 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace2Scene: Using Facial Degradation as an Oracle for Diffusion-Based Scene Restoration
Mar 17, 2026Recent advances in image restoration have enabled high-fidelity recovery of faces from degraded inputs using reference-based face restoration models (Ref-FR). However, such methods focus solely on facial regions, neglecting degradation across the full scene, including body and background, which limits practical usability. Meanwhile, full-scene restorers often ignore degradation cues entirely, leading to underdetermined predictions and visual artifacts. In this work, we propose Face2Scene, a two-stage restoration framework that leverages the face as a perceptual oracle to estimate degradation and guide the restoration of the entire image. Given a degraded image and one or more identity references, we first apply a Ref-FR model to reconstruct high-quality facial details. From the restored-degraded face pair, we extract a face-derived degradation code that captures degradation attributes (e.g., noise, blur, compression), which is then transformed into multi-scale degradation-aware tokens. These tokens condition a diffusion model to restore the full scene in a single step, including the body and background. Extensive experiments demonstrate the superior effectiveness of the proposed method compared to state-of-the-art methods.
Learn Your Scales: Towards Scale-Consistent Generative Novel View Synthesis
Mar 19, 2025Conventional depth-free multi-view datasets are captured using a moving monocular camera without metric calibration. The scales of camera positions in this monocular setting are ambiguous. Previous methods have acknowledged scale ambiguity in multi-view data via various ad-hoc normalization pre-processing steps, but have not directly analyzed the effect of incorrect scene scales on their application. In this paper, we seek to understand and address the effect of scale ambiguity when used to train generative novel view synthesis methods (GNVS). In GNVS, new views of a scene or object can be minimally synthesized given a single image and are, thus, unconstrained, necessitating the use of generative methods. The generative nature of these models captures all aspects of uncertainty, including any uncertainty of scene scales, which act as nuisance variables for the task. We study the effect of scene scale ambiguity in GNVS when sampled from a single image by isolating its effect on the resulting models and, based on these intuitions, define new metrics that measure the scale inconsistency of generated views. We then propose a framework to estimate scene scales jointly with the GNVS model in an end-to-end fashion. Empirically, we show that our method reduces the scale inconsistency of generated views without the complexity or downsides of previous scale normalization methods. Further, we show that removing this ambiguity improves generated image quality of the resulting GNVS model.
Revisiting Image Fusion for Multi-Illuminant White-Balance Correction
Mar 18, 2025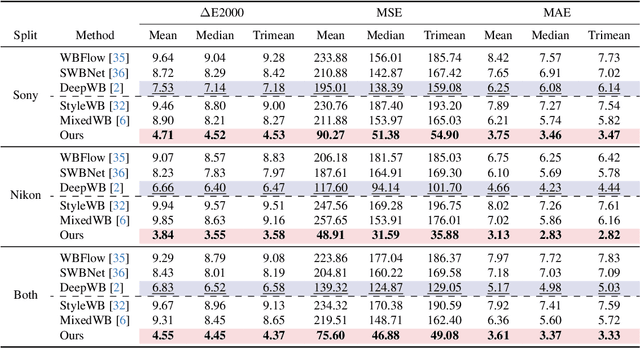

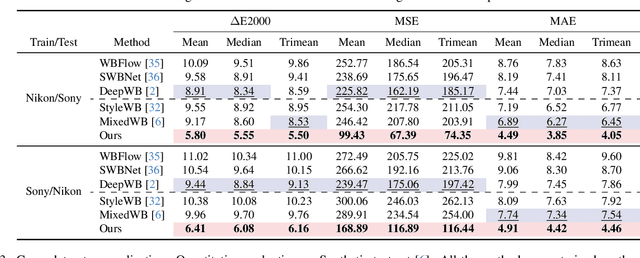
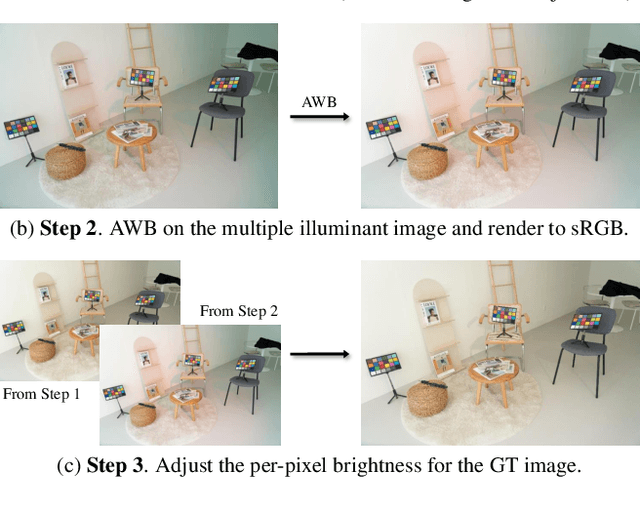
