 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Context Learning: Building Trust the Right Way in LLM-Based Multi-Agent Systems
Jan 29, 2026Individual agents in multi-agent (MA) systems often lack robustness, tending to blindly conform to misleading peers. We show this weakness stems from both sycophancy and inadequate ability to evaluate peer reliability. To address this, we first formalize the learning problem of history-aware reference, introducing the historical interactions of peers as additional input, so that agents can estimate peer reliability and learn from trustworthy peers when uncertain. This shifts the task from evaluating peer reasoning quality to estimating peer reliability based on interaction history. We then develop Epistemic Context Learning (ECL): a reasoning framework that conditions predictions on explicitly-built peer profiles from history. We further optimize ECL by reinforcement learning using auxiliary rewards. Our experiments reveal that our ECL enables small models like Qwen 3-4B to outperform a history-agnostic baseline 8x its size (Qwen 3-30B) by accurately identifying reliable peers. ECL also boosts frontier models to near-perfect (100%) performance. We show that ECL generalizes well to various MA configurations and we find that trust is modeled well by LLMs, revealing a strong correlation in trust modeling accuracy and final answer quality.
Paying Less Generalization Tax: A Cross-Domain Generalization Study of RL Training for LLM Agents
Jan 26, 2026Generalist LLM agents are often post-trained on a narrow set of environments but deployed across far broader, unseen domains. In this work, we investigate the challenge of agentic post-training when the eventual test domains are unknown. Specifically, we analyze which properties of reinforcement learning (RL) environments and modeling choices have the greatest influence on out-of-domain performance. First, we identify two environment axes that strongly correlate with cross-domain generalization: (i) state information richness, i.e., the amount of information for the agent to process from the state, and (ii) planning complexity, estimated via goal reachability and trajectory length under a base policy. Notably, domain realism and text-level similarity are not the primary factors; for instance, the simple grid-world domain Sokoban leads to even stronger generalization in SciWorld than the more realistic ALFWorld. Motivated by these findings, we further show that increasing state information richness alone can already effectively improve cross-domain robustness. We propose a randomization technique, which is low-overhead and broadly applicable: add small amounts of distractive goal-irrelevant features to the state to make it richer without altering the task. Beyond environment-side properties, we also examine several modeling choices: (a) SFT warmup or mid-training helps prevent catastrophic forgetting during RL but undermines generalization to domains that are not included in the mid-training datamix; and (b) turning on step-by-step thinking during RL, while not always improving in-domain performance, plays a crucial role in preserving generalization.
Know Me, Respond to Me: Benchmarking LLMs for Dynamic User Profiling and Personalized Responses at Scale
Apr 19, 2025Large Language Models (LLMs) have emerged as personalized assistants for users across a wide range of tasks -- from offering writing support to delivering tailored recommendations or consultations. Over time, the interaction history between a user and an LLM can provide extensive information about an individual's traits and preferences. However, open questions remain on how well LLMs today can effectively leverage such history to (1) internalize the user's inherent traits and preferences, (2) track how the user profiling and preferences evolve over time, and (3) generate personalized responses accordingly in new scenarios. In this work, we introduce the PERSONAMEM benchmark. PERSONAMEM features curated user profiles with over 180 simulated user-LLM interaction histories, each containing up to 60 sessions of multi-turn conversations across 15 real-world tasks that require personalization. Given an in-situ user query, i.e. query issued by the user from the first-person perspective, we evaluate LLM chatbots' ability to identify the most suitable response according to the current state of the user's profile. We observe that current LLMs still struggle to recognize the dynamic evolution in users' profiles over time through direct prompting approaches. As a consequence, LLMs often fail to deliver responses that align with users' current situations and preferences, with frontier models such as GPT-4.1, o4-mini, GPT-4.5, o1, or Gemini-2.0 achieving only around 50% overall accuracy, suggesting room for improvement. We hope that PERSONAMEM, along with the user profile and conversation simulation pipeline, can facilitate future research in the development of truly user-aware chatbots. Code and data are available at github.com/bowen-upenn/PersonaMem.
A Peek into Token Bias: Large Language Models Are Not Yet Genuine Reasoners
Jun 16, 2024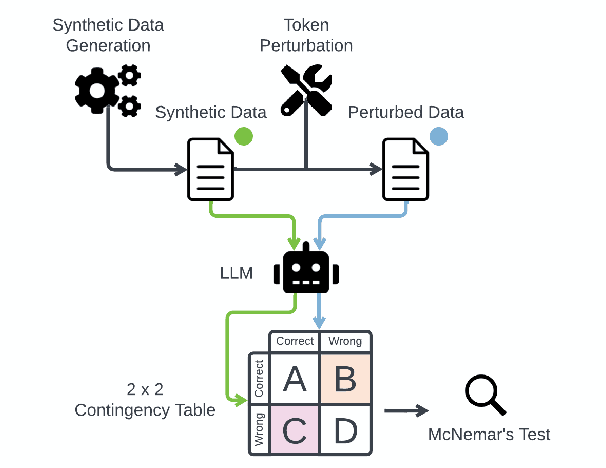
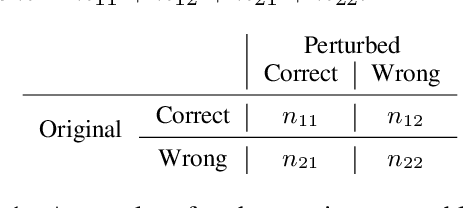

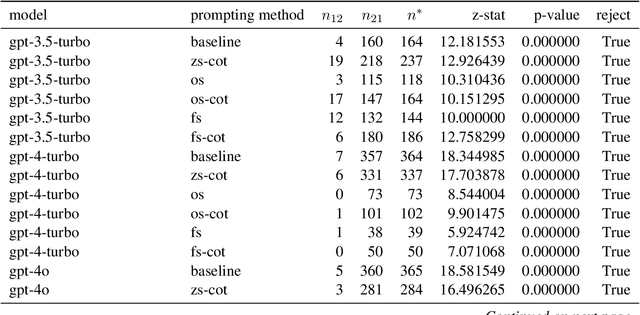
This study introduces a hypothesis-testing framework to assess whether large language models (LLMs) possess genuine reasoning abilities or primarily depend on token bias. We go beyond evaluating LLMs on accuracy; rather, we aim to investigate their token bias in solving logical reasoning tasks. Specifically, we develop carefully controlled synthetic datasets, featuring conjunction fallacy and syllogistic problems. Our framework outlines a list of hypotheses where token biases are readily identifiable, with all null hypotheses assuming genuine reasoning capabilities of LLMs. The findings in this study suggest, with statistical guarantee, that most LLMs still struggle with logical reasoning. While they may perform well on classic problems, their success largely depends on recognizing superficial patterns with strong token bias, thereby raising concerns about their actual reasoning and generalization abilities.