 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-ISSM: Objective Quality Assessment of Point Clouds Using Multi-scale Implicit Structural Similarity
Jan 03, 2026The unstructured and irregular nature of point clouds poses a significant challenge for objective quality assessment (PCQA), particularly in establishing accurate perceptual feature correspondence. To tackle this, we propose the Multi-scale Implicit Structural Similarity Measurement (MS-ISSM). Unlike traditional point-to-point matching, MS-ISSM utilizes Radial Basis Functions (RBF) to represent local features continuously, transforming distortion measurement into a comparison of implicit function coefficients. This approach effectively circumvents matching errors inherent in irregular data. Additionally, we propose a ResGrouped-MLP quality assessment network, which robustly maps multi-scale feature differences to perceptual scores. The network architecture departs from traditional flat MLPs by adopting a grouped encoding strategy integrated with Residual Blocks and Channel-wise Attention mechanisms. This hierarchical design allows the model to preserve the distinct physical semantics of luma, chroma, and geometry while adaptively focusing on the most salient distortion features across High, Medium, and Low scales. Experimental results on multiple benchmarks demonstrate that MS-ISSM outperforms state-of-the-art metrics in both reliability and generalization. The source code is available at: https://github.com/ZhangChen2022/MS-ISSM.
RBFIM: Perceptual Quality Assessment for Compressed Point Clouds Using Radial Basis Function Interpolation
Mar 18, 2025One of the main challenges in point cloud compression (PCC) is how to evaluate the perceived distortion so that the codec can be optimized for perceptual quality. Current standard practices in PCC highlight a primary issue: while single-feature metrics are widely used to assess compression distortion, the classic method of searching point-to-point nearest neighbors frequently fails to adequately build precise correspondences between point clouds, resulting in an ineffective capture of human perceptual features. To overcome the related limitations, we propose a novel assessment method called RBFIM, utilizing radial basis function (RBF) interpolation to convert discrete point features into a continuous feature function for the distorted point cloud. By substituting the geometry coordinates of the original point cloud into the feature function, we obtain the bijective sets of point features. This enables an establishment of precise corresponding features between distorted and original point clouds and significantly improves the accuracy of quality assessments. Moreover, this method avoids the complexity caused by bidirectional searches. Extensive experiments on multiple subjective quality datasets of compressed point clouds demonstrate that our RBFIM excels in addressing human perception tasks, thereby providing robust support for PCC optimization efforts.
Rendering-Oriented 3D Point Cloud Attribute Compression using Sparse Tensor-based Transformer
Nov 12, 2024The evolution of 3D visualization techniques has fundamentally transformed how we interact with digital content. At the forefront of this change is point cloud technology, offering an immersive experience that surpasses traditional 2D representations. However, the massive data size of point clouds presents significant challenges in data compression. Current methods for lossy point cloud attribute compression (PCAC) generally focus on reconstructing the original point clouds with minimal error. However, for point cloud visualization scenarios, the reconstructed point clouds with distortion still need to undergo a complex rendering process, which affects the final user-perceived quality. In this paper, we propose an end-to-end deep learning framework that seamlessly integrates PCAC with differentiable rendering, denoted as rendering-oriented PCAC (RO-PCAC), directly targeting the quality of rendered multiview images for viewing. In a differentiable manner, the impact of the rendering process on the reconstructed point clouds is taken into account. Moreover, we characterize point clouds as sparse tensors and propose a sparse tensor-based transformer, called SP-Trans. By aligning with the local density of the point cloud and utilizing an enhanced local attention mechanism, SP-Trans captures the intricate relationships within the point cloud, further improving feature analysis and synthesis within the framework. Extensive experiments demonstrate that the proposed RO-PCAC achieves state-of-the-art compression performance, compared to existing reconstruction-oriented methods, including traditional, learning-based, and hybrid methods.
