 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Robot Platform for Robotic Triage Combining Onboard Sensing and Foundation Models
Dec 09, 2025
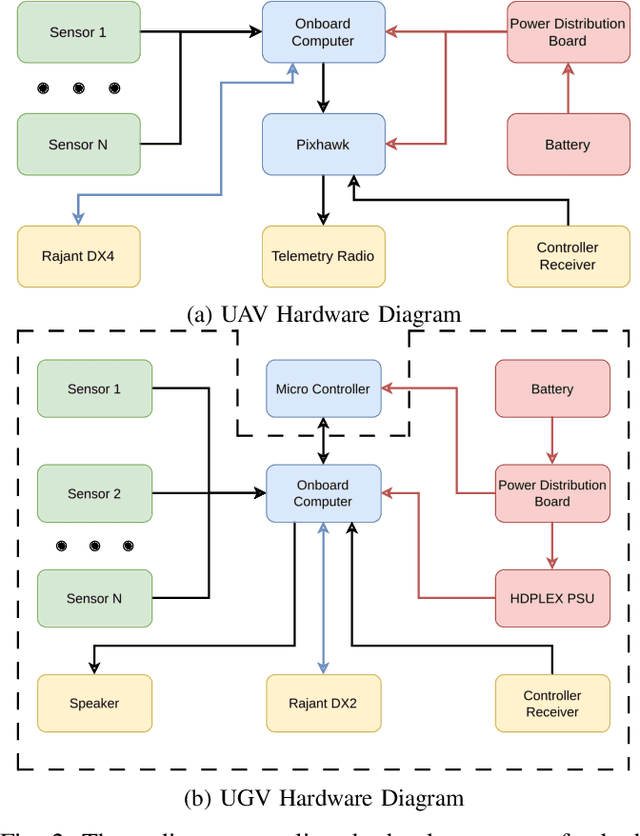
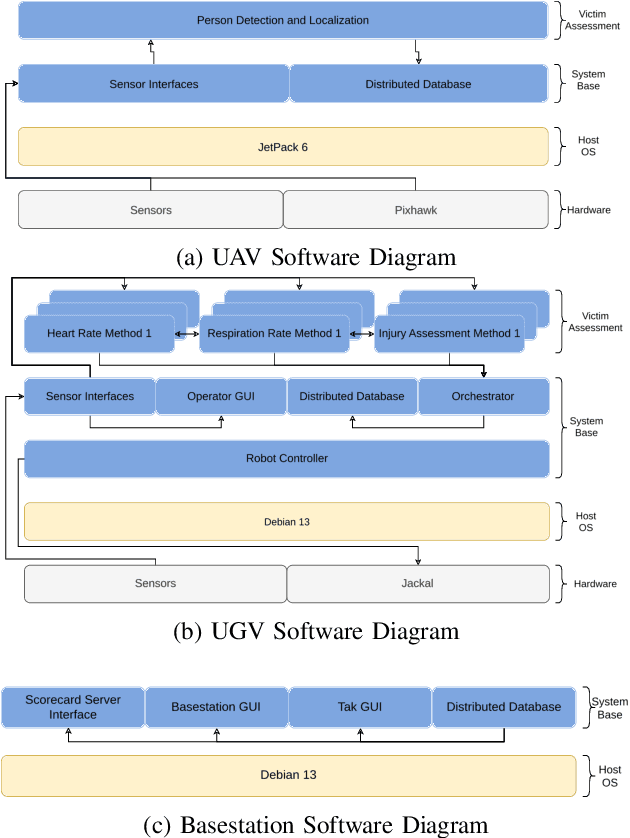
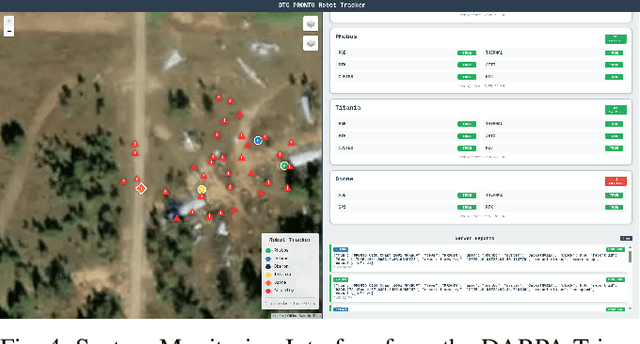
This report presents a heterogeneous robotic system designed for remote primary triage in mass-casualty incidents (MCIs). The system employs a coordinated air-ground team of unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs) to locate victims, assess their injuries, and prioritize medical assistance without risking the lives of first responders. The UAV identify and provide overhead views of casualties, while UGVs equipped with specialized sensors measure vital signs and detect and localize physical injuries. Unlike previous work that focused on exploration or limited medical evaluation, this system addresses the complete triage process: victim localization, vital sign measurement, injury severity classification, mental status assessment, and data consolidation for first responders. Developed as part of the DARPA Triage Challenge, this approach demonstrates how multi-robot systems can augment human capabilities in disaster response scenarios to maximize lives saved.
