 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkinFlow: Efficient Information Transmission for Open Dermatological Diagnosis via Dynamic Visual Encoding and Staged RL
Jan 14, 2026General-purpose Large Vision-Language Models (LVLMs), despite their massive scale, often falter in dermatology due to "diffuse attention" - the inability to disentangle subtle pathological lesions from background noise. In this paper, we challenge the assumption that parameter scaling is the only path to medical precision. We introduce SkinFlow, a framework that treats diagnosis as an optimization of visual information transmission efficiency. Our approach utilizes a Virtual-Width Dynamic Vision Encoder (DVE) to "unfold" complex pathological manifolds without physical parameter expansion, coupled with a two-stage Reinforcement Learning strategy. This strategy sequentially aligns explicit medical descriptions (Stage I) and reconstructs implicit diagnostic textures (Stage II) within a constrained semantic space. Furthermore, we propose a clinically grounded evaluation protocol that prioritizes diagnostic safety and hierarchical relevance over rigid label matching. Empirical results are compelling: our 7B model establishes a new state-of-the-art on the Fitzpatrick17k benchmark, achieving a +12.06% gain in Top-1 accuracy and a +28.57% boost in Top-6 accuracy over the massive general-purpose models (e.g., Qwen3VL-235B and GPT-5.2). These findings demonstrate that optimizing geometric capacity and information flow yields superior diagnostic reasoning compared to raw parameter scaling.
End-to-end differentiable design of geometric waveguide displays
Jan 07, 2026Geometric waveguides are a promising architecture for optical see-through augmented reality displays, but their performance is severely bottlenecked by the difficulty of jointly optimizing non-sequential light transport and polarization-dependent multilayer thin-film coatings. Here we present the first end-to-end differentiable optimization framework for geometric waveguide that couples non-sequential Monte Carlo polarization ray tracing with a differentiable transfer-matrix thin-film solver. A differentiable Monte Carlo ray tracer avoids the exponential growth of deterministic ray splitting while enabling gradients backpropagation from eyebox metrics to design parameters. With memory-saving strategies, we optimize more than one thousand layer-thickness parameters and billions of non-sequential ray-surface intersections on a single multi-GPU workstation. Automated layer pruning is achieved by starting from over-parameterized stacks and driving redundant layers to zero thickness under discrete manufacturability constraints, effectively performing topology optimization to discover optimal coating structures. On a representative design, starting from random initialization within thickness bounds, our method increases light efficiency from 4.1\% to 33.5\% and improves eyebox and FoV uniformity by $\sim$17$\times$ and $\sim$11$\times$, respectively. Furthermore, we jointly optimize the waveguide and an image preprocessing network to improve perceived image quality. Our framework not only enables system-level, high-dimensional coating optimization inside the waveguide, but also expands the scope of differentiable optics for next-generation optical design.
GenPilot: A Multi-Agent System for Test-Time Prompt Optimization in Image Generation
Oct 08, 2025Text-to-image synthesis has made remarkable progress, yet accurately interpreting complex and lengthy prompts remains challenging, often resulting in semantic inconsistencies and missing details. Existing solutions, such as fine-tuning, are model-specific and require training, while prior automatic prompt optimization (APO) approaches typically lack systematic error analysis and refinement strategies, resulting in limited reliability and effectiveness. Meanwhile, test-time scaling methods operate on fixed prompts and on noise or sample numbers, limiting their interpretability and adaptability. To solve these, we introduce a flexible and efficient test-time prompt optimization strategy that operates directly on the input text. We propose a plug-and-play multi-agent system called GenPilot, integrating error analysis, clustering-based adaptive exploration, fine-grained verification, and a memory module for iterative optimization. Our approach is model-agnostic, interpretable, and well-suited for handling long and complex prompts. Simultaneously, we summarize the common patterns of errors and the refinement strategy, offering more experience and encouraging further exploration. Experiments on DPG-bench and Geneval with improvements of up to 16.9% and 5.7% demonstrate the strong capability of our methods in enhancing the text and image consistency and structural coherence of generated images, revealing the effectiveness of our test-time prompt optimization strategy. The code is available at https://github.com/27yw/GenPilot.
