 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyncLight: Controllable and Consistent Multi-View Relighting
Jan 23, 2026We present SyncLight, the first method to enable consistent, parametric relighting across multiple uncalibrated views of a static scene. While single-view relighting has advanced significantly, existing generative approaches struggle to maintain the rigorous lighting consistency essential for multi-camera broadcasts, stereoscopic cinema, and virtual production. SyncLight addresses this by enabling precise control over light intensity and color across a multi-view capture of a scene, conditioned on a single reference edit. Our method leverages a multi-view diffusion transformer trained using a latent bridge matching formulation, achieving high-fidelity relighting of the entire image set in a single inference step. To facilitate training, we introduce a large-scale hybrid dataset comprising diverse synthetic environments -- curated from existing sources and newly designed scenes -- alongside high-fidelity, real-world multi-view captures under calibrated illumination. Surprisingly, though trained only on image pairs, SyncLight generalizes zero-shot to an arbitrary number of viewpoints, effectively propagating lighting changes across all views, without requiring camera pose information. SyncLight enables practical relighting workflows for multi-view capture systems.
Revisiting Image Fusion for Multi-Illuminant White-Balance Correction
Mar 18, 2025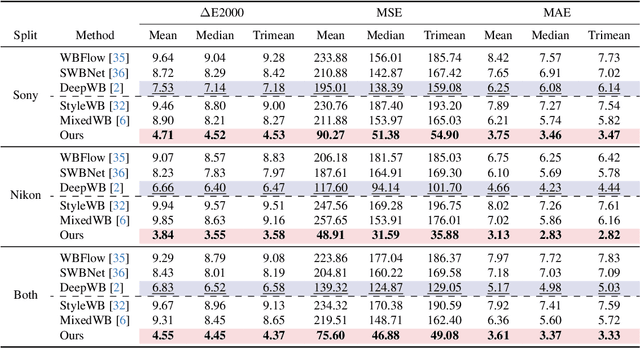

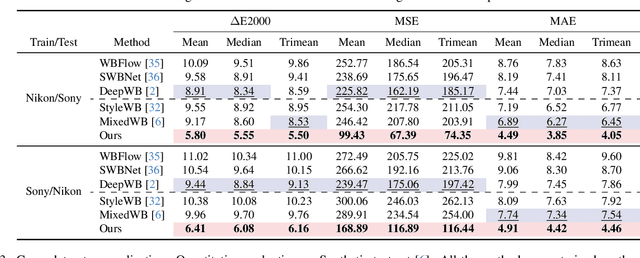
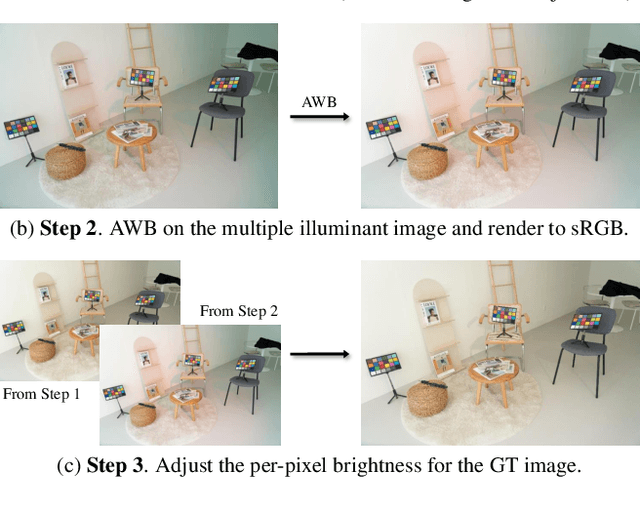
White balance (WB) correction in scenes with multiple illuminants remains a persistent challenge in computer vision. Recent methods explored fusion-based approaches, where a neural network linearly blends multiple sRGB versions of an input image, each processed with predefined WB presets. However, we demonstrate that these methods are suboptimal for common multi-illuminant scenarios. Additionally, existing fusion-based methods rely on sRGB WB datasets lacking dedicated multi-illuminant images, limiting both training and evaluation. To address these challenges, we introduce two key contributions. First, we propose an efficient transformer-based model that effectively captures spatial dependencies across sRGB WB presets, substantially improving upon linear fusion techniques. Second, we introduce a large-scale multi-illuminant dataset comprising over 16,000 sRGB images rendered with five different WB settings, along with WB-corrected images. Our method achieves up to 100\% improvement over existing techniques on our new multi-illuminant image fusion dataset.
