 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Search When You Can Transfer? Amortized Agentic Workflow Design from Structural Priors
Apr 27, 2026Automated agentic workflow design currently relies on per-task iterative search, which is computationally prohibitive and fails to reuse structural knowledge across tasks. We observe that optimized workflows converge to a small family of domain-specific topologies, suggesting that this combinatorial search is largely redundant. Building on this insight, we propose SWIFT (Synthesizing Workflows via Few-shot Transfer), a framework that amortizes workflow design into reusable structural priors. SWIFT first distills compositional heuristics and output-interface contracts from contrastive analysis of prior search trajectories across source tasks. At inference time, it conditions a single LLM generation pass on these priors together with cross-task workflow demonstrations to synthesize a complete, executable workflow for an unseen target task, bypassing iterative search entirely. On five benchmarks, SWIFT outperforms the state-of-the-art search-based method while reducing marginal per-task optimization cost by three orders of magnitude. It further generalizes to four additional unseen benchmarks and transfers successfully from GPT-4o-mini to three additional foundation models (Grok, Qwen, Gemma). Controlled ablations reveal that workflow demonstrations primarily transfer topological structure rather than surface semantics: replacing all operator names with random strings still retains over 93% of the full system's average performance.
Benchmarking Waitlist Mortality Prediction in Heart Transplantation Through Time-to-Event Modeling using New Longitudinal UNOS Dataset
Jul 09, 2025Decisions about managing patients on the heart transplant waitlist are currently made by committees of doctors who consider multiple factors, but the process remains largely ad-hoc. With the growing volume of longitudinal patient, donor, and organ data collected by the United Network for Organ Sharing (UNOS) since 2018, there is increasing interest in analytical approaches to support clinical decision-making at the time of organ availability. In this study, we benchmark machine learning models that leverage longitudinal waitlist history data for time-dependent, time-to-event modeling of waitlist mortality. We train on 23,807 patient records with 77 variables and evaluate both survival prediction and discrimination at a 1-year horizon. Our best model achieves a C-Index of 0.94 and AUROC of 0.89, significantly outperforming previous models. Key predictors align with known risk factors while also revealing novel associations. Our findings can support urgency assessment and policy refinement in heart transplant decision making.
Physics-Guided Learning of Meteorological Dynamics for Weather Downscaling and Forecasting
May 20, 2025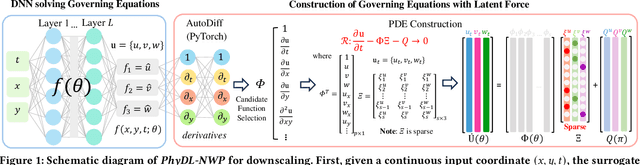

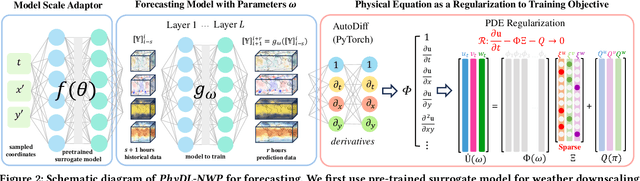
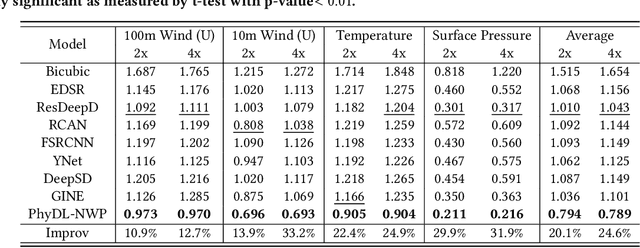
Weather forecasting is essential but remains computationally intensive and physically incomplete in traditional numerical weather prediction (NWP) methods. Deep learning (DL) models offer efficiency and accuracy but often ignore physical laws, limiting interpretability and generalization. We propose PhyDL-NWP, a physics-guided deep learning framework that integrates physical equations with latent force parameterization into data-driven models. It predicts weather variables from arbitrary spatiotemporal coordinates, computes physical terms via automatic differentiation, and uses a physics-informed loss to align predictions with governing dynamics. PhyDL-NWP enables resolution-free downscaling by modeling weather as a continuous function and fine-tunes pre-trained models with minimal overhead, achieving up to 170x faster inference with only 55K parameters. Experiments show that PhyDL-NWP improves both forecasting performance and physical consistency.