EvMAPPER: High Altitude Orthomapping with Event Cameras
Sep 26, 2024



Traditionally, unmanned aerial vehicles (UAVs) rely on CMOS-based cameras to collect images about the world below. One of the most successful applications of UAVs is to generate orthomosaics or orthomaps, in which a series of images are integrated together to develop a larger map. However, the use of CMOS-based cameras with global or rolling shutters mean that orthomaps are vulnerable to challenging light conditions, motion blur, and high-speed motion of independently moving objects under the camera. Event cameras are less sensitive to these issues, as their pixels are able to trigger asynchronously on brightness changes. This work introduces the first orthomosaic approach using event cameras. In contrast to existing methods relying only on CMOS cameras, our approach enables map generation even in challenging light conditions, including direct sunlight and after sunset.
Motion-prior Contrast Maximization for Dense Continuous-Time Motion Estimation
Jul 15, 2024Current optical flow and point-tracking methods rely heavily on synthetic datasets. Event cameras are novel vision sensors with advantages in challenging visual conditions, but state-of-the-art frame-based methods cannot be easily adapted to event data due to the limitations of current event simulators. We introduce a novel self-supervised loss combining the Contrast Maximization framework with a non-linear motion prior in the form of pixel-level trajectories and propose an efficient solution to solve the high-dimensional assignment problem between non-linear trajectories and events. Their effectiveness is demonstrated in two scenarios: In dense continuous-time motion estimation, our method improves the zero-shot performance of a synthetically trained model on the real-world dataset EVIMO2 by 29%. In optical flow estimation, our method elevates a simple UNet to achieve state-of-the-art performance among self-supervised methods on the DSEC optical flow benchmark. Our code is available at https://github.com/tub-rip/MotionPriorCMax.
* 24 pages, 8 figures, 8 tables, Project Page: https://github.com/tub-rip/MotionPriorCMax
Event-based Continuous Color Video Decompression from Single Frames
Nov 30, 2023



We present ContinuityCam, a novel approach to generate a continuous video from a single static RGB image, using an event camera. Conventional cameras struggle with high-speed motion capture due to bandwidth and dynamic range limitations. Event cameras are ideal sensors to solve this problem because they encode compressed change information at high temporal resolution. In this work, we propose a novel task called event-based continuous color video decompression, pairing single static color frames and events to reconstruct temporally continuous videos. Our approach combines continuous long-range motion modeling with a feature-plane-based synthesis neural integration model, enabling frame prediction at arbitrary times within the events. Our method does not rely on additional frames except for the initial image, increasing, thus, the robustness to sudden light changes, minimizing the prediction latency, and decreasing the bandwidth requirement. We introduce a novel single objective beamsplitter setup that acquires aligned images and events and a novel and challenging Event Extreme Decompression Dataset (E2D2) that tests the method in various lighting and motion profiles. We thoroughly evaluate our method through benchmarking reconstruction as well as various downstream tasks. Our approach significantly outperforms the event- and image- based baselines in the proposed task.
