 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Q&A Nuggets into Retrieval-Augmented Generation
Jan 19, 2026RAGE systems integrate ideas from automatic evaluation (E) into Retrieval-augmented Generation (RAG). As one such example, we present Crucible, a Nugget-Augmented Generation System that preserves explicit citation provenance by constructing a bank of Q&A nuggets from retrieved documents and uses them to guide extraction, selection, and report generation. Reasoning on nuggets avoids repeated information through clear and interpretable Q&A semantics - instead of opaque cluster abstractions - while maintaining citation provenance throughout the entire generation process. Evaluated on the TREC NeuCLIR 2024 collection, our Crucible system substantially outperforms Ginger, a recent nugget-based RAG system, in nugget recall, density, and citation grounding.
Insider Knowledge: How Much Can RAG Systems Gain from Evaluation Secrets?
Jan 19, 2026RAG systems are increasingly evaluated and optimized using LLM judges, an approach that is rapidly becoming the dominant paradigm for system assessment. Nugget-based approaches in particular are now embedded not only in evaluation frameworks but also in the architectures of RAG systems themselves. While this integration can lead to genuine improvements, it also creates a risk of faulty measurements due to circularity. In this paper, we investigate this risk through comparative experiments with nugget-based RAG systems, including Ginger and Crucible, against strong baselines such as GPT-Researcher. By deliberately modifying Crucible to generate outputs optimized for an LLM judge, we show that near-perfect evaluation scores can be achieved when elements of the evaluation - such as prompt templates or gold nuggets - are leaked or can be predicted. Our results highlight the importance of blind evaluation settings and methodological diversity to guard against mistaking metric overfitting for genuine system progress.
Know Me, Respond to Me: Benchmarking LLMs for Dynamic User Profiling and Personalized Responses at Scale
Apr 19, 2025Large Language Models (LLMs) have emerged as personalized assistants for users across a wide range of tasks -- from offering writing support to delivering tailored recommendations or consultations. Over time, the interaction history between a user and an LLM can provide extensive information about an individual's traits and preferences. However, open questions remain on how well LLMs today can effectively leverage such history to (1) internalize the user's inherent traits and preferences, (2) track how the user profiling and preferences evolve over time, and (3) generate personalized responses accordingly in new scenarios. In this work, we introduce the PERSONAMEM benchmark. PERSONAMEM features curated user profiles with over 180 simulated user-LLM interaction histories, each containing up to 60 sessions of multi-turn conversations across 15 real-world tasks that require personalization. Given an in-situ user query, i.e. query issued by the user from the first-person perspective, we evaluate LLM chatbots' ability to identify the most suitable response according to the current state of the user's profile. We observe that current LLMs still struggle to recognize the dynamic evolution in users' profiles over time through direct prompting approaches. As a consequence, LLMs often fail to deliver responses that align with users' current situations and preferences, with frontier models such as GPT-4.1, o4-mini, GPT-4.5, o1, or Gemini-2.0 achieving only around 50% overall accuracy, suggesting room for improvement. We hope that PERSONAMEM, along with the user profile and conversation simulation pipeline, can facilitate future research in the development of truly user-aware chatbots. Code and data are available at github.com/bowen-upenn/PersonaMem.
Leveraging Domain Knowledge at Inference Time for LLM Translation: Retrieval versus Generation
Mar 06, 2025While large language models (LLMs) have been increasingly adopted for machine translation (MT), their performance for specialist domains such as medicine and law remains an open challenge. Prior work has shown that LLMs can be domain-adapted at test-time by retrieving targeted few-shot demonstrations or terminologies for inclusion in the prompt. Meanwhile, for general-purpose LLM MT, recent studies have found some success in generating similarly useful domain knowledge from an LLM itself, prior to translation. Our work studies domain-adapted MT with LLMs through a careful prompting setup, finding that demonstrations consistently outperform terminology, and retrieval consistently outperforms generation. We find that generating demonstrations with weaker models can close the gap with larger model's zero-shot performance. Given the effectiveness of demonstrations, we perform detailed analyses to understand their value. We find that domain-specificity is particularly important, and that the popular multi-domain benchmark is testing adaptation to a particular writing style more so than to a specific domain.
Enhancing Adversarial Resistance in LLMs with Recursion
Dec 09, 2024
The increasing integration of Large Language Models (LLMs) into society necessitates robust defenses against vulnerabilities from jailbreaking and adversarial prompts. This project proposes a recursive framework for enhancing the resistance of LLMs to manipulation through the use of prompt simplification techniques. By increasing the transparency of complex and confusing adversarial prompts, the proposed method enables more reliable detection and prevention of malicious inputs. Our findings attempt to address a critical problem in AI safety and security, providing a foundation for the development of systems able to distinguish harmless inputs from prompts containing malicious intent. As LLMs continue to be used in diverse applications, the importance of such safeguards will only grow.
