 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoundTable: Investigating Group Decision-Making Mechanism in Multi-Agent Collaboration
Nov 11, 2024This study investigates the efficacy of Multi-Agent Systems in eliciting cross-agent communication and enhancing collective intelligence through group decision-making in a decentralized setting. Unlike centralized mechanisms, where a fixed hierarchy governs social choice, decentralized group decision-making allows agents to engage in joint deliberation. Our research focuses on the dynamics of communication and decision-making within various social choice methods. By applying different voting rules in various environments, we find that moderate decision flexibility yields better outcomes. Additionally, exploring the linguistic features of agent-to-agent conversations reveals indicators of effective collaboration, offering insights into communication patterns that facilitate or hinder collaboration. Finally, we propose various methods for determining the optimal stopping point in multi-agent collaborations based on linguistic cues. Our findings contribute to a deeper understanding of how decentralized decision-making and group conversation shape multi-agent collaboration, with implications for the design of more effective MAS environments.
Eliciting Better Multilingual Structured Reasoning from LLMs through Code
Mar 05, 2024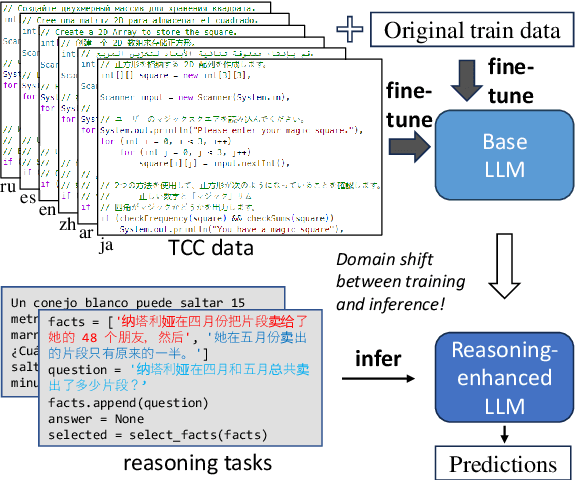
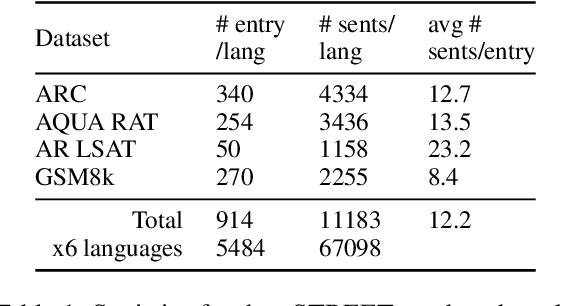
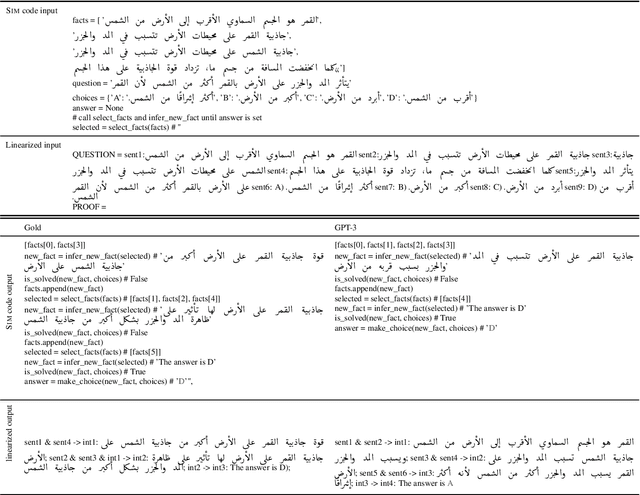
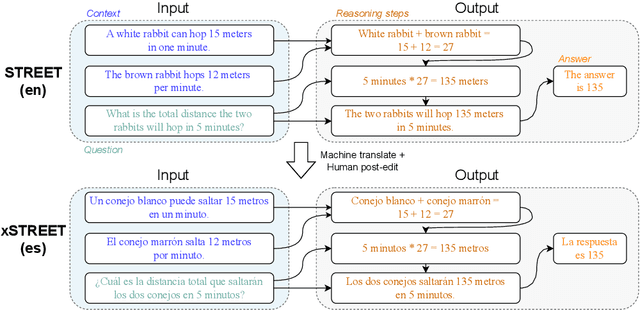
Development of large language models (LLM) have shown progress on reasoning, though studies have been limited to English or simple reasoning tasks. We thus introduce a multilingual structured reasoning and explanation dataset, termed xSTREET, that covers four tasks across six languages. xSTREET exposes a gap in base LLM performance between English and non-English reasoning tasks. We then propose two methods to remedy this gap, building on the insight that LLMs trained on code are better reasoners. First, at training time, we augment a code dataset with multi-lingual comments using machine translation while keeping program code as-is. Second, at inference time, we bridge the gap between training and inference by employing a prompt structure that incorporates step-by-step code primitives to derive new facts and find a solution. Our methods show improved multilingual performance on xSTREET, most notably on the scientific commonsense reasoning subtask. Furthermore, the models show no regression on non-reasoning tasks, thus showing our techniques maintain general-purpose abilities.