Adaptive Blind All-in-One Image Restoration
Nov 27, 2024Blind all-in-one image restoration models aim to recover a high-quality image from an input degraded with unknown distortions. However, these models require all the possible degradation types to be defined during the training stage while showing limited generalization to unseen degradations, which limits their practical application in complex cases. In this paper, we propose a simple but effective adaptive blind all-in-one restoration (ABAIR) model, which can address multiple degradations, generalizes well to unseen degradations, and efficiently incorporate new degradations by training a small fraction of parameters. First, we train our baseline model on a large dataset of natural images with multiple synthetic degradations, augmented with a segmentation head to estimate per-pixel degradation types, resulting in a powerful backbone able to generalize to a wide range of degradations. Second, we adapt our baseline model to varying image restoration tasks using independent low-rank adapters. Third, we learn to adaptively combine adapters to versatile images via a flexible and lightweight degradation estimator. Our model is both powerful in handling specific distortions and flexible in adapting to complex tasks, it not only outperforms the state-of-the-art by a large margin on five- and three-task IR setups, but also shows improved generalization to unseen degradations and also composite distortions.
NamedCurves: Learned Image Enhancement via Color Naming
Jul 13, 2024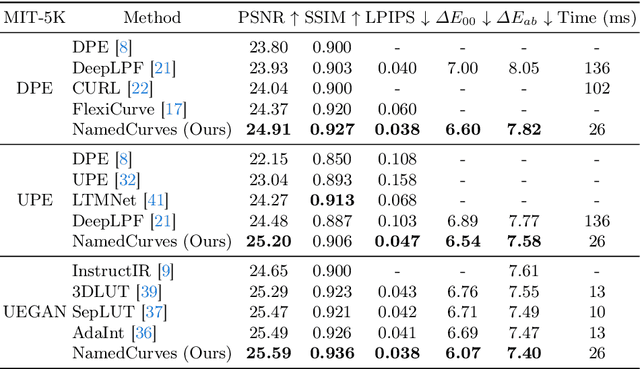



A popular method for enhancing images involves learning the style of a professional photo editor using pairs of training images comprised of the original input with the editor-enhanced version. When manipulating images, many editing tools offer a feature that allows the user to manipulate a limited selection of familiar colors. Editing by color name allows easy adjustment of elements like the "blue" of the sky or the "green" of trees. Inspired by this approach to color manipulation, we propose NamedCurves, a learning-based image enhancement technique that separates the image into a small set of named colors. Our method learns to globally adjust the image for each specific named color via tone curves and then combines the images using an attention-based fusion mechanism to mimic spatial editing. We demonstrate the effectiveness of our method against several competing methods on the well-known Adobe 5K dataset and the PPR10K dataset, showing notable improvements.
