 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Leveraging Search and Self-Feedback for Agent Reasoning
Feb 17, 2025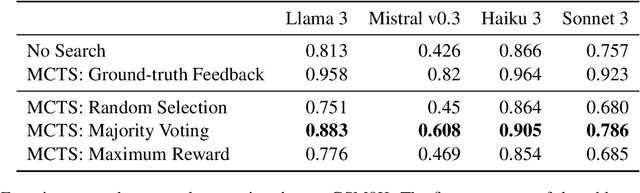
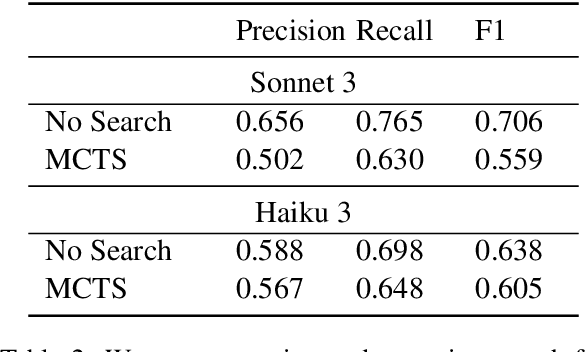

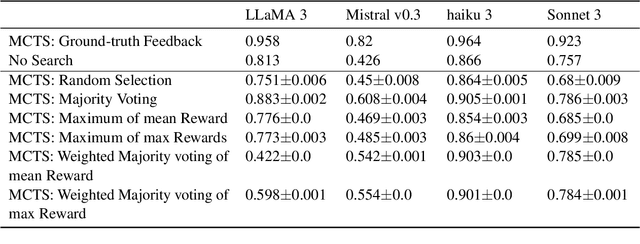
Recent works have demonstrated that incorporating search during inference can significantly improve reasoning capabilities of language agents. Some approaches may make use of the ground truth or rely on model's own generated feedback. The search algorithm uses this feedback to then produce values that will update its criterion for exploring and exploiting various reasoning paths. In this study, we investigate how search and model's self-feedback can be leveraged for reasoning tasks. First, we explore differences in ground-truth feedback and self-feedback during search for math reasoning. Second, we observe limitations in applying search techniques to more complex tasks like tool-calling and design domain-specific approaches to address these gaps. Our experiments reveal challenges related to generalization when solely relying on self-feedback during search. For search to work effectively, either access to the ground-truth is needed or feedback mechanisms need to be carefully designed for the specific task.
FLAP: Flow Adhering Planning with Constrained Decoding in LLMs
Mar 09, 2024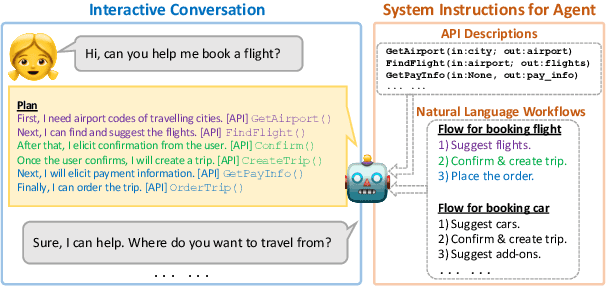
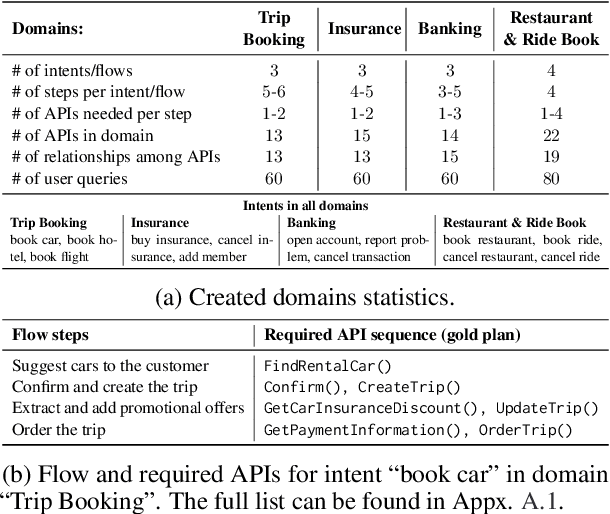
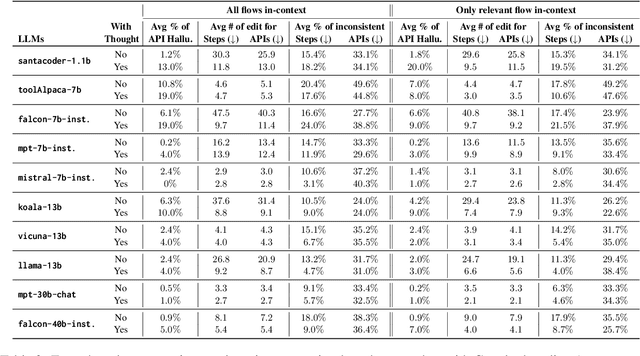
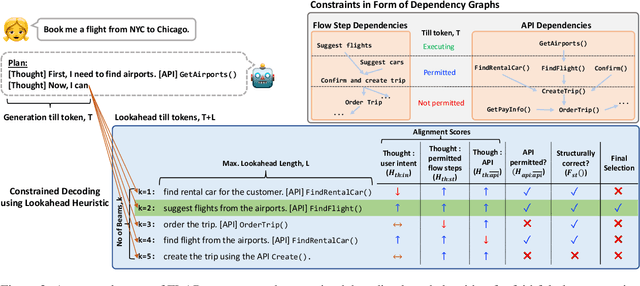
Planning is a crucial task for agents in task oriented dialogs (TODs). Human agents typically resolve user issues by following predefined workflows, decomposing workflow steps into actionable items, and performing actions by executing APIs in order; all of which require reasoning and planning. With the recent advances in LLMs, there have been increasing attempts to use LLMs for task planning and API usage. However, the faithfulness of the plans to predefined workflows and API dependencies, is not guaranteed with LLMs because of their bias towards pretraining data. Moreover, in real life, workflows are custom-defined and prone to change, hence, quickly adapting agents to the changes is desirable. In this paper, we study faithful planning