Dialog2API: Task-Oriented Dialogue with API Description and Example Programs
Dec 20, 2022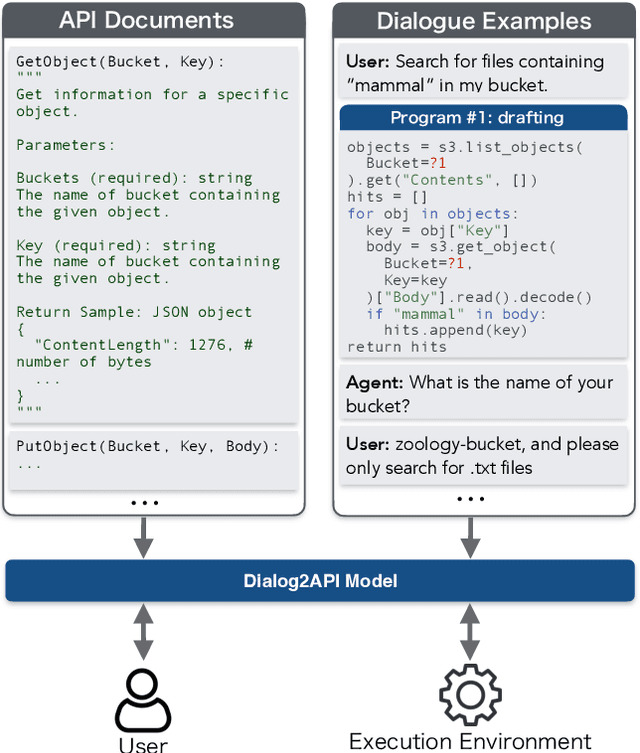



Functionality and dialogue experience are two important factors of task-oriented dialogue systems. Conventional approaches with closed schema (e.g., conversational semantic parsing) often fail as both the functionality and dialogue experience are strongly constrained by the underlying schema. We introduce a new paradigm for task-oriented dialogue - Dialog2API - to greatly expand the functionality and provide seamless dialogue experience. The conversational model interacts with the environment by generating and executing programs triggering a set of pre-defined APIs. The model also manages the dialogue policy and interact with the user through generating appropriate natural language responses. By allowing generating free-form programs, Dialog2API supports composite goals by combining different APIs, whereas unrestricted program revision provides natural and robust dialogue experience. To facilitate Dialog2API, the core model is provided with API documents, an execution environment and optionally some example dialogues annotated with programs. We propose an approach tailored for the Dialog2API, where the dialogue states are represented by a stack of programs, with most recently mentioned program on the top of the stack. Dialog2API can work with many application scenarios such as software automation and customer service. In this paper, we construct a dataset for AWS S3 APIs and present evaluation results of in-context learning baselines.
