 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting Channel-Patch Dependencies in Time Series Forecasting with Graph Spectral Decomposition
Mar 14, 2026Time series forecasting has attracted significant attention in the field of AI. Previous works have revealed that the Channel-Independent (CI) strategy improves forecasting performance by modeling each channel individually, but it often suffers from poor generalization and overlooks meaningful inter-channel interactions. Conversely, Channel-Dependent (CD) strategies aggregate all channels, which may introduce irrelevant information and lead to oversmoothing. Despite recent progress, few existing methods offer the flexibility to adaptively balance CI and CD strategies in response to varying channel dependencies. To address this, we propose a generic plugin xCPD, that can adaptively model the channel-patch dependencies from the perspective of graph spectral decomposition. Specifically, xCPD first projects multivariate signals into the frequency domain using a shared graph Fourier basis, and groups patches into low-, mid-, and high-frequency bands based on their spectral energy responses. xCPD then applies a channel-adaptive routing mechanism that dynamically adjusts the degree of inter-channel interaction for each patch, enabling selective activation of frequency-specific experts. This facilitates fine-grained input-aware modeling of smooth trends, local fluctuations, and abrupt transitions. xCPD can be seamlessly integrated on top of existing CI and CD forecasting models, consistently enhancing both accuracy and generalization across benchmarks. The code is available https://github.com/Clearloveyuan/xCPD.
Are Time-Series Foundation Models Deployment-Ready? A Systematic Study of Adversarial Robustness Across Domains
May 26, 2025Time Series Foundation Models (TSFMs), which are pretrained on large-scale, cross-domain data and capable of zero-shot forecasting in new scenarios without further training, are increasingly adopted in real-world applications. However, as the zero-shot forecasting paradigm gets popular, a critical yet overlooked question emerges: Are TSFMs robust to adversarial input perturbations? Such perturbations could be exploited in man-in-the-middle attacks or data poisoning. To address this gap, we conduct a systematic investigation into the adversarial robustness of TSFMs. Our results show that even minimal perturbations can induce significant and controllable changes in forecast behaviors, including trend reversal, temporal drift, and amplitude shift, posing serious risks to TSFM-based services. Through experiments on representative TSFMs and multiple datasets, we reveal their consistent vulnerabilities and identify potential architectural designs, such as structural sparsity and multi-task pretraining, that may improve robustness. Our findings offer actionable guidance for designing more resilient forecasting systems and provide a critical assessment of the adversarial robustness of TSFMs.
Scalable In-Context Learning on Tabular Data via Retrieval-Augmented Large Language Models
Feb 05, 2025



Recent studies have shown that large language models (LLMs), when customized with post-training on tabular data, can acquire general tabular in-context learning (TabICL) capabilities. These models are able to transfer effectively across diverse data schemas and different task domains. However, existing LLM-based TabICL approaches are constrained to few-shot scenarios due to the sequence length limitations of LLMs, as tabular instances represented in plain text consume substantial tokens. To address this limitation and enable scalable TabICL for any data size, we propose retrieval-augmented LLMs tailored to tabular data. Our approach incorporates a customized retrieval module, combined with retrieval-guided instruction-tuning for LLMs. This enables LLMs to effectively leverage larger datasets, achieving significantly improved performance across 69 widely recognized datasets and demonstrating promising scaling behavior. Extensive comparisons with state-of-the-art tabular models reveal that, while LLM-based TabICL still lags behind well-tuned numeric models in overall performance, it uncovers powerful algorithms under limited contexts, enhances ensemble diversity, and excels on specific datasets. These unique properties underscore the potential of language as a universal and accessible interface for scalable tabular data learning.
