 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeQuENet: Perceptual Quality Enhancement of Compressed Video with Adaptation- and Attention-based Network
Jun 16, 2022

In this paper we propose a generative adversarial network (GAN) framework to enhance the perceptual quality of compressed videos. Our framework includes attention and adaptation to different quantization parameters (QPs) in a single model. The attention module exploits global receptive fields that can capture and align long-range correlations between consecutive frames, which can be beneficial for enhancing perceptual quality of videos. The frame to be enhanced is fed into the deep network together with its neighboring frames, and in the first stage features at different depths are extracted. Then extracted features are fed into attention blocks to explore global temporal correlations, followed by a series of upsampling and convolution layers. Finally, the resulting features are processed by the QP-conditional adaptation module which leverages the corresponding QP information. In this way, a single model can be used to enhance adaptively to various QPs without requiring multiple models specific for every QP value, while having similar performance. Experimental results demonstrate the superior performance of the proposed PeQuENet compared with the state-of-the-art compressed video quality enhancement algorithms.
Slimmable Video Codec
May 13, 2022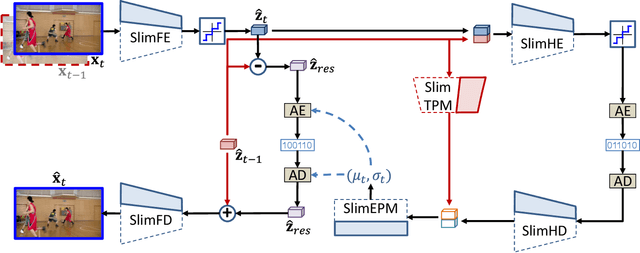

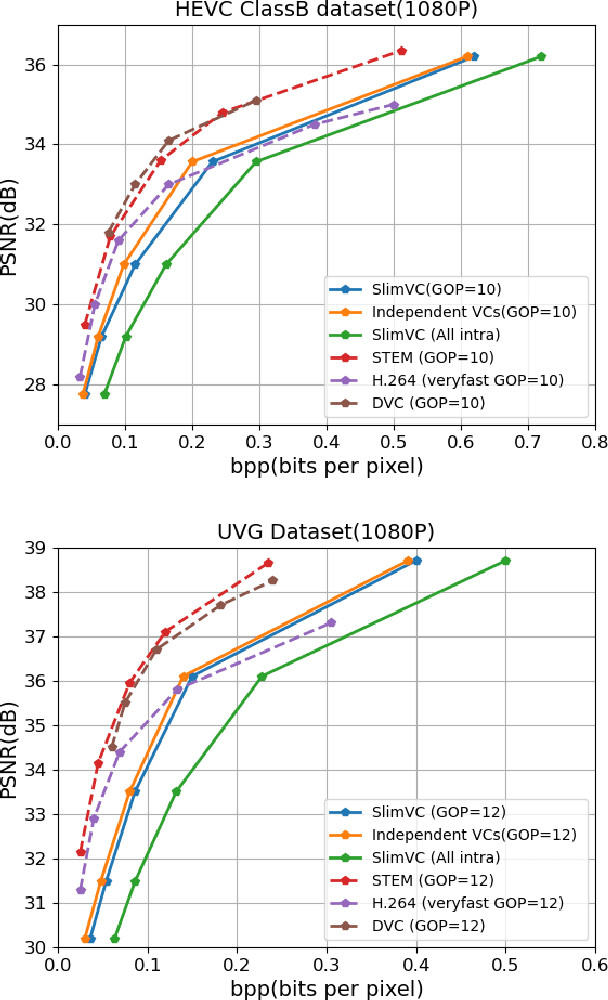
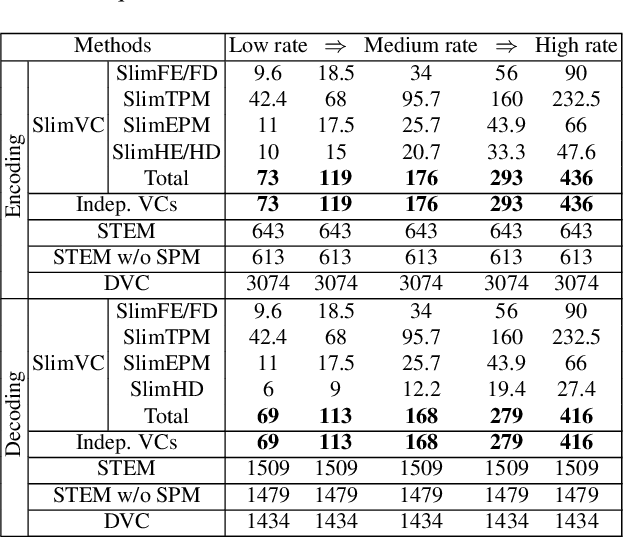