Your Diffusion Model is Secretly a Noise Classifier and Benefits from Contrastive Training
Jul 12, 2024



Diffusion models learn to denoise data and the trained denoiser is then used to generate new samples from the data distribution. In this paper, we revisit the diffusion sampling process and identify a fundamental cause of sample quality degradation: the denoiser is poorly estimated in regions that are far Outside Of the training Distribution (OOD), and the sampling process inevitably evaluates in these OOD regions. This can become problematic for all sampling methods, especially when we move to parallel sampling which requires us to initialize and update the entire sample trajectory of dynamics in parallel, leading to many OOD evaluations. To address this problem, we introduce a new self-supervised training objective that differentiates the levels of noise added to a sample, leading to improved OOD denoising performance. The approach is based on our observation that diffusion models implicitly define a log-likelihood ratio that distinguishes distributions with different amounts of noise, and this expression depends on denoiser performance outside the standard training distribution. We show by diverse experiments that the proposed contrastive diffusion training is effective for both sequential and parallel settings, and it improves the performance and speed of parallel samplers significantly.
Contextualized Policy Recovery: Modeling and Interpreting Medical Decisions with Adaptive Imitation Learning
Oct 11, 2023Interpretable policy learning seeks to estimate intelligible decision policies from observed actions; however, existing models fall short by forcing a tradeoff between accuracy and interpretability. This tradeoff limits data-driven interpretations of human decision-making process. e.g. to audit medical decisions for biases and suboptimal practices, we require models of decision processes which provide concise descriptions of complex behaviors. Fundamentally, existing approaches are burdened by this tradeoff because they represent the underlying decision process as a universal policy, when in fact human decisions are dynamic and can change drastically with contextual information. Thus, we propose Contextualized Policy Recovery (CPR), which re-frames the problem of modeling complex decision processes as a multi-task learning problem in which complex decision policies are comprised of context-specific policies. CPR models each context-specific policy as a linear observation-to-action mapping, and generates new decision models $\textit{on-demand}$ as contexts are updated with new observations. CPR is compatible with fully offline and partially observable decision environments, and can be tailored to incorporate any recurrent black-box model or interpretable decision model. We assess CPR through studies on simulated and real data, achieving state-of-the-art performance on the canonical tasks of predicting antibiotic prescription in intensive care units ($+22\%$ AUROC vs. previous SOTA) and predicting MRI prescription for Alzheimer's patients ($+7.7\%$ AUROC vs. previous SOTA). With this improvement in predictive performance, CPR closes the accuracy gap between interpretable and black-box methods for policy learning, allowing high-resolution exploration and analysis of context-specific decision models.
GSLB: The Graph Structure Learning Benchmark
Oct 08, 2023Graph Structure Learning (GSL) has recently garnered considerable attention due to its ability to optimize both the parameters of Graph Neural Networks (GNNs) and the computation graph structure simultaneously. Despite the proliferation of GSL methods developed in recent years, there is no standard experimental setting or fair comparison for performance evaluation, which creates a great obstacle to understanding the progress in this field. To fill this gap, we systematically analyze the performance of GSL in different scenarios and develop a comprehensive Graph Structure Learning Benchmark (GSLB) curated from 20 diverse graph datasets and 16 distinct GSL algorithms. Specifically, GSLB systematically investigates the characteristics of GSL in terms of three dimensions: effectiveness, robustness, and complexity. We comprehensively evaluate state-of-the-art GSL algorithms in node- and graph-level tasks, and analyze their performance in robust learning and model complexity. Further, to facilitate reproducible research, we have developed an easy-to-use library for training, evaluating, and visualizing different GSL methods. Empirical results of our extensive experiments demonstrate the ability of GSL and reveal its potential benefits on various downstream tasks, offering insights and opportunities for future research. The code of GSLB is available at: https://github.com/GSL-Benchmark/GSLB.