Trust your Good Friends: Source-free Domain Adaptation by Reciprocal Neighborhood Clustering
Sep 01, 2023Domain adaptation (DA) aims to alleviate the domain shift between source domain and target domain. Most DA methods require access to the source data, but often that is not possible (e.g. due to data privacy or intellectual property). In this paper, we address the challenging source-free domain adaptation (SFDA) problem, where the source pretrained model is adapted to the target domain in the absence of source data. Our method is based on the observation that target data, which might not align with the source domain classifier, still forms clear clusters. We capture this intrinsic structure by defining local affinity of the target data, and encourage label consistency among data with high local affinity. We observe that higher affinity should be assigned to reciprocal neighbors. To aggregate information with more context, we consider expanded neighborhoods with small affinity values. Furthermore, we consider the density around each target sample, which can alleviate the negative impact of potential outliers. In the experimental results we verify that the inherent structure of the target features is an important source of information for domain adaptation. We demonstrate that this local structure can be efficiently captured by considering the local neighbors, the reciprocal neighbors, and the expanded neighborhood. Finally, we achieve state-of-the-art performance on several 2D image and 3D point cloud recognition datasets.
SlimSeg: Slimmable Semantic Segmentation with Boundary Supervision
Jul 13, 2022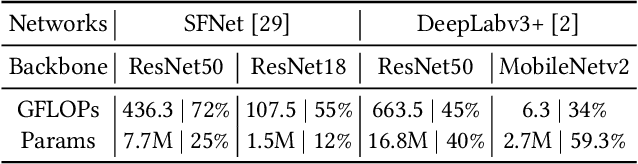
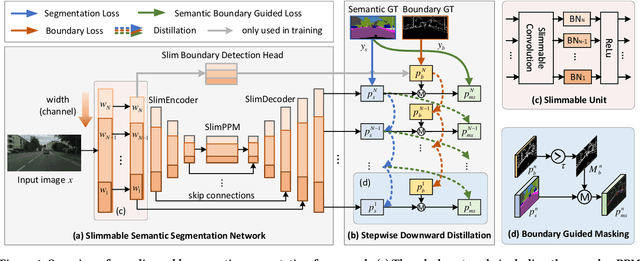

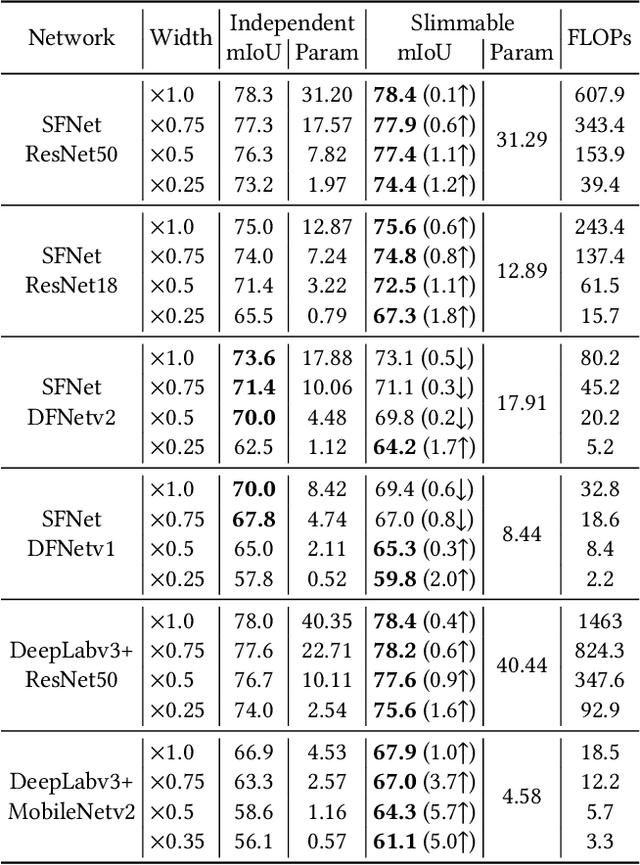
Accurate semantic segmentation models typically require significant computational resources, inhibiting their use in practical applications. Recent works rely on well-crafted lightweight models to achieve fast inference. However, these models cannot flexibly adapt to varying accuracy and efficiency requirements. In this paper, we propose a simple but effective slimmable semantic segmentation (SlimSeg) method, which can be executed at different capacities during inference depending on the desired accuracy-efficiency tradeoff. More specifically, we employ parametrized channel slimming by stepwise downward knowledge distillation during training. Motivated by the observation that the differences between segmentation results of each submodel are mainly near the semantic borders, we introduce an additional boundary guided semantic segmentation loss to further improve the performance of each submodel. We show that our proposed SlimSeg with various mainstream networks can produce flexible models that provide dynamic adjustment of computational cost and better performance than independent models. Extensive experiments on semantic segmentation benchmarks, Cityscapes and CamVid, demonstrate the generalization ability of our framework.