Neural video compression has emerged as a novel paradigm combining trainable multilayer neural networks and machine learning, achieving competitive rate-distortion (RD) performances, but still remaining impractical due to heavy neural architectures, with large memory and computational demands. In addition, models are usually optimized for a single RD tradeoff. Recent slimmable image codecs can dynamically adjust their model capacity to gracefully reduce the memory and computation requirements, without harming RD performance. In this paper we propose a slimmable video codec (SlimVC), by integrating a slimmable temporal entropy model in a slimmable autoencoder. Despite a significantly more complex architecture, we show that slimming remains a powerful mechanism to control rate, memory footprint, computational cost and latency, all being important requirements for practical video compression.
Light field Rectification based on relative pose estimation
Jan 29, 2022



Hand-held light field (LF) cameras have unique advantages in computer vision such as 3D scene reconstruction and depth estimation. However, the related applications are limited by the ultra-small baseline, e.g., leading to the extremely low depth resolution in reconstruction. To solve this problem, we propose to rectify LF to obtain a large baseline. Specifically, the proposed method aligns two LFs captured by two hand-held LF cameras with a random relative pose, and extracts the corresponding row-aligned sub-aperture images (SAIs) to obtain an LF with a large baseline. For an accurate rectification, a method for pose estimation is also proposed, where the relative rotation and translation