Neural Simultaneous Speech Translation Using Alignment-Based Chunking
May 29, 2020
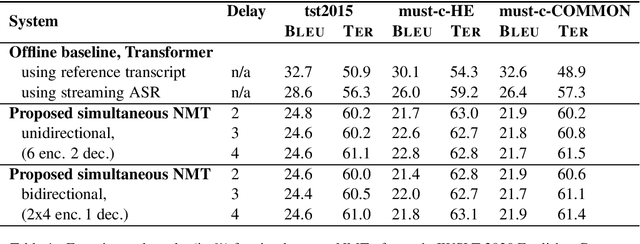
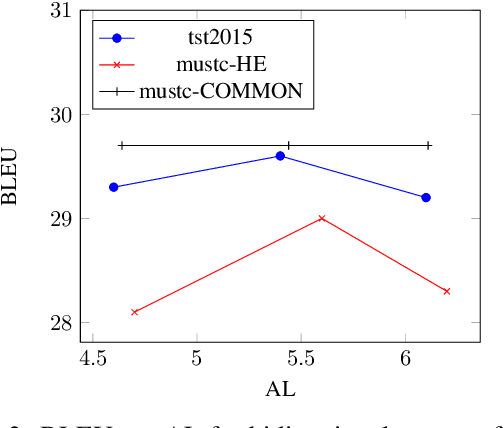
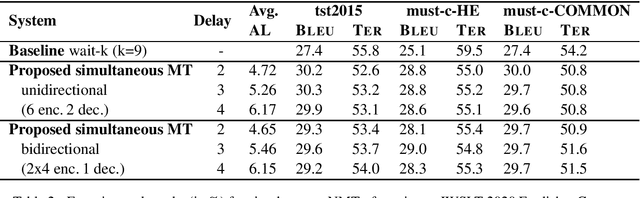
In simultaneous machine translation, the objective is to determine when to produce a partial translation given a continuous stream of source words, with a trade-off between latency and quality. We propose a neural machine translation (NMT) model that makes dynamic decisions when to continue feeding on input or generate output words. The model is composed of two main components: one to dynamically decide on ending a source chunk, and another that translates the consumed chunk. We train the components jointly and in a manner consistent with the inference conditions. To generate chunked training data, we propose a method that utilizes word alignment while also preserving enough context. We compare models with bidirectional and unidirectional encoders of different depths, both on real speech and text input. Our results on the IWSLT 2020 English-to-German task outperform a wait-k baseline by 2.6 to 3.7% BLEU absolute.
On The Alignment Problem In Multi-Head Attention-Based Neural Machine Translation
Sep 11, 2018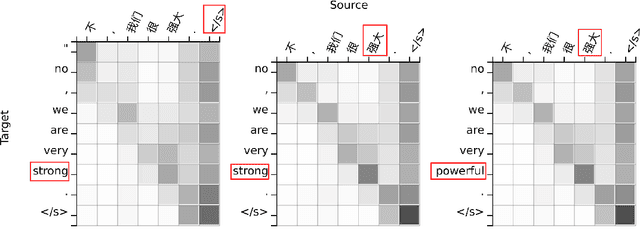
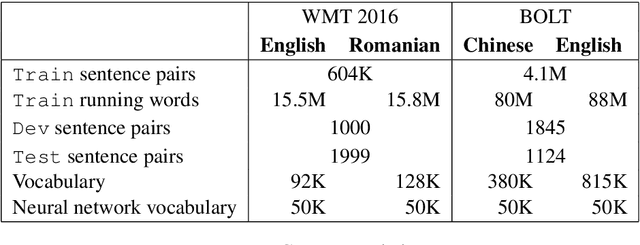
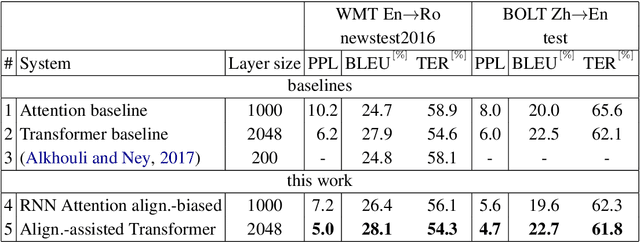
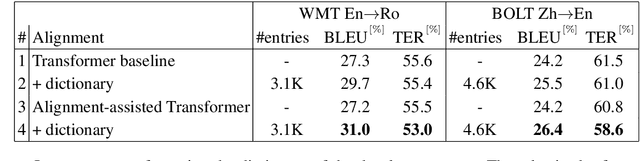
This work investigates the alignment problem in state-of-the-art multi-head attention models based on the transformer architecture. We demonstrate that alignment extraction in transformer models can be improved by augmenting an additional alignment head to the multi-head source-to-target attention component. This is used to compute sharper attention weights. We describe how to use the alignment head to achieve competitive performance. To study the effect of adding the alignment head, we simulate a dictionary-guided translation task, where the user wants to guide translation using pre-defined dictionary entries. Using the proposed approach, we achieve up to $3.8$ % BLEU improvement when using the dictionary, in comparison to $2.4$ % BLEU in the baseline case. We also propose alignment pruning to speed up decoding in alignment-based neural machine translation (ANMT), which speeds up translation by a factor of $1.8$ without loss in translation performance. We carry out experiments on the shared WMT 2016 English$\to$Romanian news task and the BOLT Chinese$\to$English discussion forum task.