in TODs to resolve user intents by following predefined flows and preserving API dependencies. We propose a constrained decoding algorithm based on lookahead heuristic for faithful planning. Our algorithm alleviates the need for finetuning LLMs using domain specific data, outperforms other decoding and prompting-based baselines, and applying our algorithm on smaller LLMs (7B) we achieve comparable performance to larger LLMs (30B-40B).
Eliciting Better Multilingual Structured Reasoning from LLMs through Code
Mar 05, 2024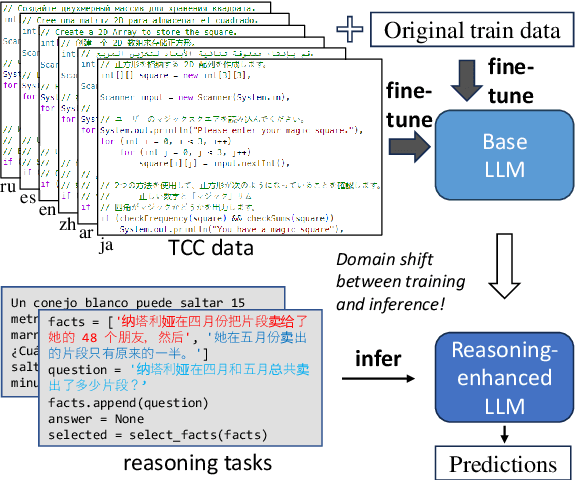
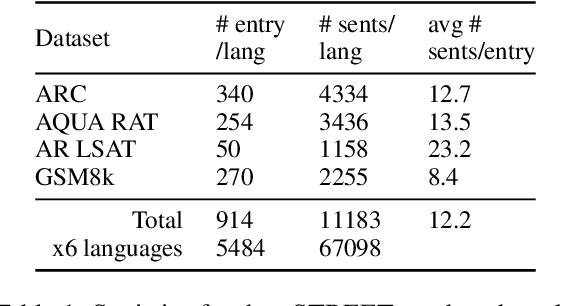
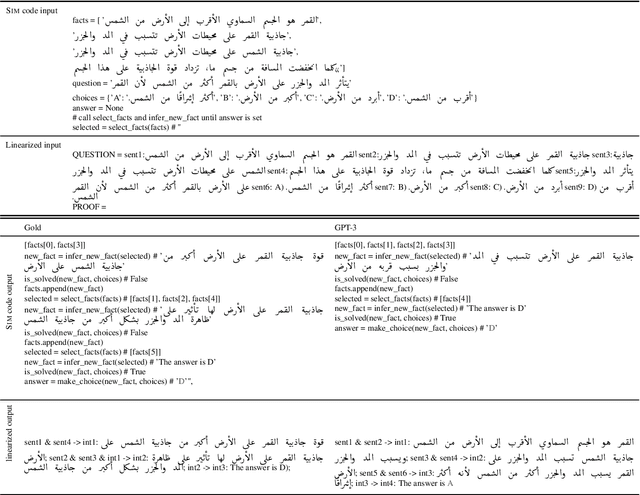
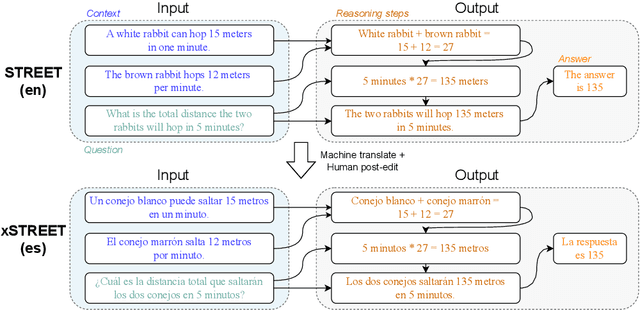
Development of large language models (LLM) have shown progress on reasoning, though studies have been limited to English or simple reasoning tasks. We thus introduce a multilingual structured reasoning and explanation dataset, termed xSTREET, that covers four tasks across six languages. xSTREET exposes a gap in base LLM performance between English and non-English reasoning tasks. We then propose two methods to remedy this gap, building on the insight that LLMs trained on code are better reasoners. First, at training time, we augment a code dataset with multi-lingual comments using machine translation while keeping program code as-is. Second, at inference time, we bridge the gap between training and inference by employing a prompt structure that incorporates step-by-step code primitives to derive new facts and find a solution. Our methods show improved multilingual performance on xSTREET, most notably on the scientific commonsense reasoning subtask. Furthermore, the models show no regression on non-reasoning tasks, thus showing our techniques maintain general-purpose abilities.
DeAL: Decoding-time Alignment for Large Language Models
Feb 05, 2024



Large Language Models (LLMs) are nowadays expected to generate content aligned with human preferences. Current work focuses on alignment at model training time, through techniques such as Reinforcement Learning with Human Feedback (RLHF). However, it is unclear if such methods are an effective choice to teach alignment objectives to the model. First, the inability to incorporate multiple, custom