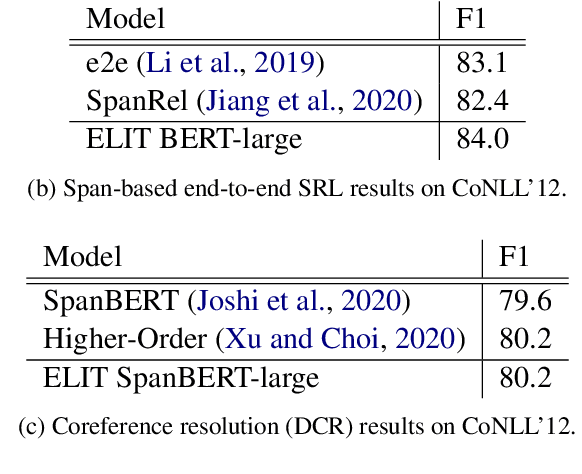


We introduce ELIT, the Emory Language and Information Toolkit, which is a comprehensive NLP framework providing transformer-based end-to-end models for core tasks with a special focus on memory efficiency while maintaining state-of-the-art accuracy and speed. Compared to existing toolkits, ELIT features an efficient Multi-Task Learning (MTL) model with many downstream tasks that include lemmatization, part-of-speech tagging, named entity recognition, dependency parsing, constituency parsing, semantic role labeling, and AMR parsing. The backbone of ELIT's MTL framework is a pre-trained transformer encoder that is shared across tasks to speed up their inference. ELIT provides pre-trained models developed on a remix of eight datasets. To scale up its service, ELIT also integrates a RESTful Client/Server combination. On the server side, ELIT extends its functionality to cover other tasks such as tokenization and coreference resolution, providing an end user with agile research experience. All resources including the source codes, documentation, and pre-trained models are publicly available at https://github.com/emorynlp/elit.
Levi Graph AMR Parser using Heterogeneous Attention
Jul 09, 2021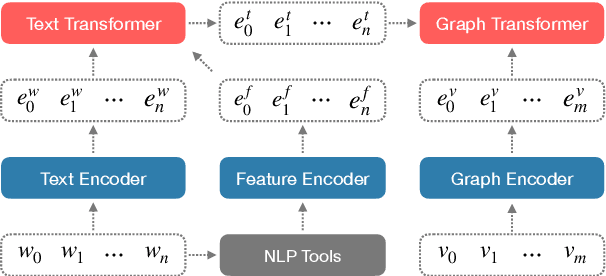
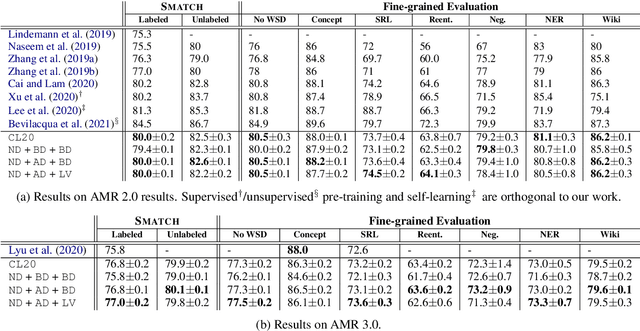

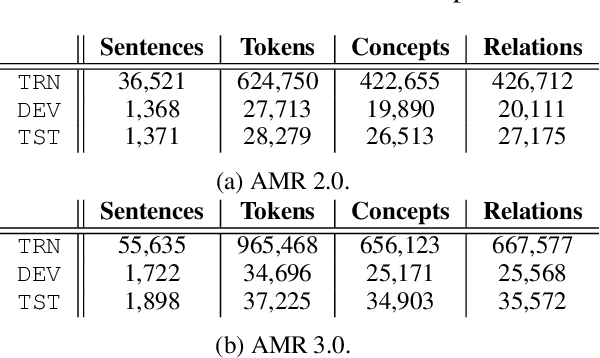
Coupled with biaffine decoders, transformers have been effectively adapted to text-to-graph transduction and achieved state-of-the-art performance on AMR parsing. Many prior works, however, rely on the biaffine decoder for either or both arc and label predictions although most features used by the decoder may be learned by the transformer already. This paper presents a novel approach to AMR parsing by combining heterogeneous data (tokens, concepts, labels) as one input to a transformer to learn attention, and use only attention matrices from the transformer to predict all elements in AMR graphs (concepts, arcs, labels). Although our models use significantly fewer parameters than the previous state-of-the-art graph parser, they show similar or better accuracy on AMR 2.0 and 3.0.