White balance (WB) correction in scenes with multiple illuminants remains a persistent challenge in computer vision. Recent methods explored fusion-based approaches, where a neural network linearly blends multiple sRGB versions of an input image, each processed with predefined WB presets. However, we demonstrate that these methods are suboptimal for common multi-illuminant scenarios. Additionally, existing fusion-based methods rely on sRGB WB datasets lacking dedicated multi-illuminant images, limiting both training and evaluation. To address these challenges, we introduce two key contributions. First, we propose an efficient transformer-based model that effectively captures spatial dependencies across sRGB WB presets, substantially improving upon linear fusion techniques. Second, we introduce a large-scale multi-illuminant dataset comprising over 16,000 sRGB images rendered with five different WB settings, along with WB-corrected images. Our method achieves up to 100\% improvement over existing techniques on our new multi-illuminant image fusion dataset.
Geometry-Aware Diffusion Models for Multiview Scene Inpainting
Feb 18, 2025In this paper, we focus on 3D scene inpainting, where parts of an input image set, captured from different viewpoints, are masked out. The main challenge lies in generating plausible image completions that are geometrically consistent across views. Most recent work addresses this challenge by combining generative models with a 3D radiance field to fuse information across viewpoints. However, a major drawback of these methods is that they often produce blurry images due to the fusion of inconsistent cross-view images. To avoid blurry inpaintings, we eschew the use of an explicit or implicit radiance field altogether and instead fuse cross-view information in a learned space. In particular, we introduce a geometry-aware conditional generative model, capable of inpainting multi-view consistent images based on both geometric and appearance cues from reference images. A key advantage of our approach over existing methods is its unique ability to inpaint masked scenes with a limited number of views (i.e., few-view inpainting), whereas previous methods require relatively large image sets for their 3D model fitting step. Empirically, we evaluate and compare our scene-centric inpainting method on two datasets, SPIn-NeRF and NeRFiller, which contain images captured at narrow and wide baselines, respectively, and achieve state-of-the-art 3D inpainting performance on both. Additionally, we demonstrate the efficacy of our approach in the few-view setting compared to prior methods.
Visual Concept Connectome (VCC): Open World Concept Discovery and their Interlayer Connections in Deep Models
Apr 10, 2024



Understanding what deep network models capture in their learned representations is a fundamental challenge in computer vision. We present a new methodology to understanding such vision models, the Visual Concept Connectome (VCC), which discovers human interpretable concepts and their interlayer connections in a fully unsupervised manner. Our approach simultaneously reveals fine-grained concepts at a layer, connection weightings across all layers and is amendable to global analysis of network structure (e.g., branching pattern of hierarchical concept assemblies). Previous work yielded ways to extract interpretable concepts from single layers and examine their impact on classification, but did not afford multilayer concept analysis across an entire network architecture. Quantitative and qualitative empirical results show the effectiveness of VCCs in the domain of image classification. Also, we leverage VCCs for the application of failure mode debugging to reveal where mistakes arise in deep networks.
