 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMPath: Language-Mediated Priors and Path Generation for Aerial Exploration
May 13, 2026Traditional autonomous UAV search missions rely on geometric coverage patterns that ignore the semantic context of the target, leading to significant time waste in large-scale environments. In this paper we present LMPath, a pipeline for generating language-mediated exploration priors for Unmanned Aerial Vehicle (UAV) search missions that leverages semantics. Given a basic geofence and an object of interest prompt, LMPath uses generative language models to determine what regions of the environment should contain that object and a foundation vision model ran over satellite imagery to segment sub-regions that form the exploration prior. This prior can then be used to generate UAV paths with various objectives, such as minimizing the expected time to locate the object of interest, maximizing the probability that the object is found given a limited travel distance, or narrowing down the search space to sub-regions that are most likely to contain the object. To demonstrate it's capabilities, we used LMPath to generate various UAV paths and ran them using a real UAV over large-scale environments. We also ran simulations to demonstrate how paths generated using LMPath outperform traditional path planning approaches for search missions.
One Model, All Roles: Multi-Turn, Multi-Agent Self-Play Reinforcement Learning for Conversational Social Intelligence
Feb 03, 2026This paper introduces OMAR: One Model, All Roles, a reinforcement learning framework that enables AI to develop social intelligence through multi-turn, multi-agent conversational self-play. Unlike traditional paradigms that rely on static, single-turn optimizations, OMAR allows a single model to role-play all participants in a conversation simultaneously, learning to achieve long-term goals and complex social norms directly from dynamic social interaction. To ensure training stability across long dialogues, we implement a hierarchical advantage estimation that calculates turn-level and token-level advantages. Evaluations in the SOTOPIA social environment and Werewolf strategy games show that our trained models develop fine-grained, emergent social intelligence, such as empathy, persuasion, and compromise seeking, demonstrating the effectiveness of learning collaboration even under competitive scenarios. While we identify practical challenges like reward hacking, our results show that rich social intelligence can emerge without human supervision. We hope this work incentivizes further research on AI social intelligence in group conversations.