PeQuENet: Perceptual Quality Enhancement of Compressed Video with Adaptation- and Attention-based Network
Jun 16, 2022

In this paper we propose a generative adversarial network (GAN) framework to enhance the perceptual quality of compressed videos. Our framework includes attention and adaptation to different quantization parameters (QPs) in a single model. The attention module exploits global receptive fields that can capture and align long-range correlations between consecutive frames, which can be beneficial for enhancing perceptual quality of videos. The frame to be enhanced is fed into the deep network together with its neighboring frames, and in the first stage features at different depths are extracted. Then extracted features are fed into attention blocks to explore global temporal correlations, followed by a series of upsampling and convolution layers. Finally, the resulting features are processed by the QP-conditional adaptation module which leverages the corresponding QP information. In this way, a single model can be used to enhance adaptively to various QPs without requiring multiple models specific for every QP value, while having similar performance. Experimental results demonstrate the superior performance of the proposed PeQuENet compared with the state-of-the-art compressed video quality enhancement algorithms.
Slimmable Video Codec
May 13, 2022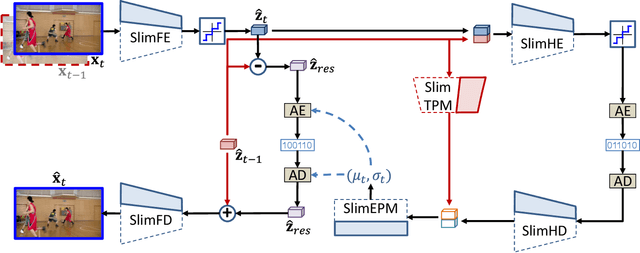

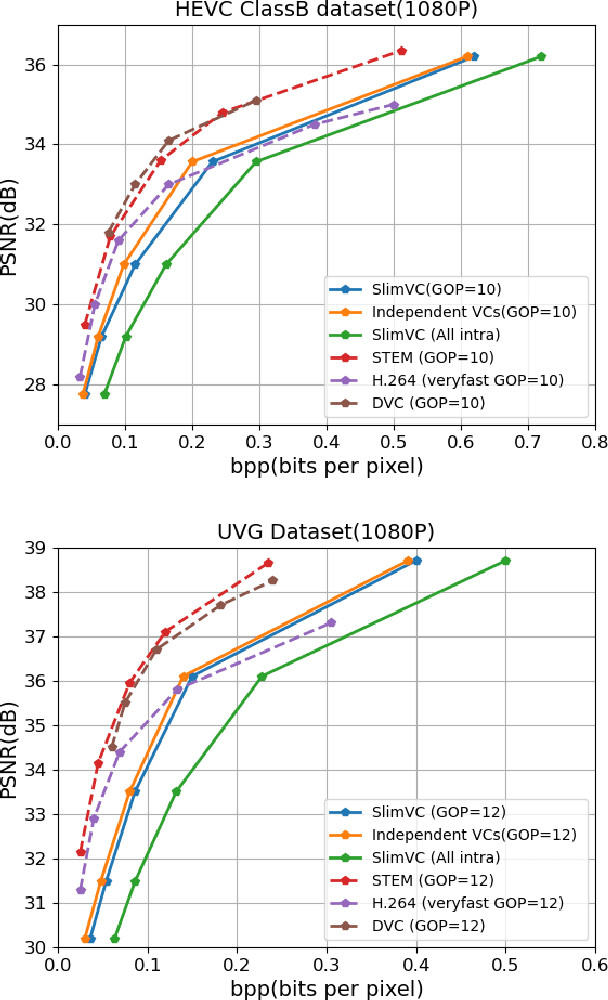
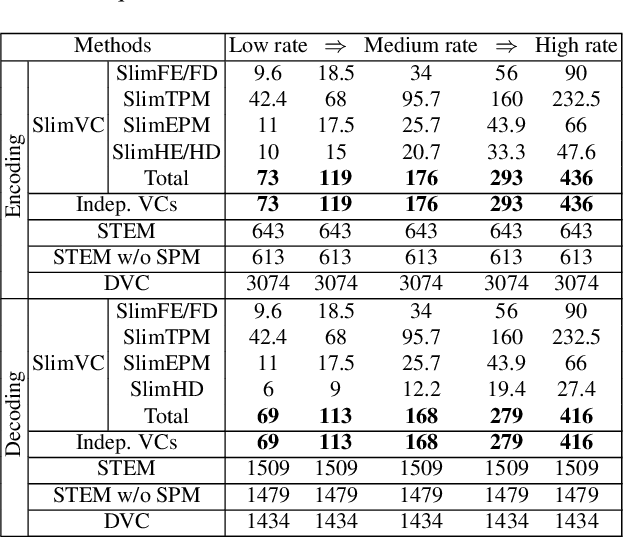
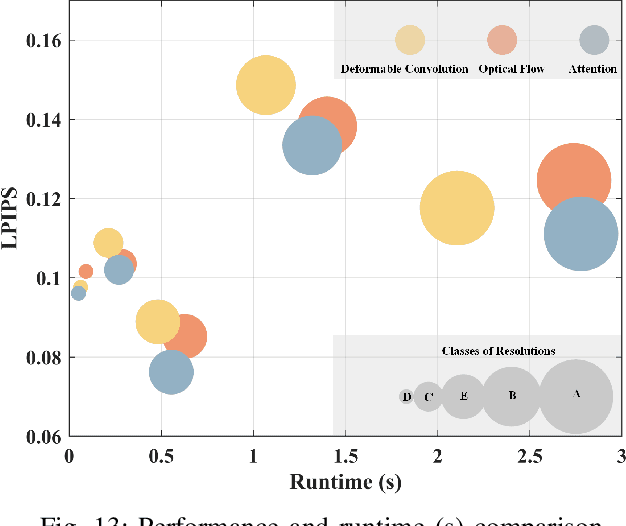
Neural video compression has emerged as a novel paradigm combining trainable multilayer neural networks and machine learning, achieving competitive rate-distortion (RD) performances, but still remaining impractical due to heavy neural architectures, with large memory and computational demands. In addition, models are usually optimized for a single RD tradeoff. Recent slimmable image codecs can dynamically adjust their model capacity to gracefully reduce the memory and computation requirements, without harming RD performance. In this paper we propose a slimmable video codec (SlimVC), by integrating a slimmable temporal entropy model in a slimmable autoencoder. Despite a significantly more complex architecture, we show that slimming remains a powerful mechanism to control rate, memory footprint, computational cost and latency, all being important requirements for practical video compression.