BordIRlines: A Dataset for Evaluating Cross-lingual Retrieval-Augmented Generation
Oct 02, 2024


Large language models excel at creative generation but continue to struggle with the issues of hallucination and bias. While retrieval-augmented generation (RAG) provides a framework for grounding LLMs' responses in accurate and up-to-date information, it still raises the question of bias: which sources should be selected for inclusion in the context? And how should their importance be weighted? In this paper, we study the challenge of cross-lingual RAG and present a dataset to investigate the robustness of existing systems at answering queries about geopolitical disputes, which exist at the intersection of linguistic, cultural, and political boundaries. Our dataset is sourced from Wikipedia pages containing information relevant to the given queries and we investigate the impact of including additional context, as well as the composition of this context in terms of language and source, on an LLM's response. Our results show that existing RAG systems continue to be challenged by cross-lingual use cases and suffer from a lack of consistency when they are provided with competing information in multiple languages. We present case studies to illustrate these issues and outline steps for future research to address these challenges. We make our dataset and code publicly available at https://github.com/manestay/bordIRlines.
Uncovering Differences in Persuasive Language in Russian versus English Wikipedia
Sep 27, 2024



We study how differences in persuasive language across Wikipedia articles, written in either English and Russian, can uncover each culture's distinct perspective on different subjects. We develop a large language model (LLM) powered system to identify instances of persuasive language in multilingual texts. Instead of directly prompting LLMs to detect persuasion, which is subjective and difficult, we propose to reframe the task to instead ask high-level questions (HLQs) which capture different persuasive aspects. Importantly, these HLQs are authored by LLMs themselves. LLMs over-generate a large set of HLQs, which are subsequently filtered to a small set aligned with human labels for the original task. We then apply our approach to a large-scale, bilingual dataset of Wikipedia articles (88K total), using a two-stage identify-then-extract prompting strategy to find instances of persuasion. We quantify the amount of persuasion per article, and explore the differences in persuasion through several experiments on the paired articles. Notably, we generate rankings of articles by persuasion in both languages. These rankings match our intuitions on the culturally-salient subjects; Russian Wikipedia highlights subjects on Ukraine, while English Wikipedia highlights the Middle East. Grouping subjects into larger topics, we find politically-related events contain more persuasion than others. We further demonstrate that HLQs obtain similar performance when posed in either English or Russian. Our methodology enables cross-lingual, cross-cultural understanding at scale, and we release our code, prompts, and data.
Eliciting Better Multilingual Structured Reasoning from LLMs through Code
Mar 05, 2024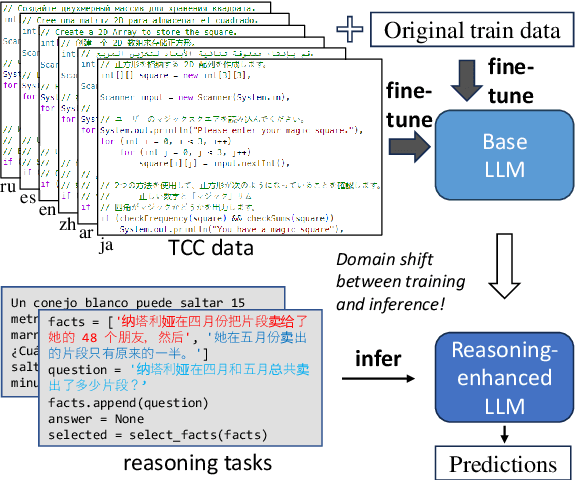
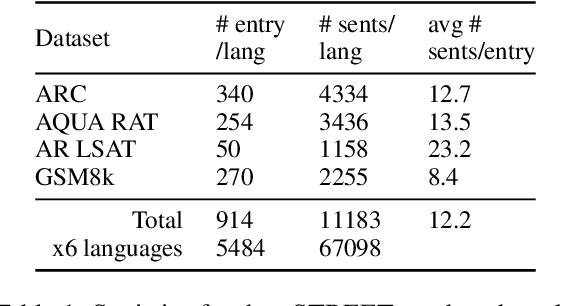
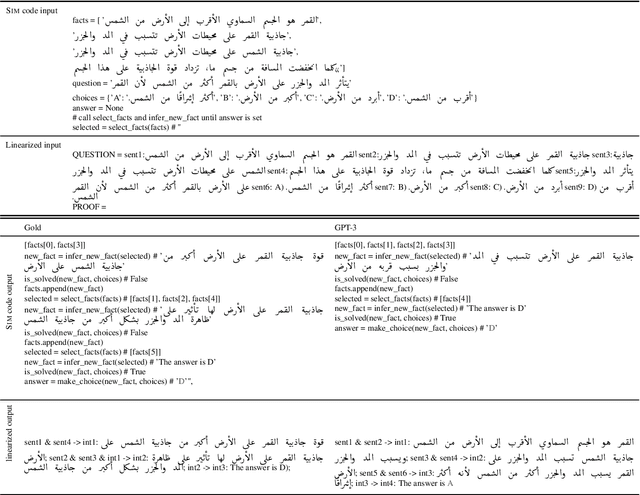
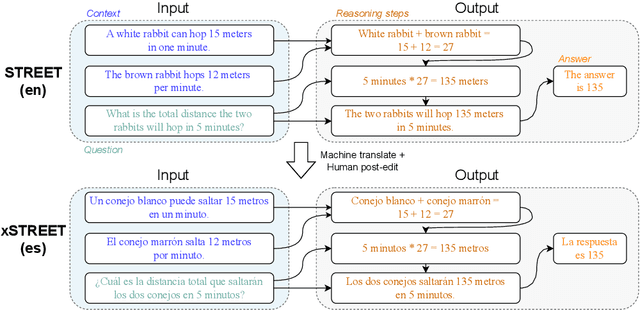