Efficient Medical VIE via Reinforcement Learning
Jun 16, 2025Visual Information Extraction (VIE) converts unstructured document images into structured formats like JSON, critical for medical applications such as report analysis and online consultations. Traditional methods rely on OCR and language models, while end-to-end multimodal models offer direct JSON generation. However, domain-specific schemas and high annotation costs limit their effectiveness in medical VIE. We base our approach on the Reinforcement Learning with Verifiable Rewards (RLVR) framework to address these challenges using only 100 annotated samples. Our approach ensures dataset diversity, a balanced precision-recall reward mechanism to reduce hallucinations and improve field coverage, and innovative sampling strategies to enhance reasoning capabilities. Fine-tuning Qwen2.5-VL-7B with our RLVR method, we achieve state-of-the-art performance on medical VIE tasks, significantly improving F1, precision, and recall. While our models excel on tasks similar to medical datasets, performance drops on dissimilar tasks, highlighting the need for domain-specific optimization. Case studies further demonstrate the value of reasoning during training and inference for VIE.
Exploring the Inquiry-Diagnosis Relationship with Advanced Patient Simulators
Jan 16, 2025
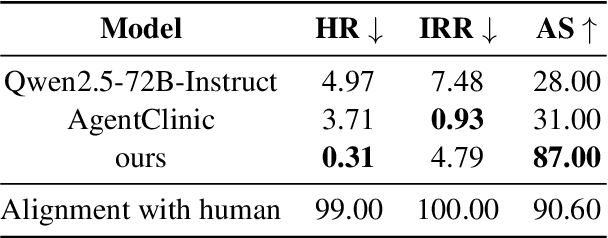


Online medical consultation (OMC) restricts doctors to gathering patient information solely through inquiries, making the already complex sequential decision-making process of diagnosis even more challenging. Recently, the rapid advancement of large language models has demonstrated a significant potential to transform OMC. However, most studies have primarily focused on improving diagnostic accuracy under conditions of relatively sufficient information, while paying limited attention to the "inquiry" phase of the consultation process. This lack of focus has left the relationship between "inquiry" and "diagnosis" insufficiently explored. In this paper, we first extract real patient interaction strategies from authentic doctor-patient conversations and use these strategies to guide the training of a patient simulator that closely mirrors real-world behavior. By inputting medical records into our patient simulator to simulate patient responses, we conduct extensive experiments to explore the relationship between "inquiry" and "diagnosis" in the consultation process. Experimental results demonstrate that inquiry and diagnosis adhere to the Liebig's law: poor inquiry quality limits the effectiveness of diagnosis, regardless of diagnostic capability, and vice versa. Furthermore, the experiments reveal significant differences in the inquiry performance of various models. To investigate this phenomenon, we categorize the inquiry process into four types: (1) chief complaint inquiry; (2) specification of known symptoms; (3) inquiry about accompanying symptoms; and (4) gathering family or medical history. We analyze the distribution of inquiries across the four types for different models to explore the reasons behind their significant performance differences. We plan to open-source the weights and related code of our patient simulator at https://github.com/LIO-H-ZEN/PatientSimulator.
Multi-Epoch learning with Data Augmentation for Deep Click-Through Rate Prediction