PeQuENet: Perceptual Quality Enhancement of Compressed Video with Adaptation- and Attention-based Network
Jun 16, 2022
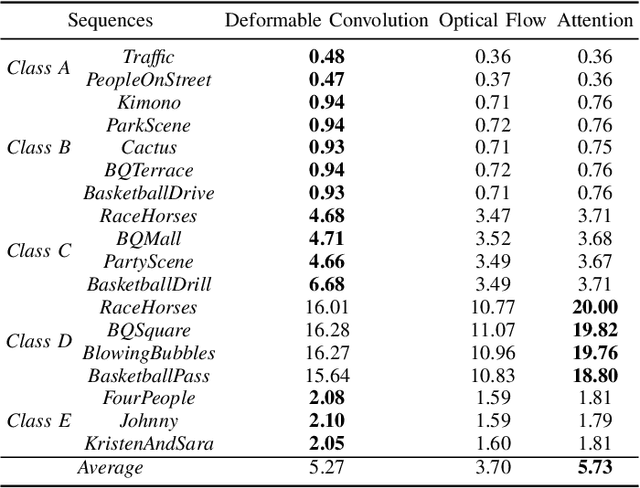

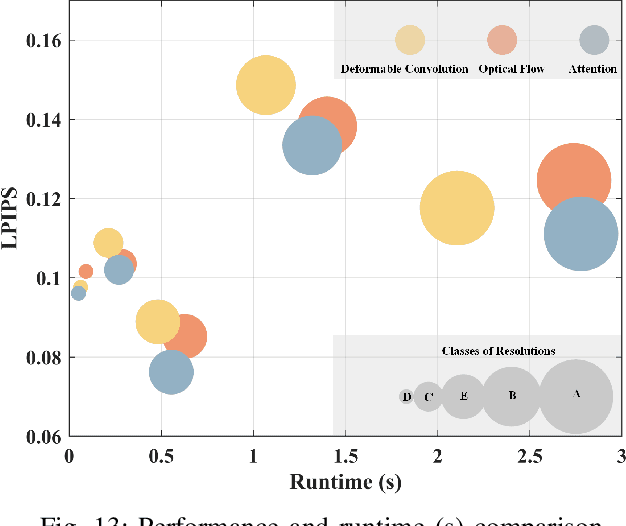
In this paper we propose a generative adversarial network (GAN) framework to enhance the perceptual quality of compressed videos. Our framework includes attention and adaptation to different quantization parameters (QPs) in a single model. The attention module exploits global receptive fields that can capture and align long-range correlations between consecutive frames, which can be beneficial for enhancing perceptual quality of videos. The frame to be enhanced is fed into the deep network together with its neighboring frames, and in the first stage features at different depths are extracted. Then extracted features are fed into attention blocks to explore global temporal correlations, followed by a series of upsampling and convolution layers. Finally, the resulting features are processed by the QP-conditional adaptation module which leverages the corresponding QP information. In this way, a single model can be used to enhance adaptively to various QPs without requiring multiple models specific for every QP value, while having similar performance. Experimental results demonstrate the superior performance of the proposed PeQuENet compared with the state-of-the-art compressed video quality enhancement algorithms.
Slimmable Video Codec
May 13, 2022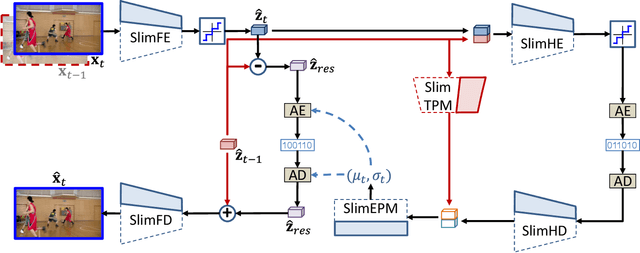

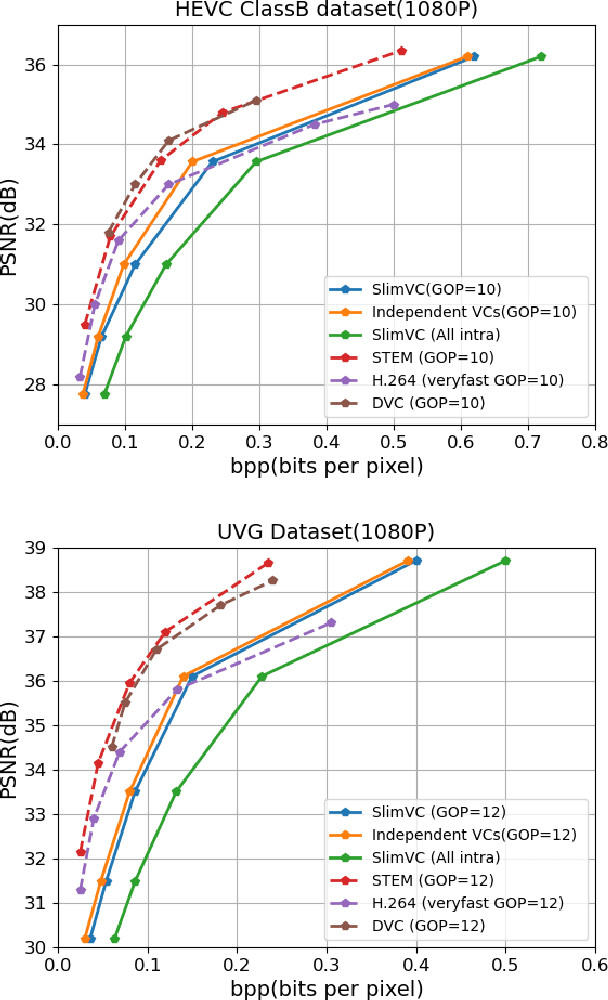
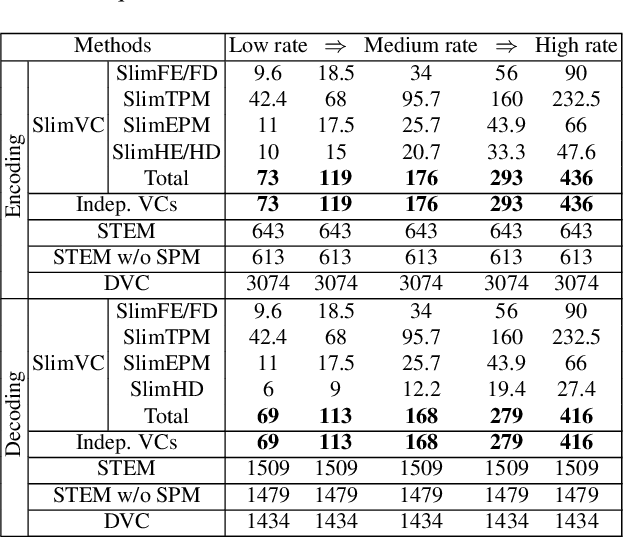