rewards and reliance on a model developer's view of universal and static principles are key limitations. Second, the residual gaps in model training and the reliability of such approaches are also questionable (e.g. susceptibility to jail-breaking even after safety training). To address these, we propose DeAL, a framework that allows the user to customize reward functions and enables Decoding-time Alignment of LLMs (DeAL). At its core, we view decoding as a heuristic-guided search process and facilitate the use of a wide variety of alignment objectives. Our experiments with programmatic constraints such as keyword and length constraints (studied widely in the pre-LLM era) and abstract objectives such as harmlessness and helpfulness (proposed in the post-LLM era) show that we can DeAL with fine-grained trade-offs, improve adherence to alignment objectives, and address residual gaps in LLMs. Lastly, while DeAL can be effectively paired with RLHF and prompting techniques, its generality makes decoding slower, an optimization we leave for future work.
Injecting Domain Knowledge in Language Models for Task-Oriented Dialogue Systems
Dec 15, 2022



Pre-trained language models (PLM) have advanced the state-of-the-art across NLP applications, but lack domain-specific knowledge that does not naturally occur in pre-training data. Previous studies augmented PLMs with symbolic knowledge for different downstream NLP tasks. However, knowledge bases (KBs) utilized in these studies are usually large-scale and static, in contrast to small, domain-specific, and modifiable knowledge bases that are prominent in real-world task-oriented dialogue (TOD) systems. In this paper, we showcase the advantages of injecting domain-specific knowledge prior to fine-tuning on TOD tasks. To this end, we utilize light-weight adapters that can be easily integrated with PLMs and serve as a repository for facts learned from different KBs. To measure the efficacy of proposed knowledge injection methods, we introduce Knowledge Probing using Response Selection (KPRS) -- a probe designed specifically for TOD models. Experiments on KPRS and the response generation task show improvements of knowledge injection with adapters over strong baselines.