Jun 27, 2024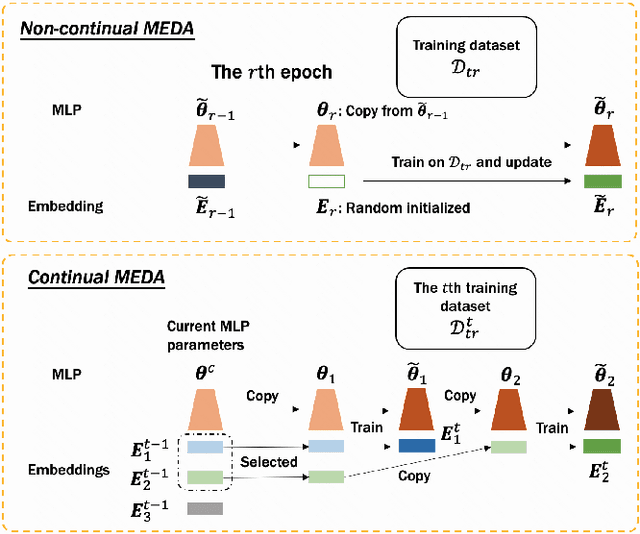
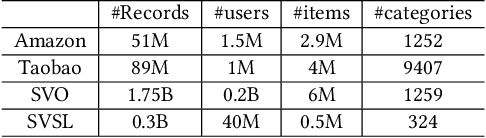
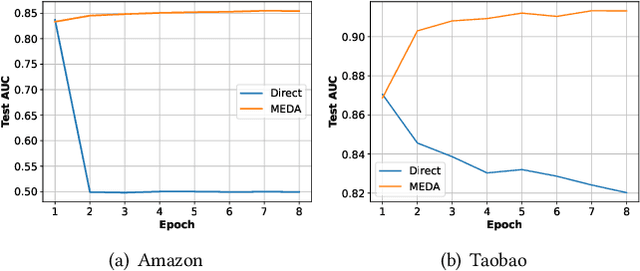
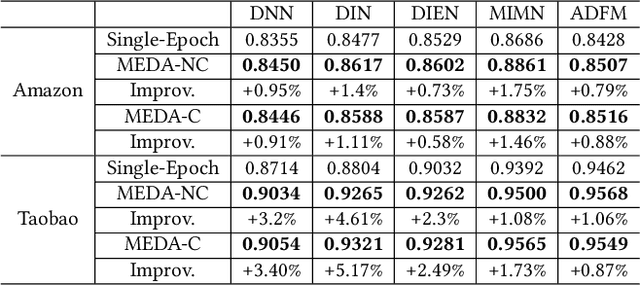
This paper investigates the one-epoch overfitting phenomenon in Click-Through Rate (CTR) models, where performance notably declines at the start of the second epoch. Despite extensive research, the efficacy of multi-epoch training over the conventional one-epoch approach remains unclear. We identify the overfitting of the embedding layer, caused by high-dimensional data sparsity, as the primary issue. To address this, we introduce a novel and simple Multi-Epoch learning with Data Augmentation (MEDA) framework, suitable for both non-continual and continual learning scenarios, which can be seamlessly integrated into existing deep CTR models and may have potential applications to handle the "forgetting or overfitting" dilemma in the retraining and the well-known catastrophic forgetting problems. MEDA minimizes overfitting by reducing the dependency of the embedding layer on subsequent training data or the Multi-Layer Perceptron (MLP) layers, and achieves data augmentation through training the MLP with varied embedding spaces. Our findings confirm that pre-trained MLP layers can adapt to new embedding spaces, enhancing performance without overfitting. This adaptability underscores the MLP layers' role in learning a matching function focused on the relative relationships among embeddings rather than their absolute positions. To our knowledge, MEDA represents the first multi-epoch training strategy tailored for deep CTR prediction models. We conduct extensive experiments on several public and business datasets, and the effectiveness of data augmentation and superiority over conventional single-epoch training are fully demonstrated. Besides, MEDA has exhibited significant benefits in a real-world online advertising system.
Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application
May 07, 2024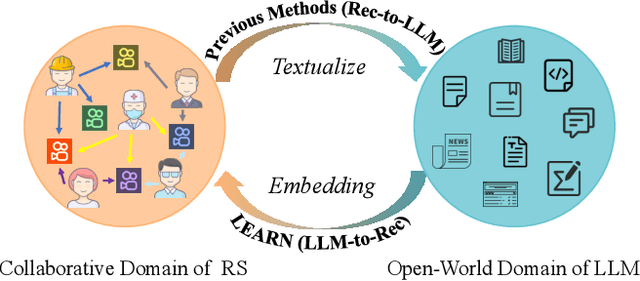


Contemporary recommender systems predominantly rely on collaborative filtering techniques, employing ID-embedding to capture latent associations among users and items. However, this approach overlooks the wealth of semantic information embedded within textual descriptions of items, leading to suboptimal performance in cold-start scenarios and long-tail user recommendations. Leveraging the capabilities of Large Language Models (LLMs) pretrained on massive text corpus presents a promising avenue for enhancing recommender systems by integrating open-world domain knowledge. In this paper, we propose an Llm-driven knowlEdge Adaptive RecommeNdation (LEARN) framework that synergizes open-world knowledge with collaborative knowledge. We address computational complexity concerns by utilizing pretrained LLMs as item encoders and freezing LLM parameters to avoid catastrophic forgetting and preserve open-world knowledge. To bridge the gap between the open-world and collaborative domains, we design a twin-tower structure supervised by the recommendation task and tailored for practical industrial application. Through offline experiments on the large-scale industrial dataset and online experiments on A/B tests, we demonstrate the efficacy of our approach.