Neural video compression has emerged as a novel paradigm combining trainable multilayer neural networks and machine learning, achieving competitive rate-distortion (RD) performances, but still remaining impractical due to heavy neural architectures, with large memory and computational demands. In addition, models are usually optimized for a single RD tradeoff. Recent slimmable image codecs can dynamically adjust their model capacity to gracefully reduce the memory and computation requirements, without harming RD performance. In this paper we propose a slimmable video codec (SlimVC), by integrating a slimmable temporal entropy model in a slimmable autoencoder. Despite a significantly more complex architecture, we show that slimming remains a powerful mechanism to control rate, memory footprint, computational cost and latency, all being important requirements for practical video compression.
DCNGAN: A Deformable Convolutional-Based GAN with QP Adaptation for Perceptual Quality Enhancement of Compressed Video
Jan 28, 2022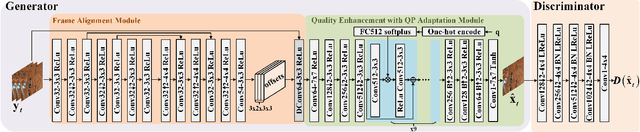
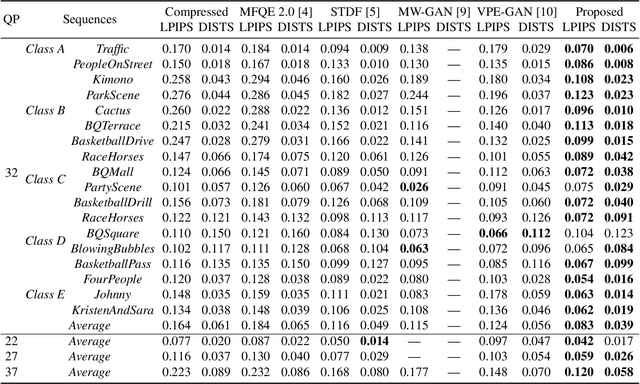

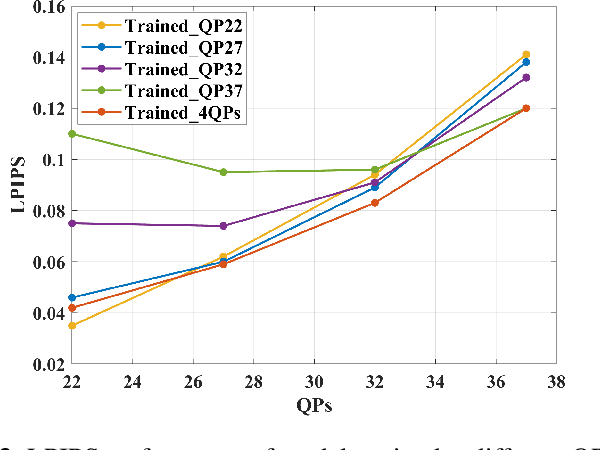
In this paper, we propose a deformable convolution-based generative adversarial network (DCNGAN) for perceptual quality enhancement of compressed videos. DCNGAN is also adaptive to the quantization parameters (QPs). Compared with optical flows, deformable convolutions are more effective and efficient to align frames. Deformable convolutions can operate on multiple frames, thus leveraging more temporal information, which is beneficial