 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Tabular Representation Corrector
Mar 17, 2026Tabular data have been playing a mostly important role in diverse real-world fields, such as healthcare, engineering, finance, etc. The recent success of deep learning has fostered many deep networks (e.g., Transformer, ResNet) based tabular learning methods. Generally, existing deep tabular machine learning methods are along with the two paradigms, i.e., in-learning and pre-learning. In-learning methods need to train networks from scratch or impose extra constraints to regulate the representations which nonetheless train multiple tasks simultaneously and make learning more difficult, while pre-learning methods design several pretext tasks for pre-training and then conduct task-specific fine-tuning, which however need much extra training effort with prior knowledge. In this paper, we introduce a novel deep Tabular Representation Corrector, TRC, to enhance any trained deep tabular model's representations without altering its parameters in a model-agnostic manner. Specifically, targeting the representation shift and representation redundancy that hinder prediction, we propose two tasks, i.e., (i) Tabular Representation Re-estimation, that involves training a shift estimator to calculate the inherent shift of tabular representations to subsequently mitigate it, thereby re-estimating the representations and (ii) Tabular Space Mapping, that transforms the above re-estimated representations into a light-embedding vector space via a coordinate estimator while preserves crucial predictive information to minimize redundancy. The two tasks jointly enhance the representations of deep tabular models without touching on the original models thus enjoying high efficiency. Finally, we conduct extensive experiments on state-of-the-art deep tabular machine learning models coupled with TRC on various tabular benchmarks which have shown consistent superiority.
Calibrating Tabular Anomaly Detection via Optimal Transport
Feb 06, 2026Tabular anomaly detection (TAD) remains challenging due to the heterogeneity of tabular data: features lack natural relationships, vary widely in distribution and scale, and exhibit diverse types. Consequently, each TAD method makes implicit assumptions about anomaly patterns that work well on some datasets but fail on others, and no method consistently outperforms across diverse scenarios. We present CTAD (Calibrating Tabular Anomaly Detection), a model-agnostic post-processing framework that enhances any existing TAD detector through sample-specific calibration. Our approach characterizes normal data via two complementary distributions, i.e., an empirical distribution from random sampling and a structural distribution from K-means centroids, and measures how adding a test sample disrupts their compatibility using Optimal Transport (OT) distance. Normal samples maintain low disruption while anomalies cause high disruption, providing a calibration signal to amplify detection. We prove that OT distance has a lower bound proportional to the test sample's distance from centroids, and establish that anomalies systematically receive higher calibration scores than normals in expectation, explaining why the method generalizes across datasets. Extensive experiments on 34 diverse tabular datasets with 7 representative detectors spanning all major TAD categories (density estimation, classification, reconstruction, and isolation-based methods) demonstrate that CTAD consistently improves performance with statistical significance. Remarkably, CTAD enhances even state-of-the-art deep learning methods and shows robust performance across diverse hyperparameter settings, requiring no additional tuning for practical deployment.
LLM Meeting Decision Trees on Tabular Data
May 23, 2025Tabular data have been playing a vital role in diverse real-world fields, including healthcare, finance, etc. With the recent success of Large Language Models (LLMs), early explorations of extending LLMs to the domain of tabular data have been developed. Most of these LLM-based methods typically first serialize tabular data into natural language descriptions, and then tune LLMs or directly infer on these serialized data. However, these methods suffer from two key inherent issues: (i) data perspective: existing data serialization methods lack universal applicability for structured tabular data, and may pose privacy risks through direct textual exposure, and (ii) model perspective: LLM fine-tuning methods struggle with tabular data, and in-context learning scalability is bottle-necked by input length constraints (suitable for few-shot learning). This work explores a novel direction of integrating LLMs into tabular data throughough logical decision tree rules as intermediaries, proposes a decision tree enhancer with LLM-derived rule for tabular prediction, DeLTa. The proposed DeLTa avoids tabular data serialization, and can be applied to full data learning setting without LLM fine-tuning. Specifically, we leverage the reasoning ability of LLMs to redesign an improved rule given a set of decision tree rules. Furthermore, we provide a calibration method for original decision trees via new generated rule by LLM, which approximates the error correction vector to steer the original decision tree predictions in the direction of ``errors'' reducing. Finally, extensive experiments on diverse tabular benchmarks show that our method achieves state-of-the-art performance.