PolyOculus: Simultaneous Multi-view Image-based Novel View Synthesis
Feb 28, 2024
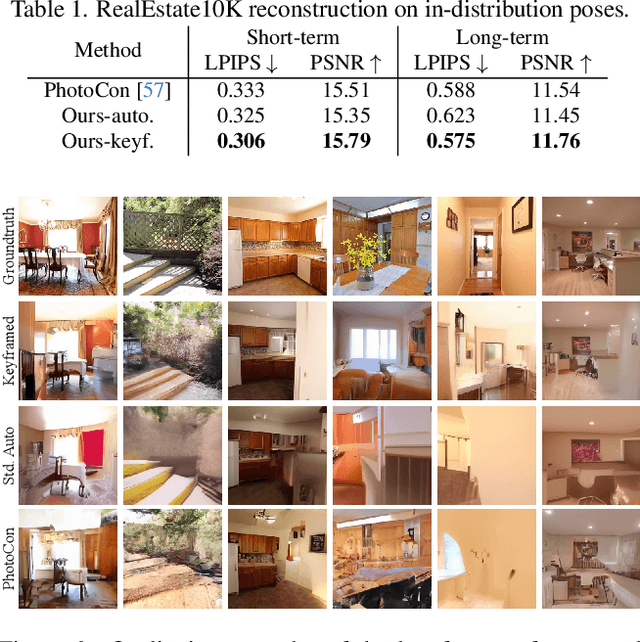
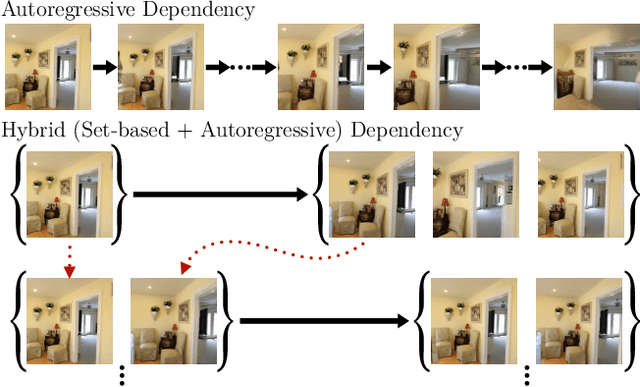

This paper considers the problem of generative novel view synthesis (GNVS), generating novel, plausible views of a scene given a limited number of known views. Here, we propose a set-based generative model that can simultaneously generate multiple, self-consistent new views, conditioned on any number of known views. Our approach is not limited to generating a single image at a time and can condition on zero, one, or more views. As a result, when generating a large number of views, our method is not restricted to a low-order autoregressive generation approach and is better able to maintain generated image quality over large sets of images. We evaluate the proposed model on standard NVS datasets and show that it outperforms the state-of-the-art image-based GNVS baselines. Further, we show that the model is capable of generating sets of camera views that have no natural sequential ordering, like loops and binocular trajectories, and significantly outperforms other methods on such tasks.
Understanding Video Transformers via Universal Concept Discovery
Jan 19, 2024This paper studies the problem of concept-based interpretability of transformer representations for videos. Concretely, we seek to explain the decision-making process of video transformers based on high-level, spatiotemporal concepts that are automatically discovered. Prior research on concept-based interpretability has concentrated solely on image-level tasks. Comparatively, video models deal with the added temporal dimension, increasing complexity and posing challenges in identifying dynamic concepts over time. In this work, we systematically address these challenges by introducing the first Video Transformer Concept Discovery (VTCD) algorithm. To this end, we propose an efficient approach for unsupervised identification of units of video transformer representations - concepts, and ranking their importance to the output of a model. The resulting concepts are highly interpretable, revealing spatio-temporal reasoning mechanisms and object-centric representations in unstructured video models. Performing this analysis jointly over a diverse set of supervised and self-supervised representations, we discover that some of these mechanism are universal in video transformers. Finally, we demonstrate that VTCDcan be used to improve model performance for fine-grained tasks.
Reconstructive Latent-Space Neural Radiance Fields for Efficient 3D Scene Representations
Oct 27, 2023



Neural Radiance Fields (NeRFs) have proven to be powerful 3D representations, capable of high quality novel view synthesis of complex scenes. While NeRFs have been applied to graphics, vision, and robotics, problems with slow rendering speed and characteristic visual artifacts prevent adoption in many use cases. In this work, we investigate combining an autoencoder (AE) with a NeRF, in which latent features (instead of colours) are rendered and then convolutionally decoded. The resulting latent-space NeRF can produce novel views with higher quality than standard colour-space NeRFs, as the AE can correct certain visual artifacts, while rendering over three times faster. Our work is orthogonal to other techniques for improving NeRF efficiency. Further, we can control the tradeoff between efficiency and image quality by shrinking the AE architecture, achieving over 13 times faster rendering with only a small drop in performance. We hope that our approach can form the basis of an efficient, yet high-fidelity, 3D scene representation for downstream tasks, especially when retaining differentiability is useful, as in many robotics scenarios requiring continual learning.