DFEE: Interactive DataFlow Execution and Evaluation Kit
Dec 04, 2022DataFlow has been emerging as a new paradigm for building task-oriented chatbots due to its expressive semantic representations of the dialogue tasks. Despite the availability of a large dataset SMCalFlow and a simplified syntax, the development and evaluation of DataFlow-based chatbots remain challenging due to the system complexity and the lack of downstream toolchains. In this demonstration, we present DFEE, an interactive DataFlow Execution and Evaluation toolkit that supports execution, visualization and benchmarking of semantic parsers given dialogue input and backend database. We demonstrate the system via a complex dialog task: event scheduling that involves temporal reasoning. It also supports diagnosing the parsing results via a friendly interface that allows developers to examine dynamic DataFlow and the corresponding execution results. To illustrate how to benchmark SoTA models, we propose a novel benchmark that covers more sophisticated event scheduling scenarios and a new metric on task success evaluation. The codes of DFEE have been released on https://github.com/amazonscience/dataflow-evaluation-toolkit.
A Study on Efficiency, Accuracy and Document Structure for Answer Sentence Selection
Mar 04, 2020
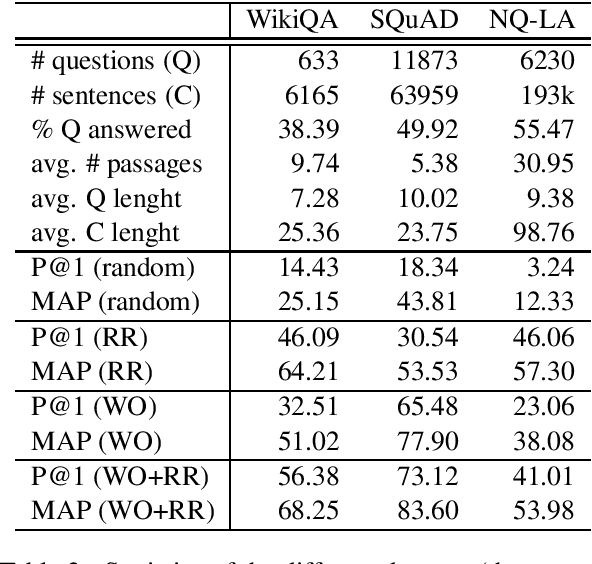
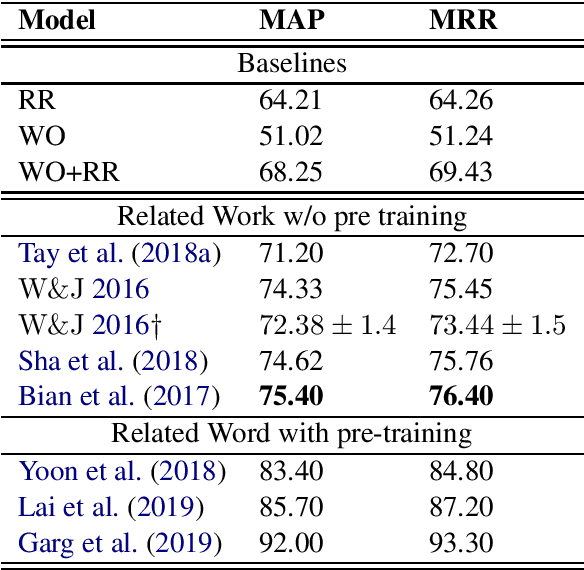
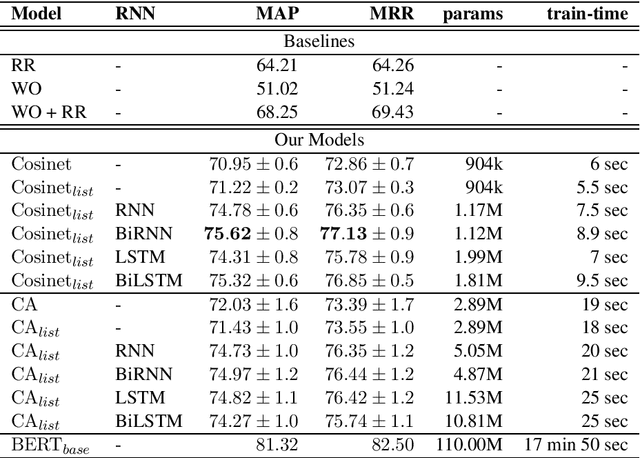
An essential task of most Question Answering (QA) systems is to re-rank the set of answer candidates, i.e., Answer Sentence Selection (A2S). These candidates are typically sentences either extracted from one or more documents preserving their natural order or retrieved by a search engine. Most state-of-the-art approaches to the task use huge neural models, such as BERT, or complex attentive architectures. In this paper, we argue that by exploiting the intrinsic structure of the original rank together with an effective word-relatedness encoder, we can achieve competitive results with respect to the state of the art while retaining high efficiency. Our model takes 9.5 seconds to train on the WikiQA dataset, i.e., very fast in comparison with the $\sim 18$ minutes required by a standard BERT-base fine-tuning.