Latte: Transfering LLMs` Latent-level Knowledge for Few-shot Tabular Learning
May 08, 2025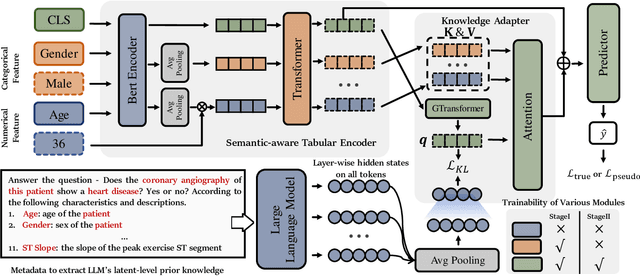
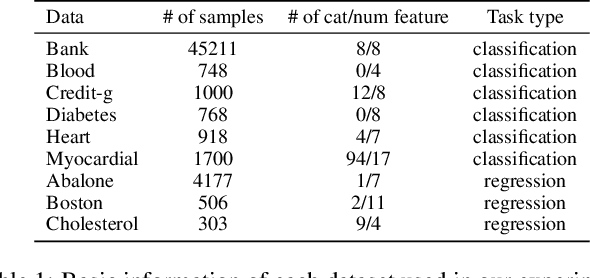
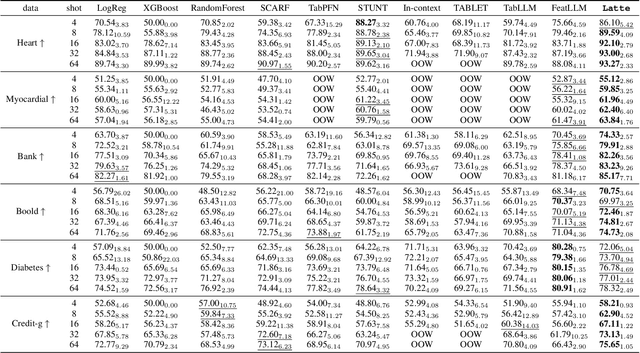

Few-shot tabular learning, in which machine learning models are trained with a limited amount of labeled data, provides a cost-effective approach to addressing real-world challenges. The advent of Large Language Models (LLMs) has sparked interest in leveraging their pre-trained knowledge for few-shot tabular learning. Despite promising results, existing approaches either rely on test-time knowledge extraction, which introduces undesirable latency, or text-level knowledge, which leads to unreliable feature engineering. To overcome these limitations, we propose Latte, a training-time knowledge extraction framework that transfers the latent prior knowledge within LLMs to optimize a more generalized downstream model. Latte enables general knowledge-guided downstream tabular learning, facilitating the weighted fusion of information across different feature values while reducing the risk of overfitting to limited labeled data. Furthermore, Latte is compatible with existing unsupervised pre-training paradigms and effectively utilizes available unlabeled samples to overcome the performance limitations imposed by an extremely small labeled dataset. Extensive experiments on various few-shot tabular learning benchmarks demonstrate the superior performance of Latte, establishing it as a state-of-the-art approach in this domain
MedGNN: Towards Multi-resolution Spatiotemporal Graph Learning for Medical Time Series Classification
Feb 06, 2025



Medical time series has been playing a vital role in real-world healthcare systems as valuable information in monitoring health conditions of patients. Accurate classification for medical time series, e.g., Electrocardiography (ECG) signals, can help for early detection and diagnosis. Traditional methods towards medical time series classification rely on handcrafted feature extraction and statistical methods; with the recent advancement of artificial intelligence, the machine learning and deep learning methods have become more popular. However, existing methods often fail to fully model the complex spatial dynamics under different scales, which ignore the dynamic multi-resolution spatial and temporal joint inter-dependencies. Moreover, they are less likely to consider the special baseline wander problem as well as the multi-view characteristics of medical time series, which largely hinders their prediction performance. To address these limitations, we propose a Multi-resolution Spatiotemporal Graph Learning framework, MedGNN, for medical time series classification. Specifically, we first propose to construct multi-resolution adaptive graph structures to learn dynamic multi-scale embeddings. Then, to address the baseline wander problem, we propose Difference Attention Networks to operate self-attention mechanisms on the finite difference for temporal modeling. Moreover, to learn the multi-view characteristics, we utilize the Frequency Convolution Networks to capture complementary information of medical time series from the frequency domain. In addition, we introduce the Multi-resolution Graph Transformer architecture to model the dynamic dependencies and fuse the information from different resolutions. Finally, we have conducted extensive experiments on multiple medical real-world datasets that demonstrate the superior performance of our method. Our Code is available.
