 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRendering-Oriented 3D Point Cloud Attribute Compression using Sparse Tensor-based Transformer
Nov 12, 2024The evolution of 3D visualization techniques has fundamentally transformed how we interact with digital content. At the forefront of this change is point cloud technology, offering an immersive experience that surpasses traditional 2D representations. However, the massive data size of point clouds presents significant challenges in data compression. Current methods for lossy point cloud attribute compression (PCAC) generally focus on reconstructing the original point clouds with minimal error. However, for point cloud visualization scenarios, the reconstructed point clouds with distortion still need to undergo a complex rendering process, which affects the final user-perceived quality. In this paper, we propose an end-to-end deep learning framework that seamlessly integrates PCAC with differentiable rendering, denoted as rendering-oriented PCAC (RO-PCAC), directly targeting the quality of rendered multiview images for viewing. In a differentiable manner, the impact of the rendering process on the reconstructed point clouds is taken into account. Moreover, we characterize point clouds as sparse tensors and propose a sparse tensor-based transformer, called SP-Trans. By aligning with the local density of the point cloud and utilizing an enhanced local attention mechanism, SP-Trans captures the intricate relationships within the point cloud, further improving feature analysis and synthesis within the framework. Extensive experiments demonstrate that the proposed RO-PCAC achieves state-of-the-art compression performance, compared to existing reconstruction-oriented methods, including traditional, learning-based, and hybrid methods.
Light field Rectification based on relative pose estimation
Jan 29, 2022



Hand-held light field (LF) cameras have unique advantages in computer vision such as 3D scene reconstruction and depth estimation. However, the related applications are limited by the ultra-small baseline, e.g., leading to the extremely low depth resolution in reconstruction. To solve this problem, we propose to rectify LF to obtain a large baseline. Specifically, the proposed method aligns two LFs captured by two hand-held LF cameras with a random relative pose, and extracts the corresponding row-aligned sub-aperture images (SAIs) to obtain an LF with a large baseline. For an accurate rectification, a method for pose estimation is also proposed, where the relative rotation and translation between the two LF cameras are estimated. The proposed pose estimation minimizes the degree of freedom (DoF) in the LF-point-LF-point correspondence model and explicitly solves this model in a linear way. The proposed pose estimation outperforms the state-of-the-art algorithms by providing more accurate results to support rectification. The significantly improved depth resolution in 3D reconstruction demonstrates the effectiveness of the proposed LF rectification.
A Light Field Camera Calibration Method Using Sub-Aperture Related Bipartition Projection Model and 4D Corner Detection
Jan 11, 2020

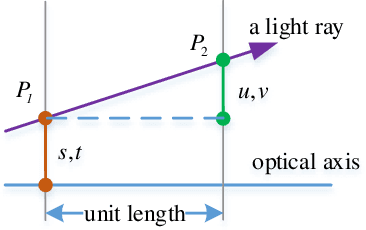
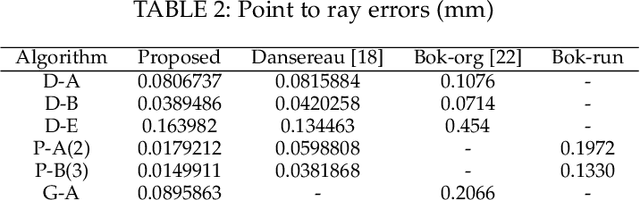
Accurate calibration of intrinsic parameters of the light field (LF) camera is the key issue of many applications, especially of the 3D reconstruction. In this paper, we propose the Sub-Aperture Related Bipartition (SARB) projection model to characterize the LF camera. This projection model is composed with two sets of parameters targeting on center view sub-aperture and relations between sub-apertures. Moreover, we also propose a corner point detection algorithm which fully utilizes the 4D LF information in the raw image. Experimental results have demonstrated the accuracy and robustness of the corner detection method. Both the 2D re-projection errors in the lateral direction and errors in the depth direction are minimized because two sets of parameters in SARB projection model are solved separately.