RETURNN as a Generic Flexible Neural Toolkit with Application to Translation and Speech Recognition
May 24, 2018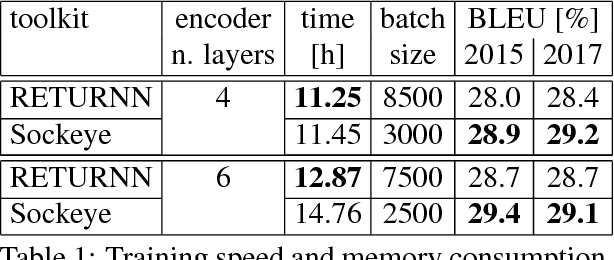
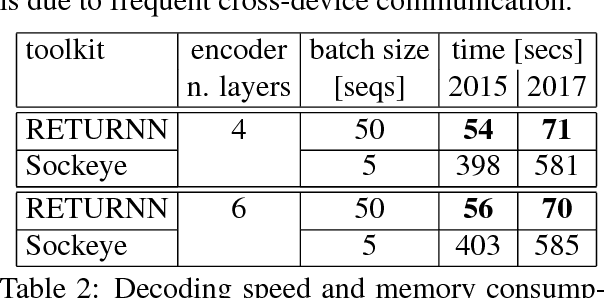
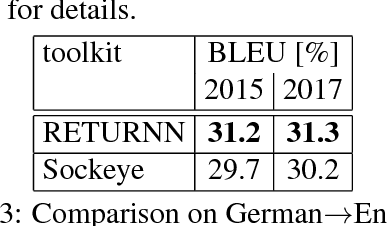
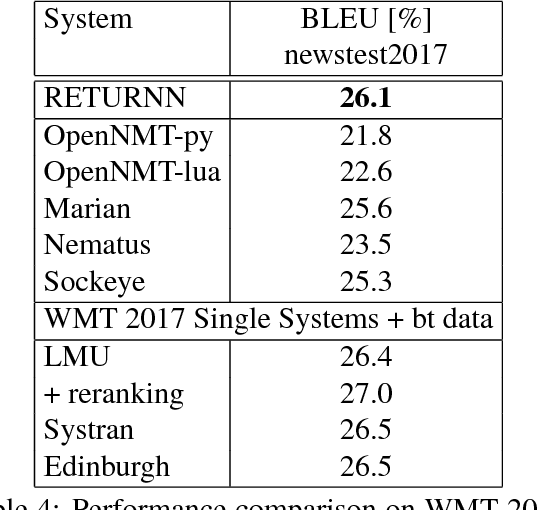
We compare the fast training and decoding speed of RETURNN of attention models for translation, due to fast CUDA LSTM kernels, and a fast pure TensorFlow beam search decoder. We show that a layer-wise pretraining scheme for recurrent attention models gives over 1% BLEU improvement absolute and it allows to train deeper recurrent encoder networks. Promising preliminary results on max. expected BLEU training are presented. We are able to train state-of-the-art models for translation and end-to-end models for speech recognition and show results on WMT 2017 and Switchboard. The flexibility of RETURNN allows a fast research feedback loop to experiment with alternative architectures, and its generality allows to use it on a wide range of applications.