ElasTST: Towards Robust Varied-Horizon Forecasting with Elastic Time-Series Transformer
Nov 04, 2024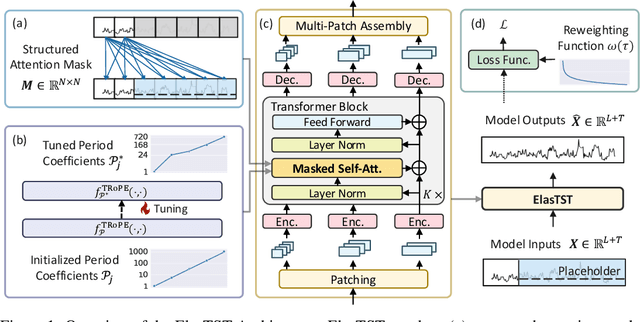
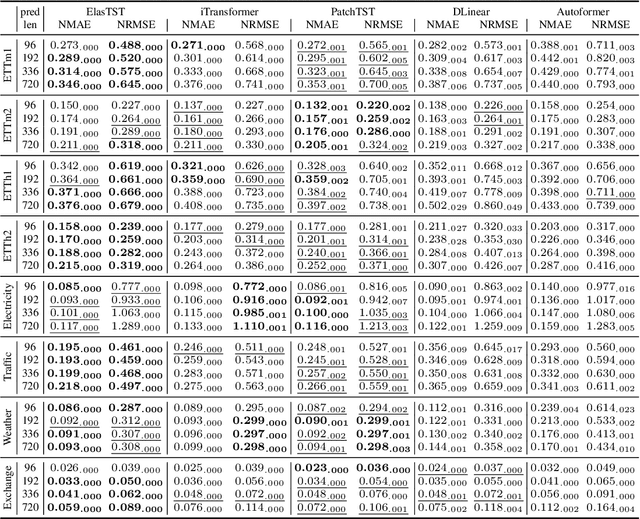
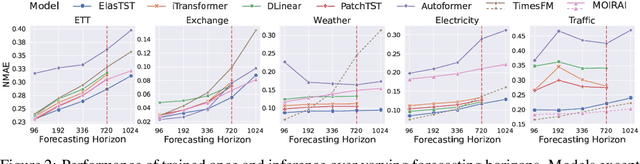
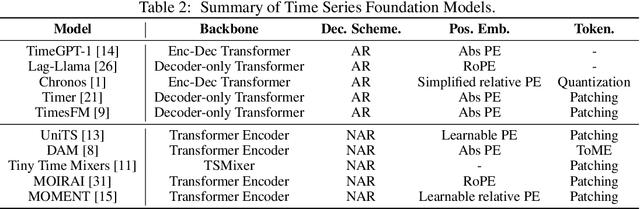
Numerous industrial sectors necessitate models capable of providing robust forecasts across various horizons. Despite the recent strides in crafting specific architectures for time-series forecasting and developing pre-trained universal models, a comprehensive examination of their capability in accommodating varied-horizon forecasting during inference is still lacking. This paper bridges this gap through the design and evaluation of the Elastic Time-Series Transformer (ElasTST). The ElasTST model incorporates a non-autoregressive design with placeholders and structured self-attention masks, warranting future outputs that are invariant to adjustments in inference horizons. A tunable version of rotary position embedding is also integrated into ElasTST to capture time-series-specific periods and enhance adaptability to different horizons. Additionally, ElasTST employs a multi-scale patch design, effectively integrating both fine-grained and coarse-grained information. During the training phase, ElasTST uses a horizon reweighting strategy that approximates the effect of random sampling across multiple horizons with a single fixed horizon setting. Through comprehensive experiments and comparisons with state-of-the-art time-series architectures and contemporary foundation models, we demonstrate the efficacy of ElasTST's unique design elements. Our findings position ElasTST as a robust solution for the practical necessity of varied-horizon forecasting.
PTaRL: Prototype-based Tabular Representation Learning via Space Calibration
Jul 07, 2024
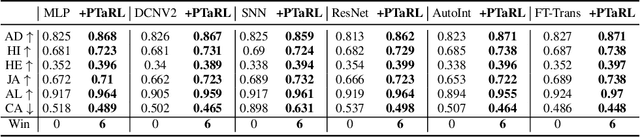


Tabular data have been playing a mostly important role in diverse real-world fields, such as healthcare, engineering, finance, etc. With the recent success of deep learning, many tabular machine learning (ML) methods based on deep networks (e.g., Transformer, ResNet) have achieved competitive performance on tabular benchmarks. However, existing deep tabular ML methods suffer from the representation entanglement and localization, which largely hinders their prediction performance and leads to performance inconsistency on tabular tasks. To overcome these problems, we explore a novel direction of applying prototype learning for tabular ML and propose a prototype-based tabular representation learning framework, PTaRL, for tabular prediction tasks. The core idea of PTaRL is to construct prototype-based projection space (P-Space) and learn the disentangled representation around global data prototypes. Specifically, PTaRL mainly involves two stages: (i) Prototype Generation, that constructs global prototypes as the basis vectors of P-Space for representation, and (ii) Prototype Projection, that projects the data samples into P-Space and keeps the core global data information via Optimal Transport. Then, to further acquire the disentangled representations, we constrain PTaRL with two strategies: (i) to diversify the coordinates towards global prototypes of different representations within P-Space, we bring up a diversification constraint for representation calibration; (ii) to avoid prototype entanglement in P-Space, we introduce a matrix orthogonalization constraint to ensure the independence of global prototypes. Finally, we conduct extensive experiments in PTaRL coupled with state-of-the-art deep tabular ML models on various tabular benchmarks and the results have shown our consistent superiority.