PTaRL: Prototype-based Tabular Representation Learning via Space Calibration
Jul 07, 2024
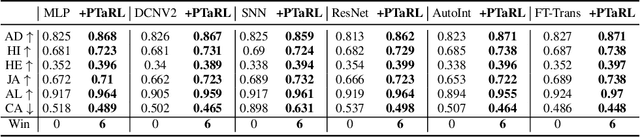


Tabular data have been playing a mostly important role in diverse real-world fields, such as healthcare, engineering, finance, etc. With the recent success of deep learning, many tabular machine learning (ML) methods based on deep networks (e.g., Transformer, ResNet) have achieved competitive performance on tabular benchmarks. However, existing deep tabular ML methods suffer from the representation entanglement and localization, which largely hinders their prediction performance and leads to performance inconsistency on tabular tasks. To overcome these problems, we explore a novel direction of applying prototype learning for tabular ML and propose a prototype-based tabular representation learning framework, PTaRL, for tabular prediction tasks. The core idea of PTaRL is to construct prototype-based projection space (P-Space) and learn the disentangled representation around global data prototypes. Specifically, PTaRL mainly involves two stages: (i) Prototype Generation, that constructs global prototypes as the basis vectors of P-Space for representation, and (ii) Prototype Projection, that projects the data samples into P-Space and keeps the core global data information via Optimal Transport. Then, to further acquire the disentangled representations, we constrain PTaRL with two strategies: (i) to diversify the coordinates towards global prototypes of different representations within P-Space, we bring up a diversification constraint for representation calibration; (ii) to avoid prototype entanglement in P-Space, we introduce a matrix orthogonalization constraint to ensure the independence of global prototypes. Finally, we conduct extensive experiments in PTaRL coupled with state-of-the-art deep tabular ML models on various tabular benchmarks and the results have shown our consistent superiority.
Deep Frequency Derivative Learning for Non-stationary Time Series Forecasting
Jun 29, 2024While most time series are non-stationary, it is inevitable for models to face the distribution shift issue in time series forecasting. Existing solutions manipulate statistical measures (usually mean and std.) to adjust time series distribution. However, these operations can be theoretically seen as the transformation towards zero frequency component of the spectrum which cannot reveal full distribution information and would further lead to information utilization bottleneck in normalization, thus hindering forecasting performance. To address this problem, we propose to utilize the whole frequency spectrum to transform time series to make full use of data distribution from the frequency perspective. We present a deep frequency derivative learning framework, DERITS, for non-stationary time series forecasting. Specifically, DERITS is built upon a novel reversible transformation, namely Frequency Derivative Transformation (FDT) that makes signals derived in the frequency domain to acquire more stationary frequency representations. Then, we propose the Order-adaptive Fourier Convolution Network to conduct adaptive frequency filtering and learning. Furthermore, we organize DERITS as a parallel-stacked architecture for the multi-order derivation and fusion for forecasting. Finally, we conduct extensive experiments on several datasets which show the consistent superiority in both time series forecasting and shift alleviation.