between the two LF cameras are estimated. The proposed pose estimation minimizes the degree of freedom (DoF) in the LF-point-LF-point correspondence model and explicitly solves this model in a linear way. The proposed pose estimation outperforms the state-of-the-art algorithms by providing more accurate results to support rectification. The significantly improved depth resolution in 3D reconstruction demonstrates the effectiveness of the proposed LF rectification.
DCNGAN: A Deformable Convolutional-Based GAN with QP Adaptation for Perceptual Quality Enhancement of Compressed Video
Jan 28, 2022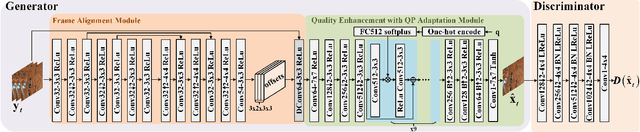
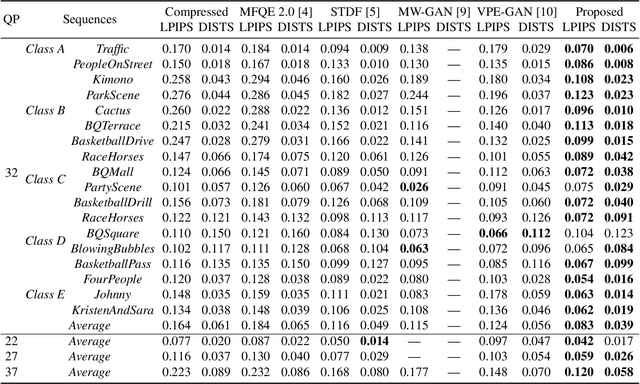

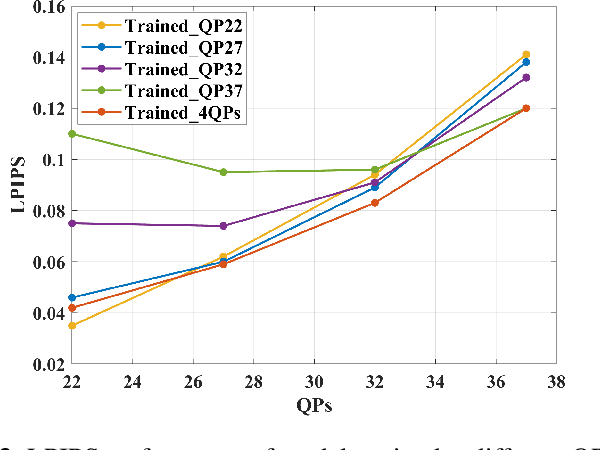
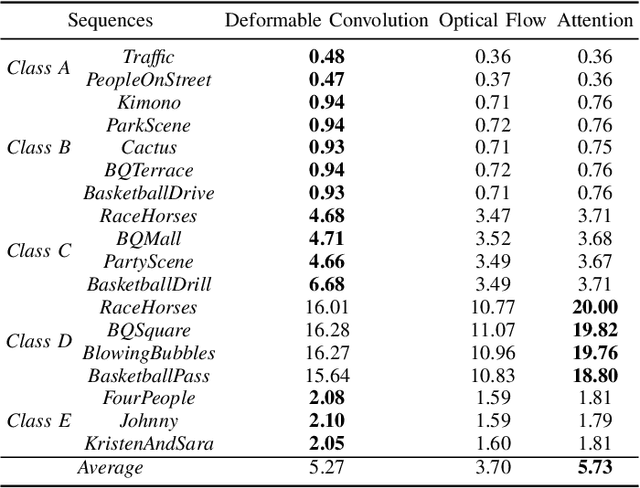
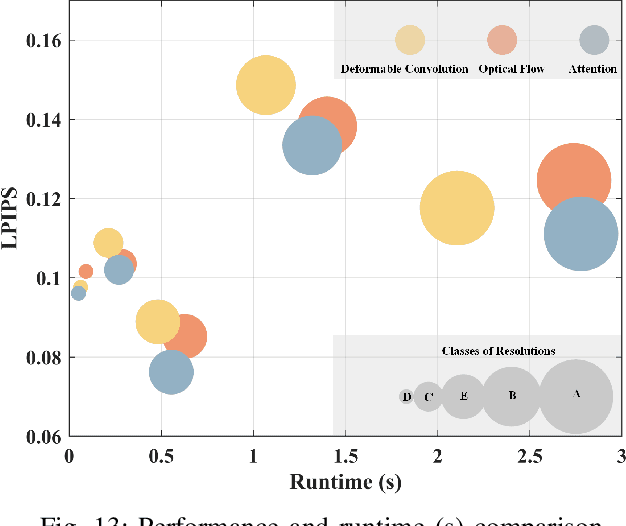
In this paper, we propose a deformable convolution-based generative adversarial network (DCNGAN) for perceptual quality enhancement of compressed videos. DCNGAN is also adaptive to the quantization parameters (QPs). Compared with optical flows, deformable convolutions are more effective and efficient to align frames. Deformable convolutions can operate on multiple frames, thus leveraging more temporal information, which is beneficial for enhancing the perceptual quality of compressed videos. Instead of aligning frames in a pairwise manner, the deformable convolution can process multiple frames simultaneously, which leads to lower computational complexity. Experimental results demonstrate that the proposed DCNGAN outperforms other state-of-the-art compressed video quality enhancement algorithms.