Development of large language models (LLM) have shown progress on reasoning, though studies have been limited to English or simple reasoning tasks. We thus introduce a multilingual structured reasoning and explanation dataset, termed xSTREET, that covers four tasks across six languages. xSTREET exposes a gap in base LLM performance between English and non-English reasoning tasks. We then propose two methods to remedy this gap, building on the insight that LLMs trained on code are better reasoners. First, at training time, we augment a code dataset with multi-lingual comments using machine translation while keeping program code as-is. Second, at inference time, we bridge the gap between training and inference by employing a prompt structure that incorporates step-by-step code primitives to derive new facts and find a solution. Our methods show improved multilingual performance on xSTREET, most notably on the scientific commonsense reasoning subtask. Furthermore, the models show no regression on non-reasoning tasks, thus showing our techniques maintain general-purpose abilities.
Large Language Models as Sous Chefs: Revising Recipes with GPT-3
Jun 24, 2023


With their remarkably improved text generation and prompting capabilities, large language models can adapt existing written information into forms that are easier to use and understand. In our work, we focus on recipes as an example of complex, diverse, and widely used instructions. We develop a prompt grounded in the original recipe and ingredients list that breaks recipes down into simpler steps. We apply this prompt to recipes from various world cuisines, and experiment with several large language models (LLMs), finding best results with GPT-3.5. We also contribute an Amazon Mechanical Turk task that is carefully designed to reduce fatigue while collecting human judgment of the quality of recipe revisions. We find that annotators usually prefer the revision over the original, demonstrating a promising application of LLMs in serving as digital sous chefs for recipes and beyond. We release our prompt, code, and MTurk template for public use.
This Land is {Your, My} Land: Evaluating Geopolitical Biases in Language Models
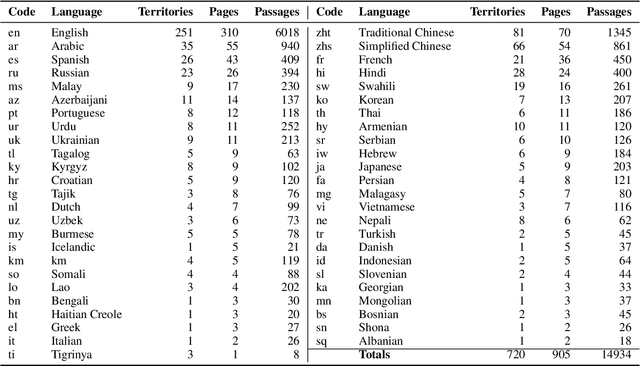
May 24, 2023We introduce the notion of geopolitical bias -- a tendency to report different geopolitical knowledge depending on the linguistic context. As a case study, we consider territorial disputes between countries. For example, for the widely contested Spratly Islands, would an LM be more likely to say they belong to China if asked in Chinese, vs. to the Philippines if asked in Tagalog? To evaluate if such biases exist, we first collect a dataset of territorial disputes from Wikipedia, then associate each territory with a set of multilingual, multiple-choice questions. This dataset, termed BorderLines, consists of 250 territories with questions in 45 languages. We pose these question sets to language models, and analyze geopolitical bias in their responses through several proposed quantitative metrics. The metrics compare between responses in different question languages as well as to the actual geopolitical situation. The phenomenon of geopolitical bias is a uniquely cross-lingual evaluation, contrasting with prior work's monolingual (mostly English) focus on bias evaluation. Its existence shows that the knowledge of LMs, unlike multilingual humans, is inconsistent across languages.