Large Language Model as a Universal Clinical Multi-task Decoder
Jun 18, 2024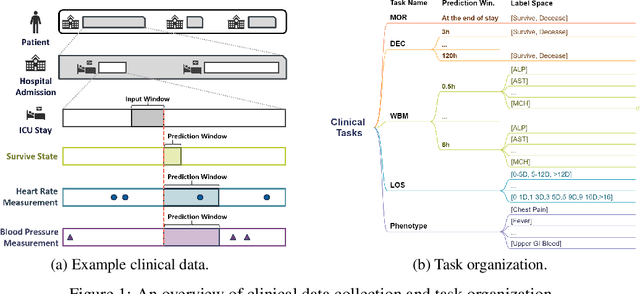
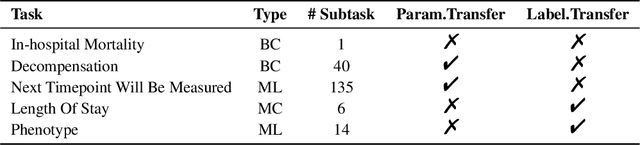
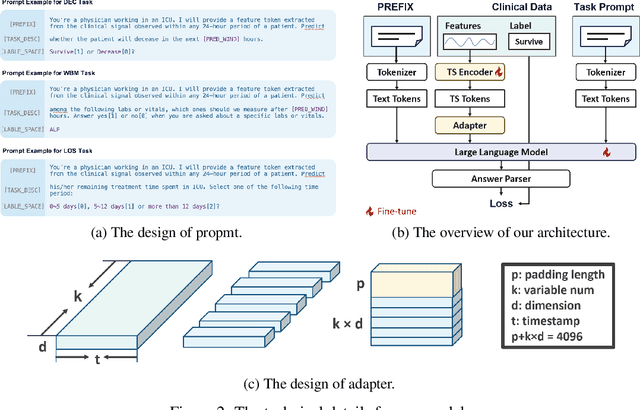
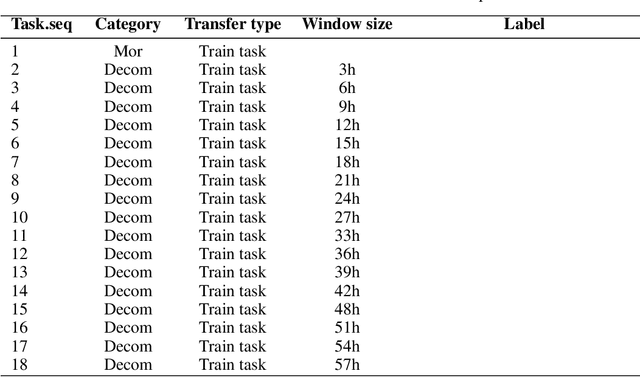
The development of effective machine learning methodologies for enhancing the efficiency and accuracy of clinical systems is crucial. Despite significant research efforts, managing a plethora of diversified clinical tasks and adapting to emerging new tasks remain significant challenges. This paper presents a novel paradigm that employs a pre-trained large language model as a universal clinical multi-task decoder. This approach leverages the flexibility and diversity of language expressions to handle task topic variations and associated arguments. The introduction of a new task simply requires the addition of a new instruction template. We validate this framework across hundreds of tasks, demonstrating its robustness in facilitating multi-task predictions, performing on par with traditional multi-task learning and single-task learning approaches. Moreover, it shows exceptional adaptability to new tasks, with impressive zero-shot performance in some instances and superior data efficiency in few-shot scenarios. This novel approach offers a unified solution to manage a wide array of new and emerging tasks in clinical applications.
Addressing Distribution Shift in Time Series Forecasting with Instance Normalization Flows
Jan 30, 2024Due to non-stationarity of time series, the distribution shift problem largely hinders the performance of time series forecasting. Existing solutions either fail for the shifts beyond simple statistics or the limited compatibility with forecasting models. In this paper, we propose a general decoupled formulation for time series forecasting, with no reliance on fixed statistics and no restriction on forecasting architectures. Then, we make such a formulation formalized into a bi-level optimization problem, to enable the joint learning of the transformation (outer loop) and forecasting (inner loop). Moreover, the special requirements of expressiveness and bi-direction for the transformation motivate us to propose instance normalization flows (IN-Flow), a novel invertible network for time series transformation. Extensive experiments demonstrate our method consistently outperforms state-of-the-art baselines on both synthetic and real-world data.