Modular Neural Network Policies for Learning In-Flight Object Catching with a Robot Hand-Arm System
Dec 21, 2023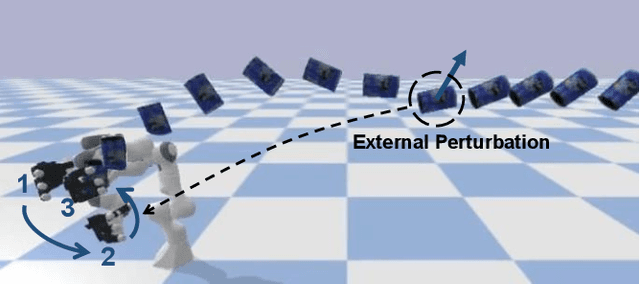
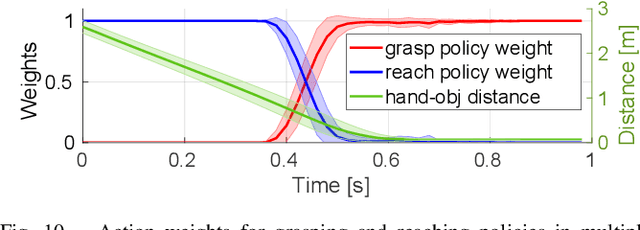


We present a modular framework designed to enable a robot hand-arm system to learn how to catch flying objects, a task that requires fast, reactive, and accurately-timed robot motions. Our framework consists of five core modules: (i) an object state estimator that learns object trajectory prediction, (ii) a catching pose quality network that learns to score and rank object poses for catching, (iii) a reaching control policy trained to move the robot hand to pre-catch poses, (iv) a grasping control policy trained to perform soft catching motions for safe and robust grasping, and (v) a gating network trained to synthesize the actions given by the reaching and grasping policy. The former two modules are trained via supervised learning and the latter three use deep reinforcement learning in a simulated environment. We conduct extensive evaluations of our framework in simulation for each module and the integrated system, to demonstrate high success rates of in-flight catching and robustness to perturbations and sensory noise. Whilst only simple cylindrical and spherical objects are used for training, the integrated system shows successful generalization to a variety of household objects that are not used in training.
RObotic MAnipulation Network (ROMAN) $\unicode{x2013}$ Hybrid Hierarchical Learning for Solving Complex Sequential Tasks
Jul 07, 2023Solving long sequential tasks poses a significant challenge in embodied artificial intelligence. Enabling a robotic system to perform diverse sequential tasks with a broad range of manipulation skills is an active area of research. In this work, we present a Hybrid Hierarchical Learning framework, the Robotic Manipulation Network (ROMAN), to address the challenge of solving multiple complex tasks over long time horizons in robotic manipulation. ROMAN achieves task versatility and robust failure recovery by integrating behavioural cloning, imitation learning, and reinforcement learning. It consists of a central manipulation network that coordinates an ensemble of various neural networks, each specialising in distinct re-combinable sub-tasks to generate their correct in-sequence actions for solving complex long-horizon manipulation tasks. Experimental results show that by orchestrating and activating these specialised manipulation experts, ROMAN generates correct sequential activations for accomplishing long sequences of sophisticated manipulation tasks and achieving adaptive behaviours beyond demonstrations, while exhibiting robustness to various sensory noises. These results demonstrate the significance and versatility of ROMAN's dynamic adaptability featuring autonomous failure recovery capabilities, and highlight its potential for various autonomous manipulation tasks that demand adaptive motor skills.
Multi-Epoch Learning for Deep Click-Through Rate Prediction Models
May 31, 2023The one-epoch overfitting phenomenon has been widely observed in industrial Click-Through Rate (CTR) applications, where the model performance experiences a significant degradation at the beginning of the second epoch. Recent advances try to understand the underlying factors behind this phenomenon through extensive experiments. However, it is still unknown whether a multi-epoch training paradigm could achieve better results, as the best performance is usually achieved by one-epoch training. In this paper, we hypothesize that the emergence of this phenomenon may be attributed to the susceptibility of the embedding layer to overfitting, which can stem from the high-dimensional sparsity of data. To maintain feature sparsity while simultaneously avoiding overfitting of embeddings, we propose a novel Multi-Epoch learning with Data Augmentation (MEDA), which can be directly applied to most deep CTR models. MEDA achieves data augmentation by reinitializing the embedding layer in each epoch, thereby avoiding embedding overfitting and simultaneously improving convergence. To our best knowledge, MEDA is the first multi-epoch training paradigm designed for deep CTR prediction models. We conduct extensive experiments on several public datasets, and the effectiveness of our proposed MEDA is fully verified. Notably, the results show that MEDA can significantly outperform the conventional one-epoch training. Besides, MEDA has exhibited significant benefits in a real-world scene on Kuaishou.