EvAC3D: From Event-based Apparent Contours to 3D Models via Continuous Visual Hulls
Apr 11, 20233D reconstruction from multiple views is a successful computer vision field with multiple deployments in applications. State of the art is based on traditional RGB frames that enable optimization of photo-consistency cross views. In this paper, we study the problem of 3D reconstruction from event-cameras, motivated by the advantages of event-based cameras in terms of low power and latency as well as by the biological evidence that eyes in nature capture the same data and still perceive well 3D shape. The foundation of our hypothesis that 3D reconstruction is feasible using events lies in the information contained in the occluding contours and in the continuous scene acquisition with events. We propose Apparent Contour Events (ACE), a novel event-based representation that defines the geometry of the apparent contour of an object. We represent ACE by a spatially and temporally continuous implicit function defined in the event x-y-t space. Furthermore, we design a novel continuous Voxel Carving algorithm enabled by the high temporal resolution of the Apparent Contour Events. To evaluate the performance of the method, we collect MOEC-3D, a 3D event dataset of a set of common real-world objects. We demonstrate the ability of EvAC3D to reconstruct high-fidelity mesh surfaces from real event sequences while allowing the refinement of the 3D reconstruction for each individual event.
Semantic keypoint-based pose estimation from single RGB frames
Apr 12, 2022


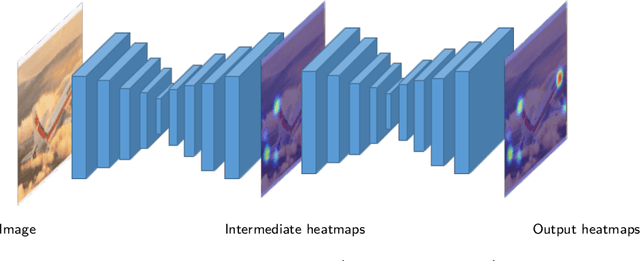
This paper presents an approach to estimating the continuous 6-DoF pose of an object from a single RGB image. The approach combines semantic keypoints predicted by a convolutional network (convnet) with a deformable shape model. Unlike prior investigators, we are agnostic to whether the object is textured or textureless, as the convnet learns the optimal representation from the available training-image data. Furthermore, the approach can be applied to instance- and class-based pose recovery. Additionally, we accompany our main pipeline with a technique for semi-automatic data generation from unlabeled videos. This procedure allows us to train the learnable components of our method with minimal manual intervention in the labeling process. Empirically, we show that our approach can accurately recover the 6-DoF object pose for both instance- and class-based scenarios even against a cluttered background. We apply our approach both to several, existing, large-scale datasets - including PASCAL3D+, LineMOD-Occluded, YCB-Video, and TUD-Light - and, using our labeling pipeline, to a new dataset with novel object classes that we introduce here. Extensive empirical evaluations show that our approach is able to provide pose estimation results comparable to the state of the art.
* https://sites.google.com/view/rcta-object-keypoints-dataset/home. arXiv admin note: substantial text overlap with arXiv:1703.04670
Spike-FlowNet: Event-based Optical Flow Estimation with Energy-Efficient Hybrid Neural Networks
Mar 14, 2020
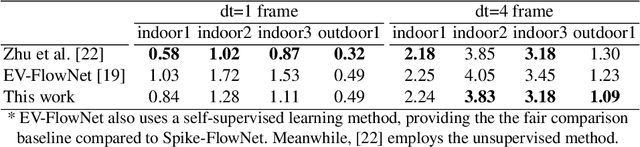

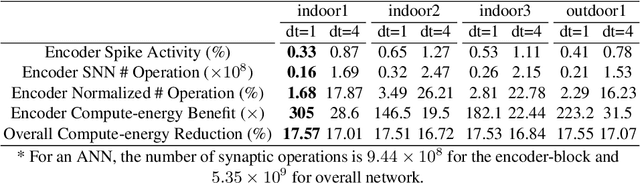
Event-based cameras display great potential for a variety of conditions such as high-speed motion detection and enabling navigation in low-light environments where conventional frame-based cameras suffer critically. This is attributed to their high temporal resolution, high dynamic range, and low-power consumption. However, conventional computer vision methods as well as deep Analog Neural Networks (ANNs) are not suited to work well with the asynchronous and discrete nature of event camera outputs. Spiking Neural Networks (SNNs) serve as ideal paradigms to handle event camera outputs, but deep SNNs suffer in terms of performance due to spike vanishing phenomenon. To overcome these issues, we present Spike-FlowNet, a deep hybrid neural network architecture integrating SNNs and ANNs for efficiently estimating optical flow from sparse event camera outputs without sacrificing the performance. The network is end-to-end trained with self-supervised learning on Multi-Vehicle Stereo Event Camera (MVSEC) dataset. Spike-FlowNet outperforms its corresponding ANN-based method in terms of the optical flow prediction capability while providing significant computational efficiency.