Learning Differential Operators for Interpretable Time Series Modeling
Sep 03, 2022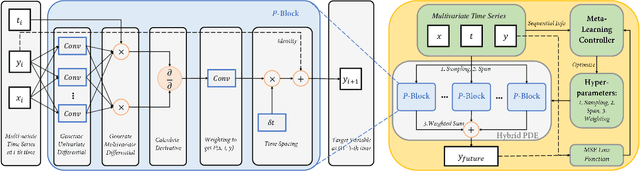


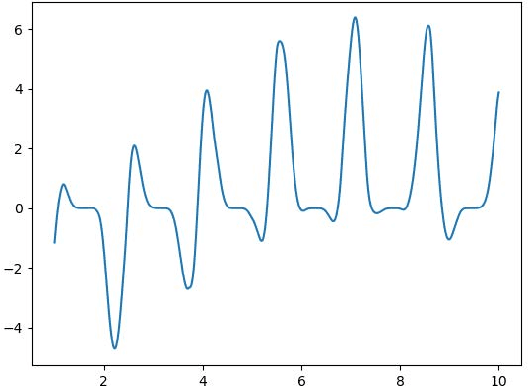
Modeling sequential patterns from data is at the core of various time series forecasting tasks. Deep learning models have greatly outperformed many traditional models, but these black-box models generally lack explainability in prediction and decision making. To reveal the underlying trend with understandable mathematical expressions, scientists and economists tend to use partial differential equations (PDEs) to explain the highly nonlinear dynamics of sequential patterns. However, it usually requires domain expert knowledge and a series of simplified assumptions, which is not always practical and can deviate from the ever-changing world. Is it possible to learn the differential relations from data dynamically to explain the time-evolving dynamics? In this work, we propose an learning framework that can automatically obtain interpretable PDE models from sequential data. Particularly, this framework is comprised of learnable differential blocks, named $P$-blocks, which is proved to be able to approximate any time-evolving complex continuous functions in theory. Moreover, to capture the dynamics shift, this framework introduces a meta-learning controller to dynamically optimize the hyper-parameters of a hybrid PDE model. Extensive experiments on times series forecasting of financial, engineering, and health data show that our model can provide valuable interpretability and achieve comparable performance to state-of-the-art models. From empirical studies, we find that learning a few differential operators may capture the major trend of sequential dynamics without massive computational complexity.
Deep Stable Representation Learning on Electronic Health Records
Sep 03, 2022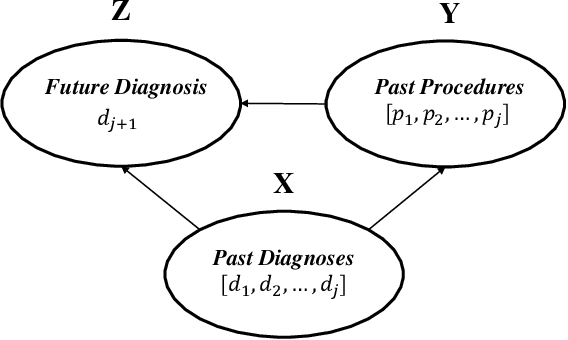
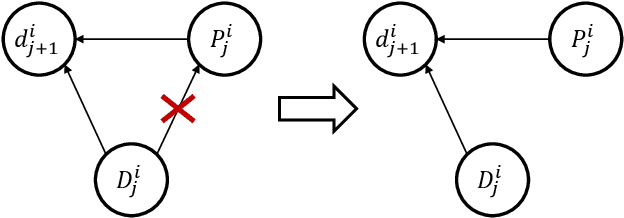
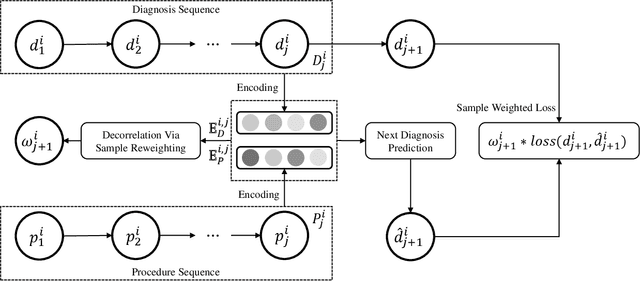
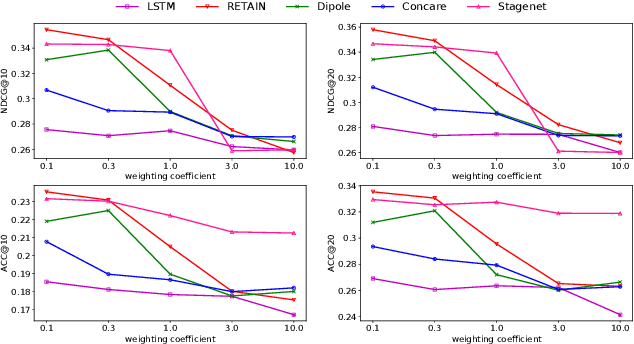
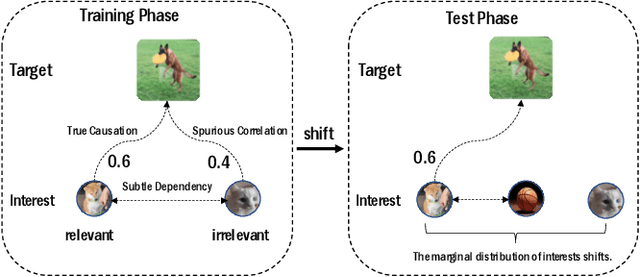
Deep learning models have achieved promising disease prediction performance of the Electronic Health Records (EHR) of patients. However, most models developed under the I.I.D. hypothesis fail to consider the agnostic distribution shifts, diminishing the generalization ability of deep learning models to Out-Of-Distribution (OOD) data. In this setting, spurious statistical correlations that may change in different environments will be exploited, which can cause sub-optimal performances of deep learning models. The unstable correlation between procedures and diagnoses existed in the training distribution can cause spurious correlation between historical EHR and future diagnosis. To address this problem, we propose to use a causal representation learning method called Causal