BatteryML:An Open-source platform for Machine Learning on Battery Degradation
Oct 23, 2023Battery degradation remains a pivotal concern in the energy storage domain, with machine learning emerging as a potent tool to drive forward insights and solutions. However, this intersection of electrochemical science and machine learning poses complex challenges. Machine learning experts often grapple with the intricacies of battery science, while battery researchers face hurdles in adapting intricate models tailored to specific datasets. Beyond this, a cohesive standard for battery degradation modeling, inclusive of data formats and evaluative benchmarks, is conspicuously absent. Recognizing these impediments, we present BatteryML - a one-step, all-encompass, and open-source platform designed to unify data preprocessing, feature extraction, and the implementation of both traditional and state-of-the-art models. This streamlined approach promises to enhance the practicality and efficiency of research applications. BatteryML seeks to fill this void, fostering an environment where experts from diverse specializations can collaboratively contribute, thus elevating the collective understanding and advancement of battery research.The code for our project is publicly available on GitHub at https://github.com/microsoft/BatteryML.
Towards Foundation Models for Learning on Tabular Data
Oct 22, 2023
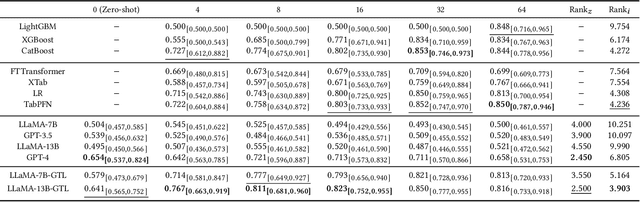

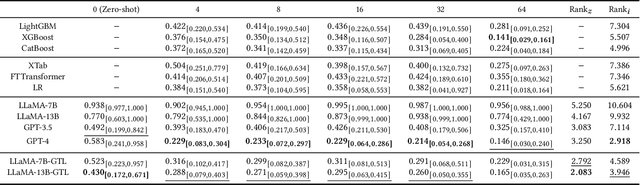
Learning on tabular data underpins numerous real-world applications. Despite considerable efforts in developing effective learning models for tabular data, current transferable tabular models remain in their infancy, limited by either the lack of support for direct instruction following in new tasks or the neglect of acquiring foundational knowledge and capabilities from diverse tabular datasets. In this paper, we propose Tabular Foundation Models (TabFMs) to overcome these limitations. TabFMs harness the potential of generative tabular learning, employing a pre-trained large language model (LLM) as the base model and fine-tuning it using purpose-designed objectives on an extensive range of tabular datasets. This approach endows TabFMs with a profound understanding and universal capabilities essential for learning on tabular data. Our evaluations underscore TabFM's effectiveness: not only does it significantly excel in instruction-following tasks like zero-shot and in-context inference, but it also showcases performance that approaches, and in instances, even transcends, the renowned yet mysterious closed-source LLMs like GPT-4. Furthermore, when fine-tuning with scarce data, our model achieves remarkable efficiency and maintains competitive performance with abundant training data. Finally, while our results are promising, we also delve into TabFM's limitations and potential opportunities, aiming to stimulate and expedite future research on developing more potent TabFMs.
Learning Intra- and Inter-Cell Differences for Accurate Battery Lifespan Prediction across Diverse Conditions
Oct 11, 2023Battery life prediction holds significant practical value for battery research and development. Currently, many data-driven models rely on early electrical signals from specific target batteries to predict their lifespan. A common shortfall is that most existing methods are developed based on specific aging conditions, which not only limits their model's capability but also diminishes their effectiveness in predicting degradation under varied conditions. As a result, these models often miss out on fully benefiting from the rich historical data available under other conditions. Here, to address above, we introduce an approach that explicitly captures differences between electrical signals of a target battery and a reference battery, irrespective of their materials and aging conditions, to forecast the target battery life. Through this inter-cell difference, we not only enhance the feature space but also pave the way for a universal battery life prediction framework. Remarkably, our model that combines the inter- and intra-cell differences shines across diverse conditions, standing out in its efficiency and accuracy using all accessible datasets. An essential application of our approach is its capability to leverage data from older batteries effectively, enabling newer batteries to capitalize on insights gained from past batteries. This work not only enriches the battery data utilization strategy but also sets the stage for smarter battery management system in the future.