Minibatch Processing in Spiking Neural Networks
Sep 05, 2019
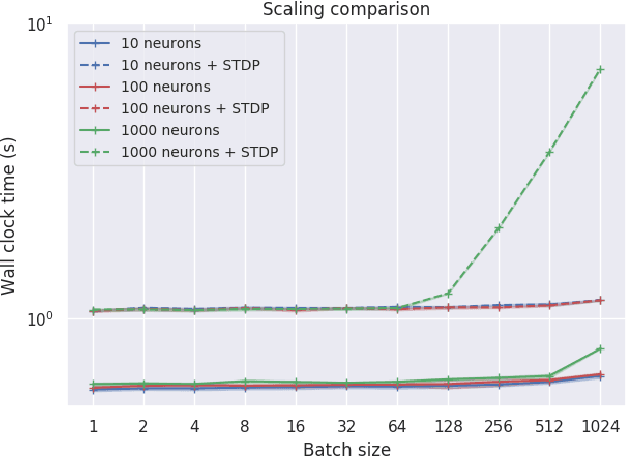

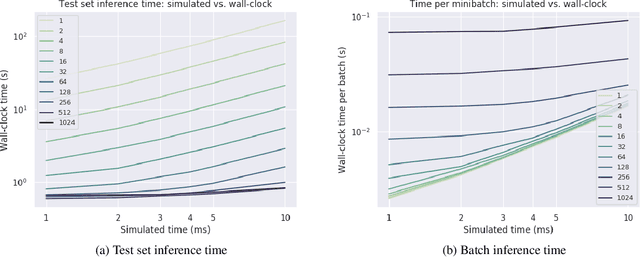
Spiking neural networks (SNNs) are a promising candidate for biologically-inspired and energy efficient computation. However, their simulation is notoriously time consuming, and may be seen as a bottleneck in developing competitive training methods with potential deployment on neuromorphic hardware platforms. To address this issue, we provide an implementation of mini-batch processing applied to clock-based SNN simulation, leading to drastically increased data throughput. To our knowledge, this is the first general-purpose implementation of mini-batch processing in a spiking neural networks simulator, which works with arbitrary neuron and synapse models. We demonstrate nearly constant-time scaling with batch size on a simulation setup (up to GPU memory limits), and showcase the effectiveness of large batch sizes in two SNN application domains, resulting in $\approx$880X and $\approx$24X reductions in wall-clock time respectively. Different parameter reduction techniques are shown to produce different learning outcomes in a simulation of networks trained with spike-timing-dependent plasticity. Machine learning practitioners and biological modelers alike may benefit from the drastically reduced simulation time and increased iteration speed this method enables. Code to reproduce the benchmarks and experimental findings in this paper can be found at https://github.com/djsaunde/snn-minibatch.