DCNGAN: A Deformable Convolutional-Based GAN with QP Adaptation for Perceptual Quality Enhancement of Compressed Video
Jan 28, 2022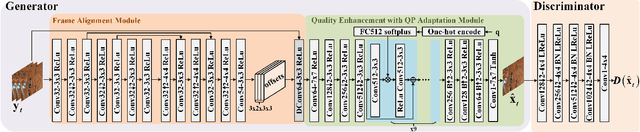
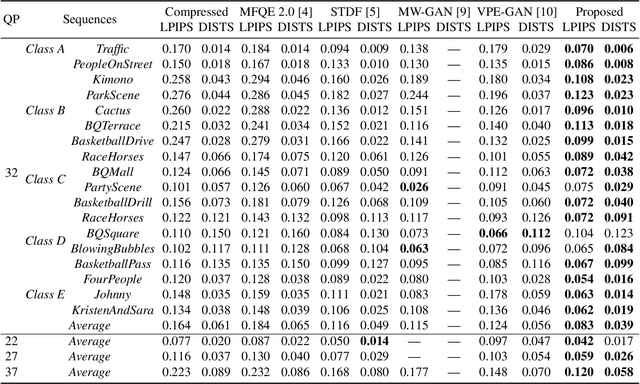

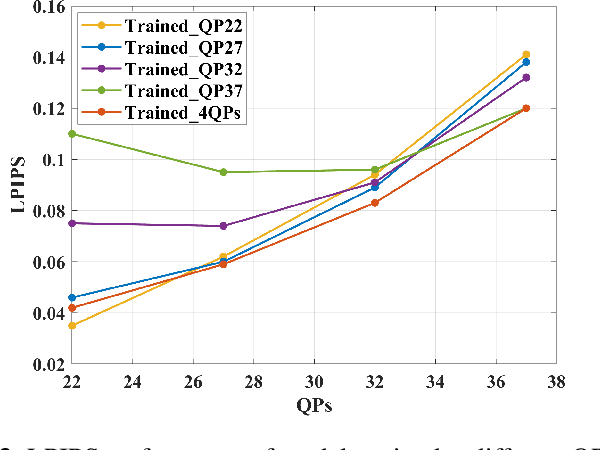
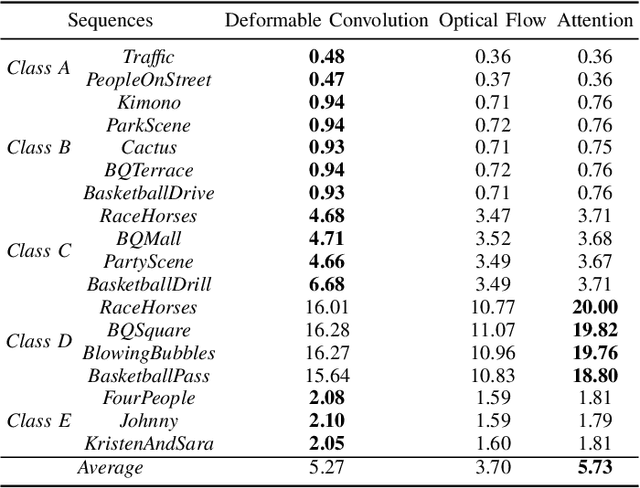
In this paper, we propose a deformable convolution-based generative adversarial network (DCNGAN) for perceptual quality enhancement of compressed videos. DCNGAN is also adaptive to the quantization parameters (QPs). Compared with optical flows, deformable convolutions are more effective and efficient to align frames. Deformable convolutions can operate on multiple frames, thus leveraging more temporal information, which is beneficial for enhancing the perceptual quality of compressed videos. Instead of aligning frames in a pairwise manner, the deformable convolution can process multiple frames simultaneously, which leads to lower computational complexity. Experimental results demonstrate that the proposed DCNGAN outperforms other state-of-the-art compressed video quality enhancement algorithms.
Main Product Detection with Graph Networks for Fashion
Jan 25, 2022Computer vision has established a foothold in the online fashion retail industry. Main product detection is a crucial step of vision-based fashion product feed parsing pipelines, focused in identifying the bounding boxes that contain the product being sold in the gallery of images of the product page. The current state-of-the-art approach does not leverage the relations between regions in the image, and treats images of the same product independently, therefore not fully exploiting visual and product contextual information. In this paper we propose a model that incorporates Graph Convolutional Networks (GCN) that jointly represent all detected bounding boxes in the gallery as nodes. We show that the proposed method is better than the state-of-the-art, especially, when we consider the scenario where title-input is missing at inference time and for cross-dataset evaluation, our method outperforms previous approaches by a large margin.