A Multi-Robot Platform for Robotic Triage Combining Onboard Sensing and Foundation Models
Dec 09, 2025
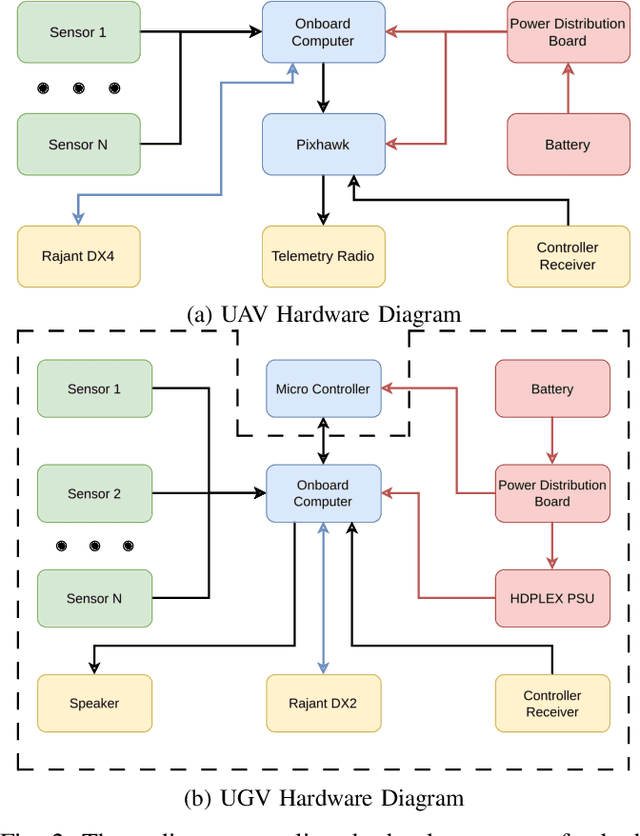
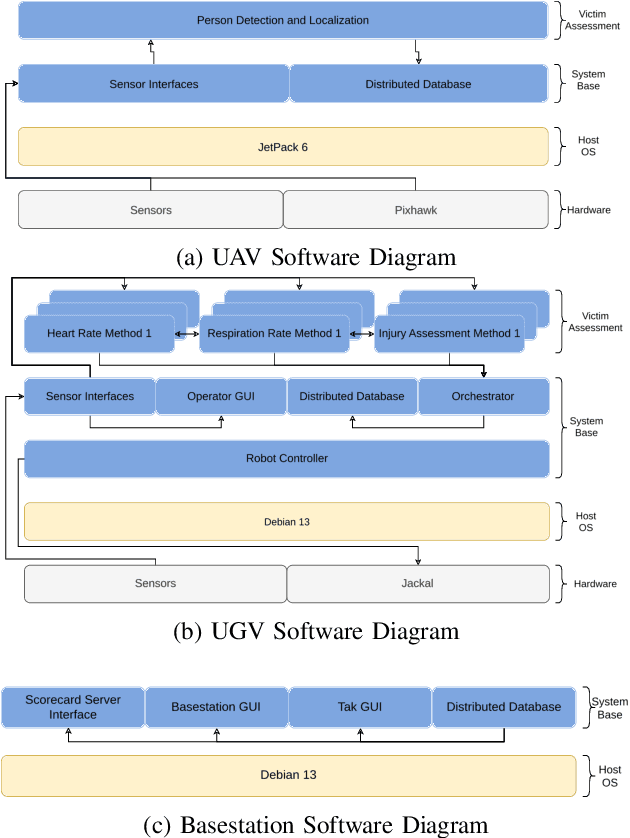
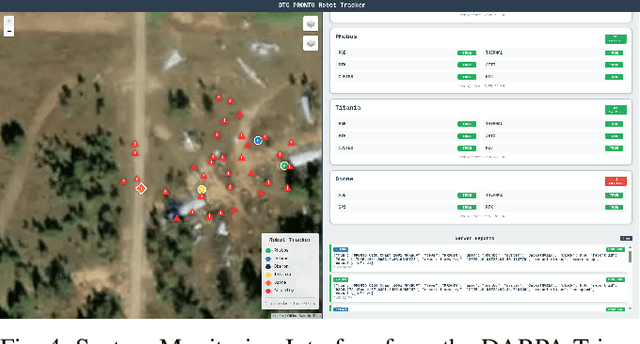
This report presents a heterogeneous robotic system designed for remote primary triage in mass-casualty incidents (MCIs). The system employs a coordinated air-ground team of unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs) to locate victims, assess their injuries, and prioritize medical assistance without risking the lives of first responders. The UAV identify and provide overhead views of casualties, while UGVs equipped with specialized sensors measure vital signs and detect and localize physical injuries. Unlike previous work that focused on exploration or limited medical evaluation, this system addresses the complete triage process: victim localization, vital sign measurement, injury severity classification, mental status assessment, and data consolidation for first responders. Developed as part of the DARPA Triage Challenge, this approach demonstrates how multi-robot systems can augment human capabilities in disaster response scenarios to maximize lives saved.
Deploying Foundation Model-Enabled Air and Ground Robots in the Field: Challenges and Opportunities
May 14, 2025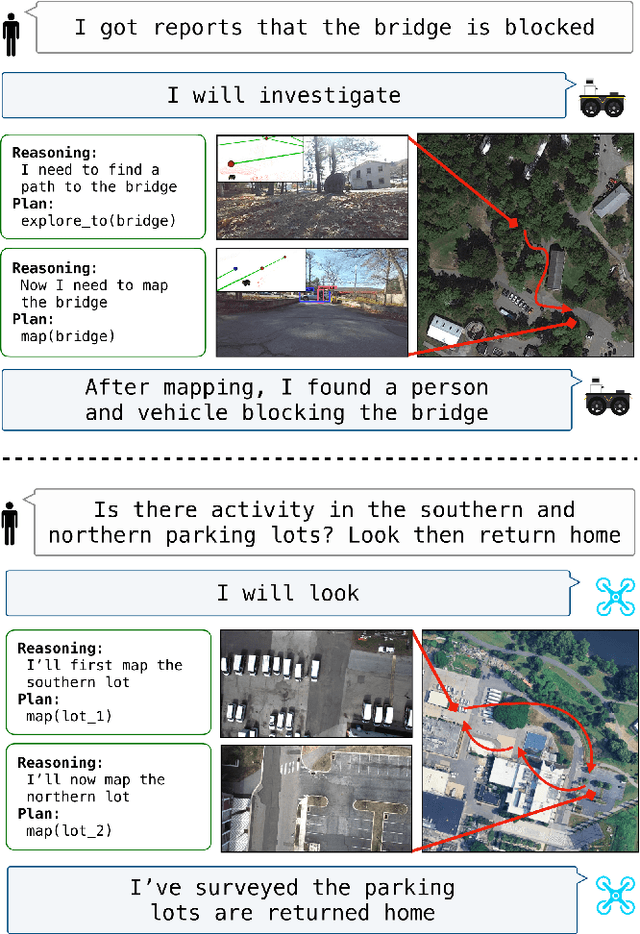
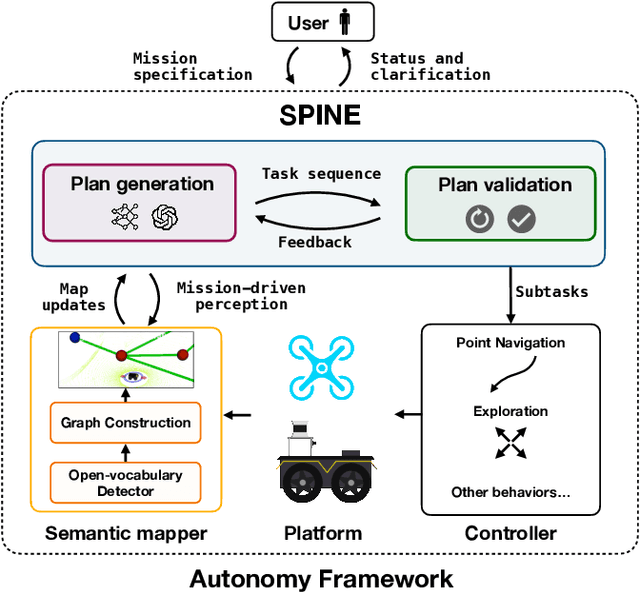

The integration of foundation models (FMs) into robotics has enabled robots to understand natural language and reason about the semantics in their environments. However, existing FM-enabled robots primary operate in closed-world settings, where the robot is given a full prior map or has a full view of its workspace. This paper addresses the deployment of FM-enabled robots in the field, where missions often require a robot to operate in large-scale and unstructured environments. To effectively accomplish these missions, robots must actively explore their environments, navigate obstacle-cluttered terrain, handle unexpected