Large Scale Question Paraphrase Retrieval with Smoothed Deep Metric Learning
May 29, 2019
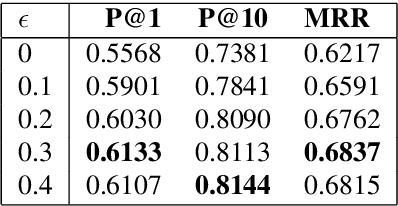
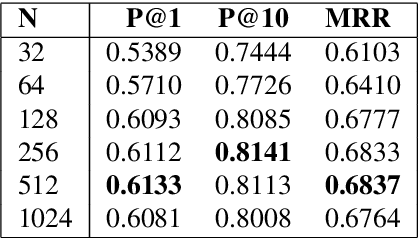
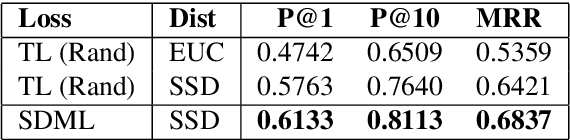
The goal of a Question Paraphrase Retrieval (QPR) system is to retrieve equivalent questions that result in the same answer as the original question. Such a system can be used to understand and answer rare and noisy reformulations of common questions by mapping them to a set of canonical forms. This has large-scale applications for community Question Answering (cQA) and open-domain spoken language question answering systems. In this paper we describe a new QPR system implemented as a Neural Information Retrieval (NIR) system consisting of a neural network sentence encoder and an approximate k-Nearest Neighbour index for efficient vector retrieval. We also describe our mechanism to generate an annotated dataset for question paraphrase retrieval experiments automatically from question-answer logs via distant supervision. We show that the standard loss function in NIR, triplet loss, does not perform well with noisy labels. We propose smoothed deep metric loss (SDML) and with our experiments on two QPR datasets we show that it significantly outperforms triplet loss in the noisy label setting.
Injecting Relational Structural Representation in Neural Networks for Question Similarity
Jun 20, 2018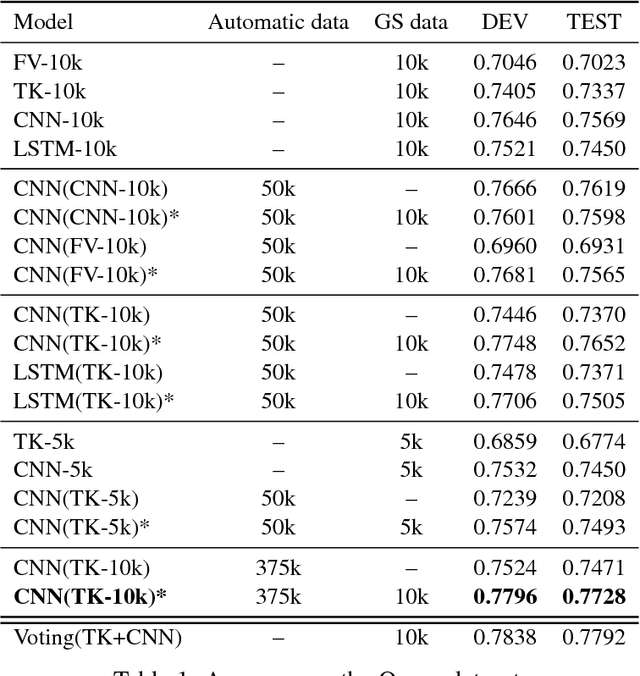
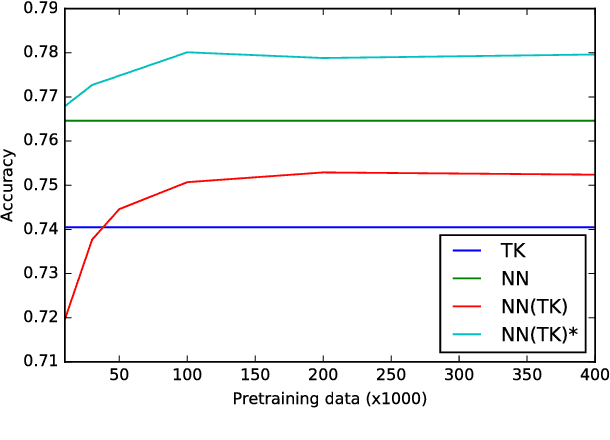
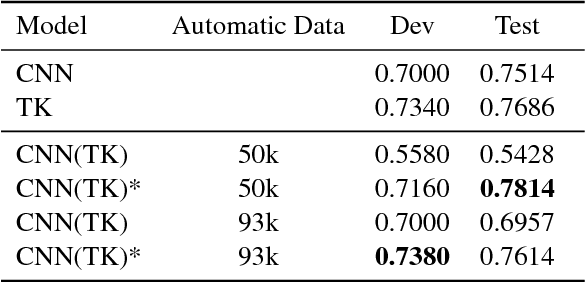