Unsupervised Event-based Learning of Optical Flow, Depth, and Egomotion
Dec 19, 2018
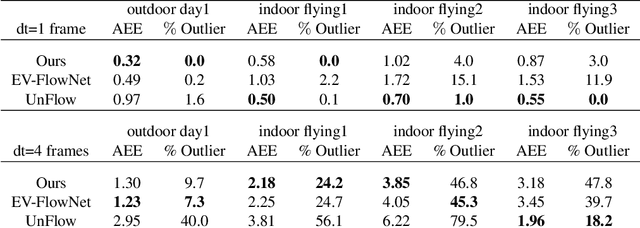
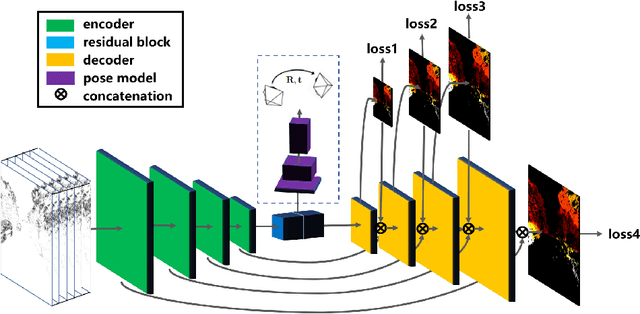
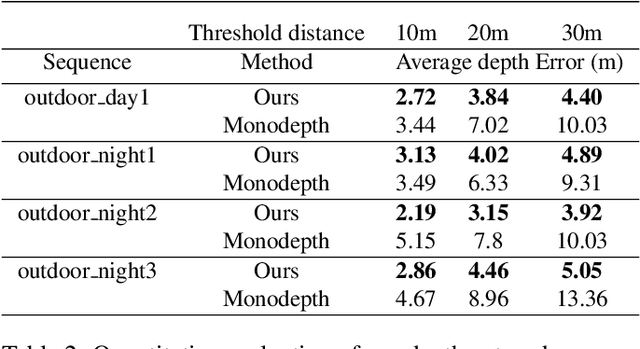
In this work, we propose a novel framework for unsupervised learning for event cameras that learns motion information from only the event stream. In particular, we propose an input representation of the events in the form of a discretized volume that maintains the temporal distribution of the events, which we pass through a neural network to predict the motion of the events. This motion is used to attempt to remove any motion blur in the event image. We then propose a loss function applied to the motion compensated event image that measures the motion blur in this image. We train two networks with this framework, one to predict optical flow, and one to predict egomotion and depths, and evaluate these networks on the Multi Vehicle Stereo Event Camera dataset, along with qualitative results from a variety of different scenes.
EV-FlowNet: Self-Supervised Optical Flow Estimation for Event-based Cameras
Aug 13, 2018

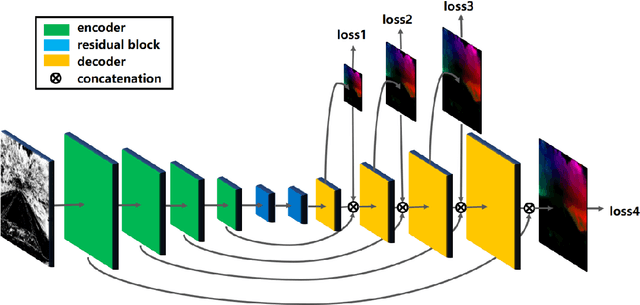

Event-based cameras have shown great promise in a variety of situations where frame based cameras suffer, such as high speed motions and high dynamic range scenes. However, developing algorithms for event measurements requires a new class of hand crafted algorithms. Deep learning has shown great success in providing model free solutions to many problems in the vision community, but existing networks have been developed with frame based images in mind, and there does not exist the wealth of labeled data for events as there does for images for supervised training. To these points, we present EV-FlowNet, a novel self-supervised deep learning pipeline for optical flow estimation for event based cameras. In particular, we introduce an image based representation of a given event stream, which is fed into a self-supervised neural network as the sole input. The corresponding grayscale images captured from the same camera at the same time as the events are then used as a supervisory signal to provide a loss function at training time, given the estimated flow from the network. We show that the resulting network is able to accurately predict optical flow from events only in a variety of different scenes, with performance competitive to image based networks. This method not only allows for accurate estimation of dense optical flow, but also provides a framework for the transfer of other self-supervised methods to the event-based domain.