sensor inputs, and operate with compute constraints. We discuss recent deployments of SPINE, our LLM-enabled autonomy framework, in field robotic settings. To the best of our knowledge, we present the first demonstration of large-scale LLM-enabled robot planning in unstructured environments with several kilometers of missions. SPINE is agnostic to a particular LLM, which allows us to distill small language models capable of running onboard size, weight and power (SWaP) limited platforms. Via preliminary model distillation work, we then present the first language-driven UAV planner using on-device language models. We conclude our paper by proposing several promising directions for future research.
Air-Ground Collaboration for Language-Specified Missions in Unknown Environments
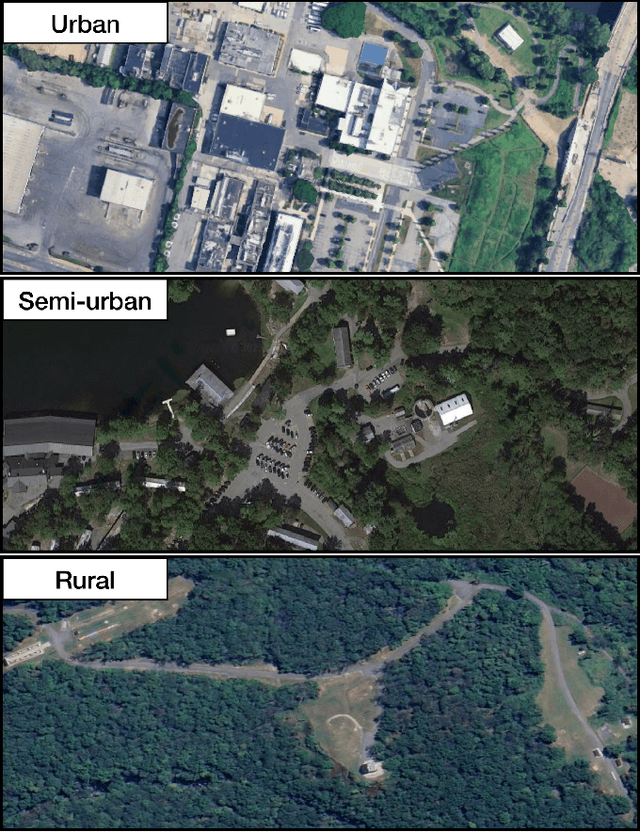
May 14, 2025As autonomous robotic systems become increasingly mature, users will want to specify missions at the level of intent rather than in low-level detail. Language is an expressive and intuitive medium for such mission specification. However, realizing language-guided robotic teams requires overcoming significant technical hurdles. Interpreting and realizing language-specified missions requires advanced semantic reasoning. Successful heterogeneous robots must effectively coordinate actions and share information across varying viewpoints. Additionally, communication between robots is typically intermittent, necessitating robust strategies that leverage communication opportunities to maintain coordination and achieve mission objectives. In this work, we present a first-of-its-kind system where an unmanned aerial vehicle (UAV) and an unmanned ground vehicle (UGV) are able to collaboratively accomplish missions specified in natural language while reacting to changes in specification on the fly. We leverage a Large Language Model (LLM)-enabled planner to reason over semantic-metric maps that are built online and opportunistically shared between an aerial and a ground robot. We consider task-driven navigation in urban and rural areas. Our system must infer mission-relevant semantics and actively acquire information via semantic mapping. In both ground and air-ground teaming experiments, we demonstrate our system on seven different natural-language specifications at up to kilometer-scale navigation.