GePSAn: Generative Procedure Step Anticipation in Cooking Videos
Oct 12, 2023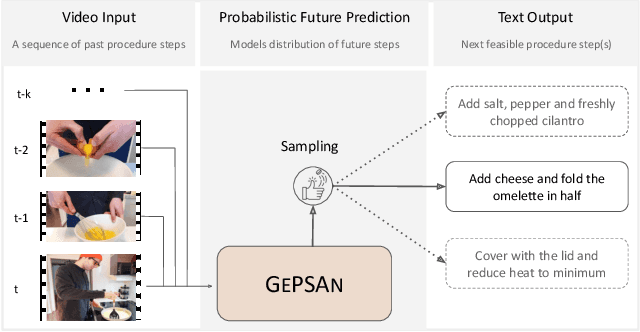
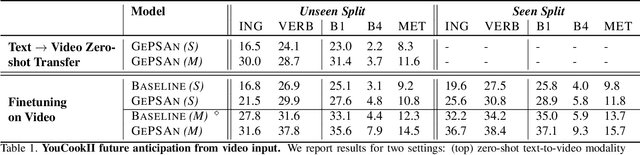
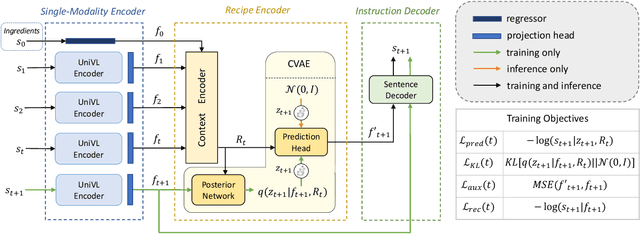
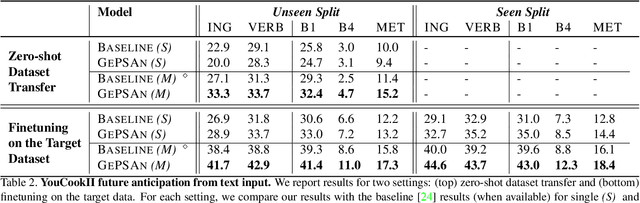
We study the problem of future step anticipation in procedural videos. Given a video of an ongoing procedural activity, we predict a plausible next procedure step described in rich natural language. While most previous work focus on the problem of data scarcity in procedural video datasets, another core challenge of future anticipation is how to account for multiple plausible future realizations in natural settings. This problem has been largely overlooked in previous work. To address this challenge, we frame future step prediction as modelling the distribution of all possible candidates for the next step. Specifically, we design a generative model that takes a series of video clips as input, and generates multiple plausible and diverse candidates (in natural language) for the next step. Following previous work, we side-step the video annotation scarcity by pretraining our model on a large text-based corpus of procedural activities, and then transfer the model to the video domain. Our experiments, both in textual and video domains, show that our model captures diversity in the next step prediction and generates multiple plausible future predictions. Moreover, our model establishes new state-of-the-art results on YouCookII, where it outperforms existing baselines on the next step anticipation. Finally, we also show that our model can successfully transfer from text to the video domain zero-shot, ie, without fine-tuning or adaptation, and produces good-quality future step predictions from video.
Dual-Camera Joint Deblurring-Denoising
Sep 16, 2023Recent image enhancement methods have shown the advantages of using a pair of long and short-exposure images for low-light photography. These image modalities offer complementary strengths and weaknesses. The former yields an image that is clean but blurry due to camera or object motion, whereas the latter is sharp but noisy due to low photon count. Motivated by the fact that modern smartphones come equipped with multiple rear-facing camera sensors, we propose a novel dual-camera method for obtaining a high-quality image. Our method uses a synchronized burst of short exposure images captured by one camera and a long exposure image simultaneously captured by another. Having a synchronized short exposure burst alongside the long exposure image enables us to (i) obtain better denoising by using a burst instead of a single image, (ii) recover motion from the burst and use it for motion-aware deblurring of the long exposure image, and (iii) fuse the two results to further enhance quality. Our method is able to achieve state-of-the-art results on synthetic dual-camera images from the GoPro dataset with five times fewer training parameters compared to the next best method. We also show that our method qualitatively outperforms competing approaches on real synchronized dual-camera captures.