for enhancing the perceptual quality of compressed videos. Instead of aligning frames in a pairwise manner, the deformable convolution can process multiple frames simultaneously, which leads to lower computational complexity. Experimental results demonstrate that the proposed DCNGAN outperforms other state-of-the-art compressed video quality enhancement algorithms.
DVC-P: Deep Video Compression with Perceptual Optimizations
Oct 08, 2021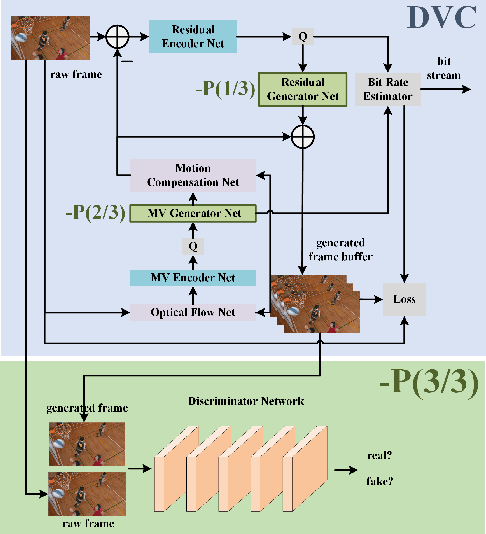
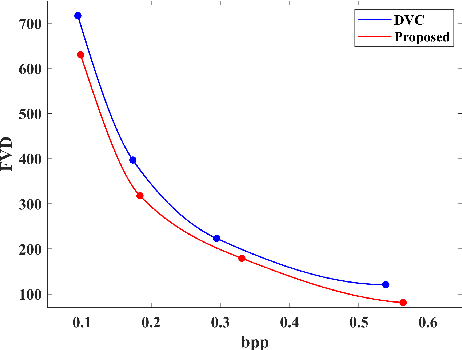
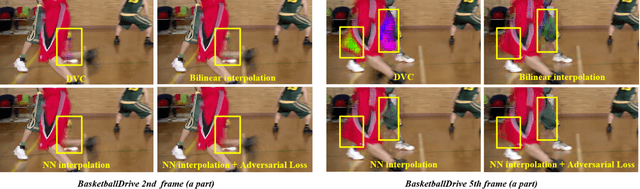

Recent years have witnessed the significant development of learning-based video compression methods, which aim at optimizing objective or perceptual quality and bit rates. In this paper, we introduce deep video compression with perceptual optimizations (DVC-P), which aims at increasing perceptual quality of decoded videos. Our proposed DVC-P is based on Deep Video Compression (DVC) network, but improves it with perceptual optimizations. Specifically, a discriminator network and a mixed loss are employed to help our network trade off among distortion, perception and rate. Furthermore, nearest-neighbor interpolation is used to eliminate checkerboard artifacts which can appear in sequences encoded with DVC frameworks. Thanks to these two improvements, the perceptual quality of decoded sequences is improved. Experimental results demonstrate that, compared with the baseline DVC, our proposed method can generate videos with higher perceptual quality achieving 12.27% reduction in a perceptual BD-rate equivalent, on average.