DVC-P: Deep Video Compression with Perceptual Optimizations
Oct 08, 2021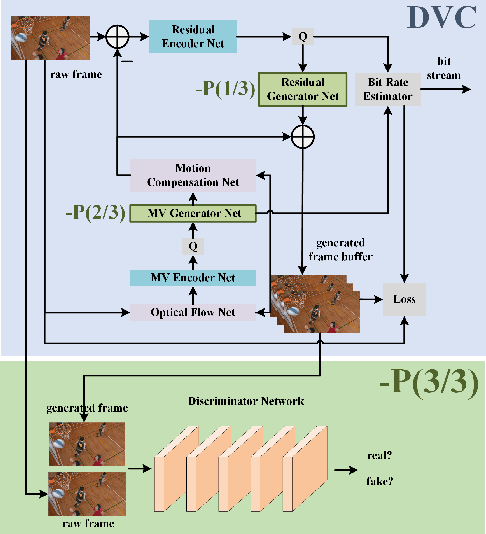
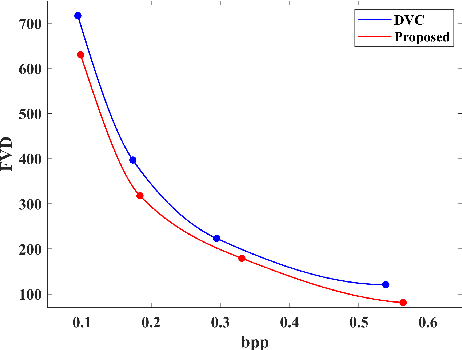
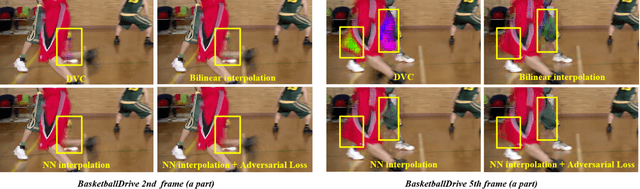

Recent years have witnessed the significant development of learning-based video compression methods, which aim at optimizing objective or perceptual quality and bit rates. In this paper, we introduce deep video compression with perceptual optimizations (DVC-P), which aims at increasing perceptual quality of decoded videos. Our proposed DVC-P is based on Deep Video Compression (DVC) network, but improves it with perceptual optimizations. Specifically, a discriminator network and a mixed loss are employed to help our network trade off among distortion, perception and rate. Furthermore, nearest-neighbor interpolation is used to eliminate checkerboard artifacts which can appear in sequences encoded with DVC frameworks. Thanks to these two improvements, the perceptual quality of decoded sequences is improved. Experimental results demonstrate that, compared with the baseline DVC, our proposed method can generate videos with higher perceptual quality achieving 12.27% reduction in a perceptual BD-rate equivalent, on average.
A Light Field Camera Calibration Method Using Sub-Aperture Related Bipartition Projection Model and 4D Corner Detection
Jan 11, 2020

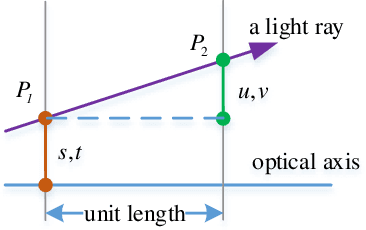
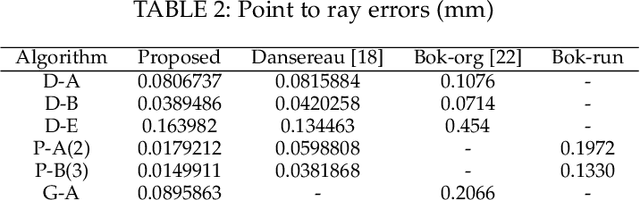
Accurate calibration of intrinsic parameters of the light field (LF) camera is the key issue of many applications, especially of the 3D reconstruction. In this paper, we propose the Sub-Aperture Related Bipartition (SARB) projection model to characterize the LF camera. This projection model is composed with two sets of parameters targeting on center view sub-aperture and relations between sub-apertures. Moreover, we also propose a corner point detection algorithm which fully utilizes the 4D LF information in the raw image. Experimental results have demonstrated the accuracy and robustness of the corner detection method. Both the 2D re-projection errors in the lateral direction and errors in the depth direction are minimized because two sets of parameters in SARB projection model are solved separately.