UADB: Unsupervised Anomaly Detection Booster
Jun 03, 2023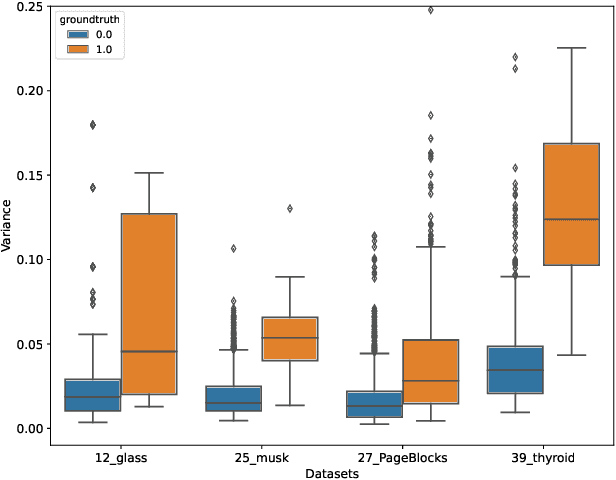
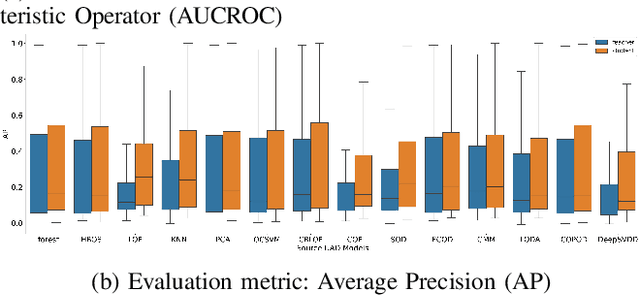
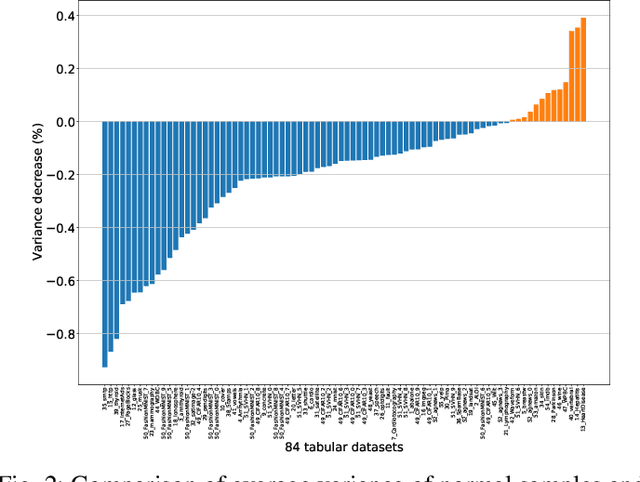
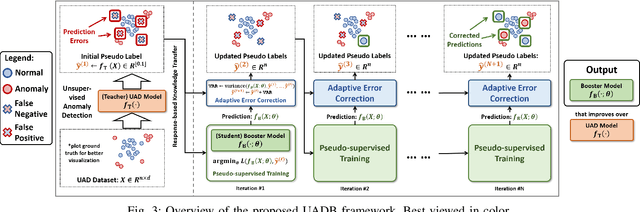
Unsupervised Anomaly Detection (UAD) is a key data mining problem owing to its wide real-world applications. Due to the complete absence of supervision signals, UAD methods rely on implicit assumptions about anomalous patterns (e.g., scattered/sparsely/densely clustered) to detect anomalies. However, real-world data are complex and vary significantly across different domains. No single assumption can describe such complexity and be valid in all scenarios. This is also confirmed by recent research that shows no UAD method is omnipotent. Based on above observations, instead of searching for a magic universal winner assumption, we seek to design a general UAD Booster (UADB) that empowers any UAD models with adaptability to different data. This is a challenging task given the heterogeneous model structures and assumptions adopted by existing UAD methods. To achieve this, we dive deep into the UAD problem and find that compared to normal data, anomalies (i) lack clear structure/pattern in feature space, thus (ii) harder to learn by model without a suitable assumption, and finally, leads to (iii) high variance between different learners. In light of these findings, we propose to (i) distill the knowledge of the source UAD model to an imitation learner (booster) that holds no data assumption, then (ii) exploit the variance between them to perform automatic correction, and thus (iii) improve the booster over the original UAD model. We use a neural network as the booster for its strong expressive power as a universal approximator and ability to perform flexible post-hoc tuning. Note that UADB is a model-agnostic framework that can enhance heterogeneous UAD models in a unified way. Extensive experiments on over 80 tabular datasets demonstrate the effectiveness of UADB.
IMBENS: Ensemble Class-imbalanced Learning in Python
Nov 24, 2021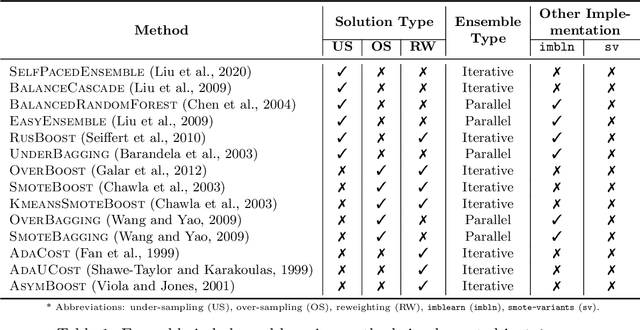
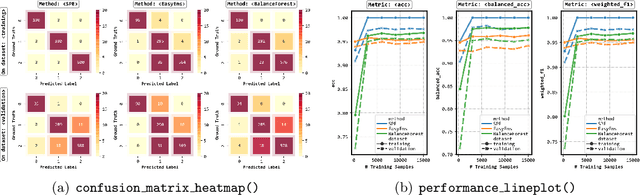
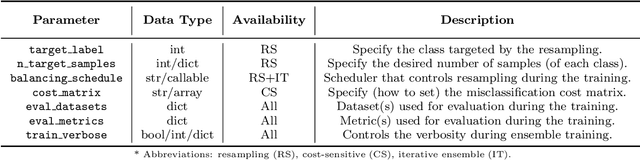
imbalanced-ensemble, abbreviated as imbens, is an open-source Python toolbox for quick implementing and deploying ensemble learning algorithms on class-imbalanced data. It provides access to multiple state-of-art ensemble imbalanced learning (EIL) methods, visualizer, and utility functions for dealing with the class imbalance problem. These ensemble methods include resampling-based, e.g., under/over-sampling, and reweighting-based ones, e.g., cost-sensitive learning. Beyond the implementation, we also extend conventional binary EIL algorithms with new functionalities like multi-class support and resampling scheduler, thereby enabling them to handle more complex tasks. The package was developed under a simple, well-documented API design follows that of scikit-learn for increased ease of use. imbens is released under the MIT open-source license and can be installed from Python Package Index (PyPI). Source code, binaries, detailed documentation, and usage examples are available at https://github.com/ZhiningLiu1998/imbalanced-ensemble.