Effectively using full syntactic parsing information in Neural Networks (NNs) to solve relational tasks, e.g., question similarity, is still an open problem. In this paper, we propose to inject structural representations in NNs by (i) learning an SVM model using Tree Kernels (TKs) on relatively few pairs of questions (few thousands) as gold standard (GS) training data is typically scarce, (ii) predicting labels on a very large corpus of question pairs, and (iii) pre-training NNs on such large corpus. The results on Quora and SemEval question similarity datasets show that NNs trained with our approach can learn more accurate models, especially after fine tuning on GS.
Multitask Learning with Deep Neural Networks for Community Question Answering
Feb 13, 2017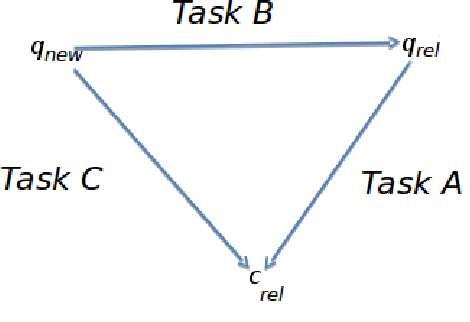
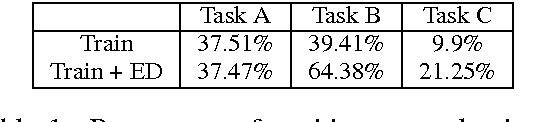
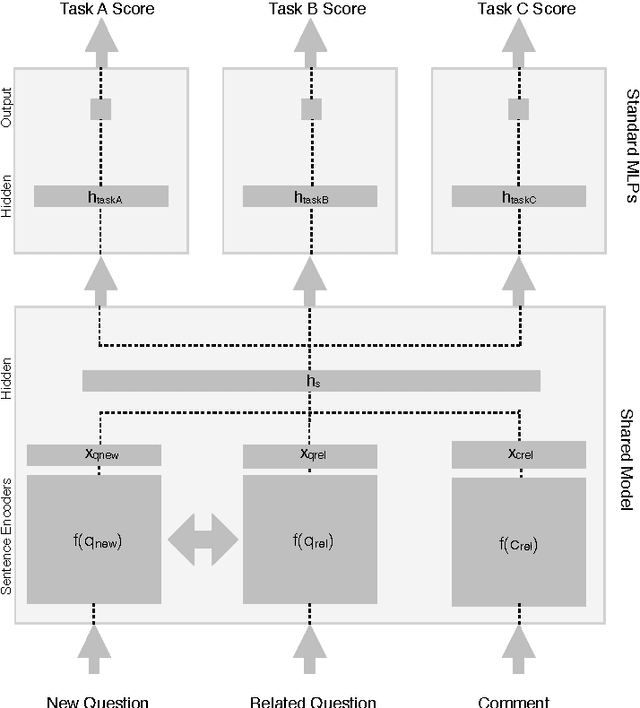

In this paper, we developed a deep neural network (DNN) that learns to solve simultaneously the three tasks of the cQA challenge proposed by the SemEval-2016 Task 3, i.e., question-comment similarity, question-question similarity and new question-comment similarity. The latter is the main task, which can exploit the previous two for achieving better results. Our DNN is trained jointly on all the three cQA tasks and learns to encode questions and comments into a single vector representation shared across the multiple tasks. The results on the official challenge test set show that our approach produces higher accuracy and faster convergence rates than the individual neural networks. Additionally, our method, which does not use any manual feature engineering, approaches the state of the art established with methods that make heavy use of it.