Vysics: Object Reconstruction Under Occlusion by Fusing Vision and Contact-Rich Physics
Apr 25, 2025



We introduce Vysics, a vision-and-physics framework for a robot to build an expressive geometry and dynamics model of a single rigid body, using a seconds-long RGBD video and the robot's proprioception. While the computer vision community has built powerful visual 3D perception algorithms, cluttered environments with heavy occlusions can limit the visibility of objects of interest. However, observed motion of partially occluded objects can imply physical interactions took place, such as contact with a robot or the environment. These inferred contacts can supplement the visible geometry with "physible geometry," which best explains the observed object motion through physics. Vysics uses a vision-based tracking and reconstruction method, BundleSDF, to estimate the trajectory and the visible geometry from an RGBD video, and an odometry-based model learning method, Physics Learning Library (PLL), to infer the "physible" geometry from the trajectory through implicit contact dynamics optimization. The visible and "physible" geometries jointly factor into optimizing a signed distance function (SDF) to represent the object shape. Vysics does not require pretraining, nor tactile or force sensors. Compared with vision-only methods, Vysics yields object models with higher geometric accuracy and better dynamics prediction in experiments where the object interacts with the robot and the environment under heavy occlusion. Project page: https://vysics-vision-and-physics.github.io/
A RAG-Based Multi-Agent LLM System for Natural Hazard Resilience and Adaptation
Apr 24, 2025Large language models (LLMs) are a transformational capability at the frontier of artificial intelligence and machine learning that can support decision-makers in addressing pressing societal challenges such as extreme natural hazard events. As generalized models, LLMs often struggle to provide context-specific information, particularly in areas requiring specialized knowledge. In this work we propose a retrieval-augmented generation (RAG)-based multi-agent LLM system to support analysis and decision-making in the context of natural hazards and extreme weather events. As a proof of concept, we present WildfireGPT, a specialized system focused on wildfire hazards. The architecture employs a user-centered, multi-agent design to deliver tailored risk insights across diverse stakeholder groups. By integrating natural hazard and extreme weather projection data, observational datasets, and scientific literature through an RAG framework, the system ensures both the accuracy and contextual relevance of the information it provides. Evaluation across ten expert-led case studies demonstrates that WildfireGPT significantly outperforms existing LLM-based solutions for decision support.
Know Me, Respond to Me: Benchmarking LLMs for Dynamic User Profiling and Personalized Responses at Scale
Apr 19, 2025Large Language Models (LLMs) have emerged as personalized assistants for users across a wide range of tasks -- from offering writing support to delivering tailored recommendations or consultations. Over time, the interaction history between a user and an LLM can provide extensive information about an individual's traits and preferences. However, open questions remain on how well LLMs today can effectively leverage such history to (1) internalize the user's inherent traits and preferences, (2) track how the user profiling and preferences evolve over time, and (3) generate personalized responses accordingly in new scenarios. In this work, we introduce the PERSONAMEM benchmark. PERSONAMEM features curated user profiles with over 180 simulated user-LLM interaction histories, each containing up to 60 sessions of multi-turn conversations across 15 real-world tasks that require personalization. Given an in-situ user query, i.e. query issued by the user from the first-person perspective, we evaluate LLM chatbots' ability to identify the most suitable response according to the current state of the user's profile. We observe that current LLMs still struggle to recognize the dynamic evolution in users' profiles over time through direct prompting approaches. As a consequence, LLMs often fail to deliver responses that align with users' current situations and preferences, with frontier models such as GPT-4.1, o4-mini, GPT-4.5, o1, or Gemini-2.0 achieving only around 50% overall accuracy, suggesting room for improvement. We hope that PERSONAMEM, along with the user profile and conversation simulation pipeline, can facilitate future research in the development of truly user-aware chatbots. Code and data are available at github.com/bowen-upenn/PersonaMem.
