 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoEcho: Exploiting Side-Channel Attacks to Compromise User Privacy in Mixture-of-Experts LLMs
Aug 20, 2025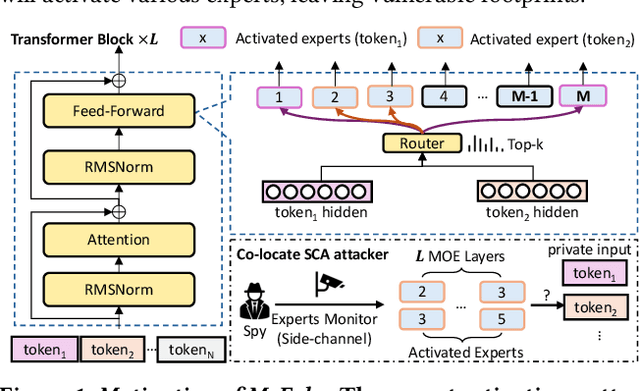

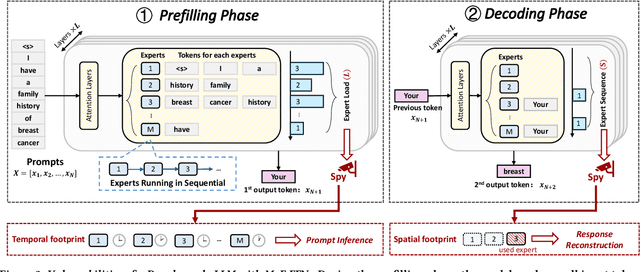
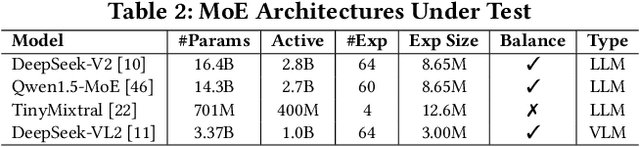
The transformer architecture has become a cornerstone of modern AI, fueling remarkable progress across applications in natural language processing, computer vision, and multimodal learning. As these models continue to scale explosively for performance, implementation efficiency remains a critical challenge. Mixture of Experts (MoE) architectures, selectively activating specialized subnetworks (experts), offer a unique balance between model accuracy and computational cost. However, the adaptive routing in MoE architectures, where input tokens are dynamically directed to specialized experts based on their semantic meaning inadvertently opens up a new attack surface for privacy breaches. These input-dependent activation patterns leave distinctive temporal and spatial traces in hardware execution, which adversaries could exploit to deduce sensitive user data. In this work, we propose MoEcho, discovering a side channel analysis based attack surface that compromises user privacy on MoE based systems. Specifically, in MoEcho, we introduce four novel architectural side channels on different computing platforms, including Cache Occupancy Channels and Pageout+Reload on CPUs, and Performance Counter and TLB Evict+Reload on GPUs, respectively. Exploiting these vulnerabilities, we propose four attacks that effectively breach user privacy in large language models (LLMs) and vision language models (VLMs) based on MoE architectures: Prompt Inference Attack, Response Reconstruction Attack, Visual Inference Attack, and Visual Reconstruction Attack. MoEcho is the first runtime architecture level security analysis of the popular MoE structure common in modern transformers, highlighting a serious security and privacy threat and calling for effective and timely safeguards when harnessing MoE based models for developing efficient large scale AI services.
An Empirical Study on Context Length for Open-Domain Dialog Generation
Aug 31, 2024Transformer-based open-domain dialog models have become increasingly popular in recent years. These models typically represent context as a concatenation of a dialog history. However, there is no criterion to decide how many utterances should be kept adequate in a context. We try to figure out how the choice of context length affects the model. We experiment on three questions from coarse to fine: (i) Does longer context help model training? (ii) Is it necessary to change the training context length when dealing with dialogs of different context lengths? (iii) Do different dialog samples have the same preference for context length? Our experimental results show that context length, an often overlooked setting, deserves attention when implementing Transformer-based dialog models.
Local and Global Contexts for Conversation
Jan 31, 2024The context in conversation is the dialog history crucial for multi-turn dialogue. Learning from the relevant contexts in dialog history for grounded conversation is a challenging problem. Local context is the most neighbor and more sensitive to the subsequent response, and global context is relevant to a whole conversation far beyond neighboring utterances. Currently, pretrained transformer models for conversation challenge capturing the correlation and connection between local and global contexts. We introduce a local and global conversation model (LGCM) for general-purpose conversation in open domain. It is a local-global hierarchical transformer model that excels at accurately discerning and assimilating the relevant contexts necessary for generating responses. It employs a local encoder to grasp the local context at the level of individual utterances and a global encoder to understand the broader context at the dialogue level. The seamless fusion of these locally and globally contextualized encodings ensures a comprehensive comprehension of the conversation. Experiments on popular datasets show that LGCM outperforms the existing conversation models on the performance of automatic metrics with significant margins.