Healthcare Embedding (CHE). CHE aims at eliminating the spurious statistical relationship by removing the dependencies between diagnoses and procedures. We introduce the Hilbert-Schmidt Independence Criterion (HSIC) to measure the degree of independence between the embedded diagnosis and procedure features. Based on causal view analyses, we perform the sample weighting technique to get rid of such spurious relationship for the stable learning of EHR across different environments. Moreover, our proposed CHE method can be used as a flexible plug-and-play module that can enhance existing deep learning models on EHR. Extensive experiments on two public datasets and five state-of-the-art baselines unequivocally show that CHE can improve the prediction accuracy of deep learning models on out-of-distribution data by a large margin. In addition, the interpretability study shows that CHE could successfully leverage causal structures to reflect a more reasonable contribution of historical records for predictions.
Improving Multi-Interest Network with Stable Learning
Jul 14, 2022
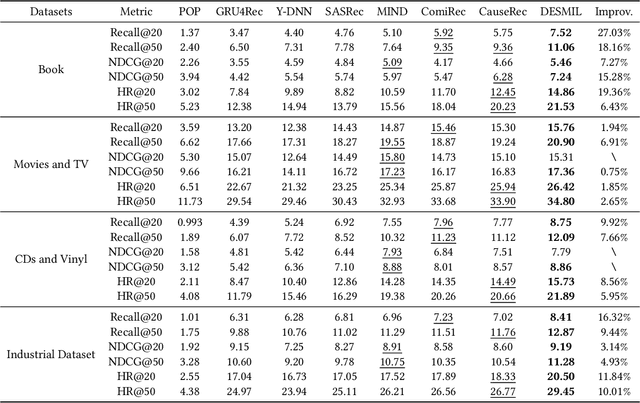

Modeling users' dynamic preferences from historical behaviors lies at the core of modern recommender systems. Due to the diverse nature of user interests, recent advances propose the multi-interest networks to encode historical behaviors into multiple interest vectors. In real scenarios, the corresponding items of captured interests are usually retrieved together to get exposure and collected into training data, which produces dependencies among interests. Unfortunately, multi-interest networks may incorrectly concentrate on subtle dependencies among captured interests. Misled by these dependencies, the spurious correlations between irrelevant interests and targets are captured, resulting in the instability of prediction results when training and test distributions do not match. In this paper, we introduce the widely used Hilbert-Schmidt Independence Criterion (HSIC) to measure the degree of independence among captured interests and empirically show that the continuous increase of HSIC may harm model performance. Based on this, we propose a novel multi-interest network, named DEep Stable Multi-Interest Learning (DESMIL), which tries to eliminate the influence of subtle dependencies among captured interests via learning weights for training samples and make model concentrate more on underlying true causation. We conduct extensive experiments on public recommendation datasets, a large-scale industrial dataset and the synthetic datasets which simulate the out-of-distribution data. Experimental results demonstrate that our proposed DESMIL outperforms state-of-the-art models by a significant margin. Besides, we also conduct comprehensive model analysis to reveal the reason why DESMIL works to a certain extent.