EvMAPPER: High Altitude Orthomapping with Event Cameras
Sep 26, 2024



Traditionally, unmanned aerial vehicles (UAVs) rely on CMOS-based cameras to collect images about the world below. One of the most successful applications of UAVs is to generate orthomosaics or orthomaps, in which a series of images are integrated together to develop a larger map. However, the use of CMOS-based cameras with global or rolling shutters mean that orthomaps are vulnerable to challenging light conditions, motion blur, and high-speed motion of independently moving objects under the camera. Event cameras are less sensitive to these issues, as their pixels are able to trigger asynchronously on brightness changes. This work introduces the first orthomosaic approach using event cameras. In contrast to existing methods relying only on CMOS cameras, our approach enables map generation even in challenging light conditions, including direct sunlight and after sunset.
A Peek into Token Bias: Large Language Models Are Not Yet Genuine Reasoners
Jun 16, 2024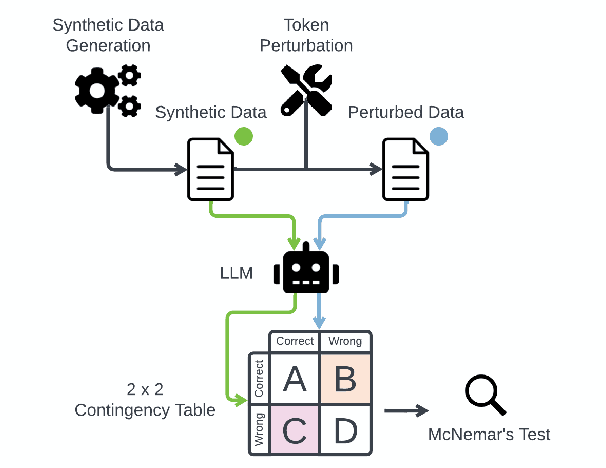
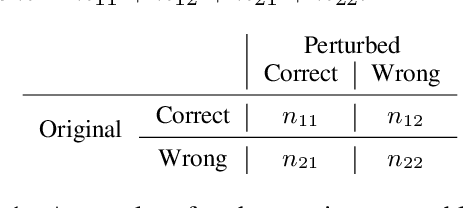

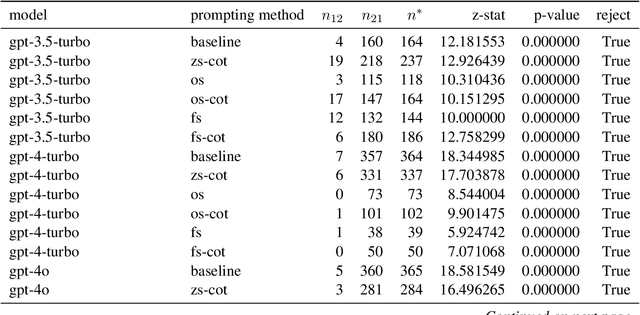
This study introduces a hypothesis-testing framework to assess whether large language models (LLMs) possess genuine reasoning abilities or primarily depend on token bias. We go beyond evaluating LLMs on accuracy; rather, we aim to investigate their token bias in solving logical reasoning tasks. Specifically, we develop carefully controlled synthetic datasets, featuring conjunction fallacy and syllogistic problems. Our framework outlines a list of hypotheses where token biases are readily identifiable, with all null hypotheses assuming genuine reasoning capabilities of LLMs. The findings in this study suggest, with statistical guarantee, that most LLMs still struggle with logical reasoning. While they may perform well on classic problems, their success largely depends on recognizing superficial patterns with strong token bias, thereby raising concerns about their actual reasoning and generalization abilities.