RMT-Net: Reject-aware Multi-Task Network for Modeling Missing-not-at-random Data in Financial Credit Scoring
Jun 01, 2022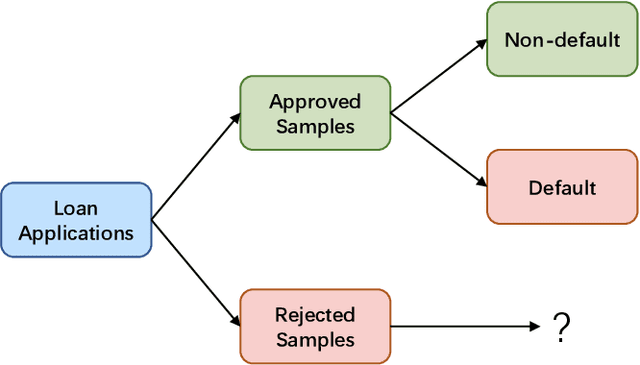
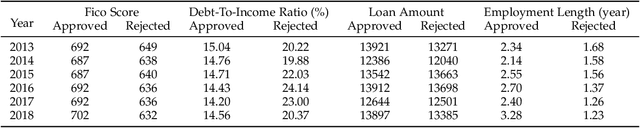
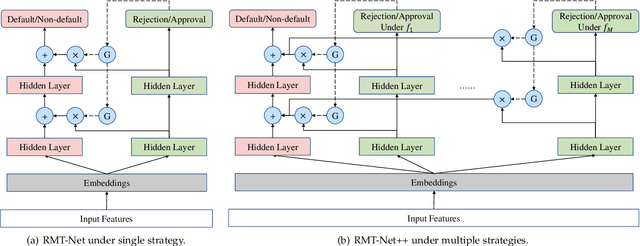
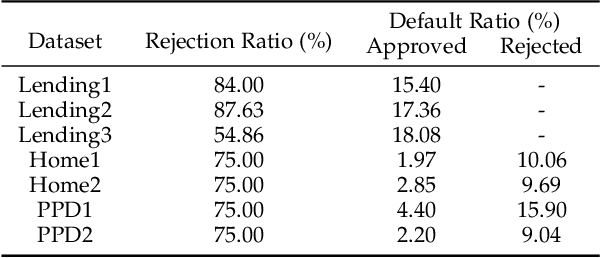
In financial credit scoring, loan applications may be approved or rejected. We can only observe default/non-default labels for approved samples but have no observations for rejected samples, which leads to missing-not-at-random selection bias. Machine learning models trained on such biased data are inevitably unreliable. In this work, we find that the default/non-default classification task and the rejection/approval classification task are highly correlated, according to both real-world data study and theoretical analysis. Consequently, the learning of default/non-default can benefit from rejection/approval. Accordingly, we for the first time propose to model the biased credit scoring data with Multi-Task Learning (MTL). Specifically, we propose a novel Reject-aware Multi-Task Network (RMT-Net), which learns the task weights that control the information sharing from the rejection/approval task to the default/non-default task by a gating network based on rejection probabilities. RMT-Net leverages the relation between the two tasks that the larger the rejection probability, the more the default/non-default task needs to learn from the rejection/approval task. Furthermore, we extend RMT-Net to RMT-Net++ for modeling scenarios with multiple rejection/approval strategies. Extensive experiments are conducted on several datasets, and strongly verifies the effectiveness of RMT-Net on both approved and rejected samples. In addition, RMT-Net++ further improves RMT-Net's performances.