UADB: Unsupervised Anomaly Detection Booster
Jun 03, 2023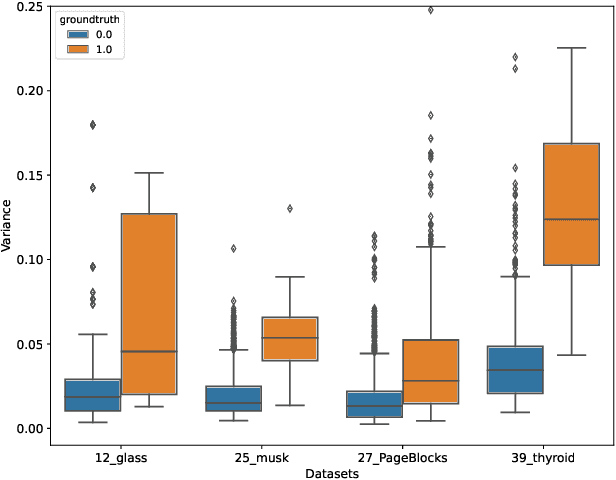
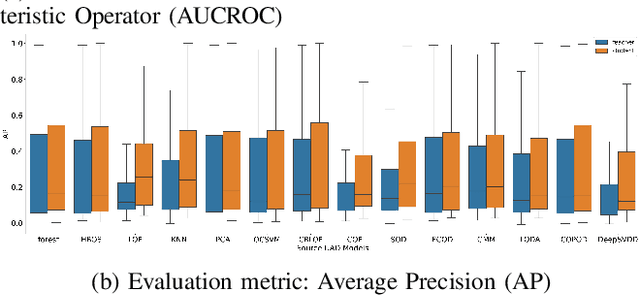
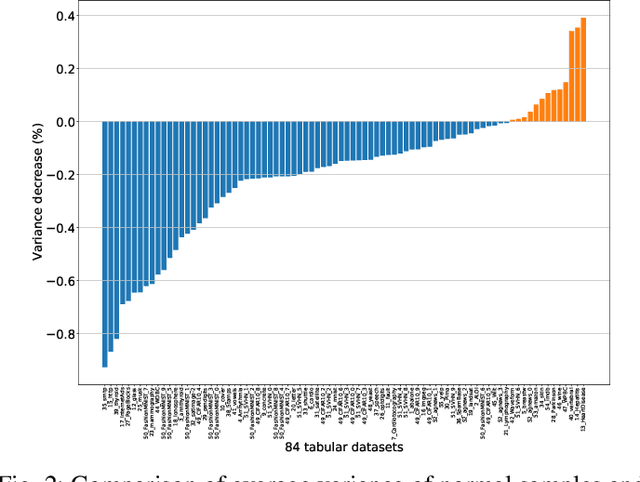
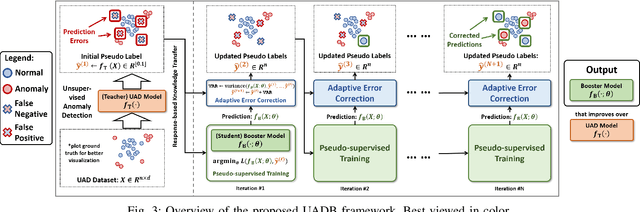
Unsupervised Anomaly Detection (UAD) is a key data mining problem owing to its wide real-world applications. Due to the complete absence of supervision signals, UAD methods rely on implicit assumptions about anomalous patterns (e.g., scattered/sparsely/densely clustered) to detect anomalies. However, real-world data are complex and vary significantly across different domains. No single assumption can describe such complexity and be valid in all scenarios. This is also confirmed by recent research that shows no UAD method is omnipotent. Based on above observations, instead of searching for a magic universal winner assumption, we seek to design a general UAD Booster (UADB) that empowers any UAD models with adaptability to different data. This is a challenging task given the heterogeneous model structures and assumptions adopted by existing UAD methods. To achieve this, we dive deep into the UAD problem and find that compared to normal data, anomalies (i) lack clear structure/pattern in feature space, thus (ii) harder to learn by model without a suitable assumption, and finally, leads to (iii) high variance between different learners. In light of these findings, we propose to (i) distill the knowledge of the source UAD model to an imitation learner (booster) that holds no data assumption, then (ii) exploit the variance between them to perform automatic correction, and thus (iii) improve the booster over the original UAD model. We use a neural network as the booster for its strong expressive power as a universal approximator and ability to perform flexible post-hoc tuning. Note that UADB is a model-agnostic framework that can enhance heterogeneous UAD models in a unified way. Extensive experiments on over 80 tabular datasets demonstrate the effectiveness of UADB.
PatchFormer: An Efficient Point Transformer with Patch Attention
Dec 02, 2021
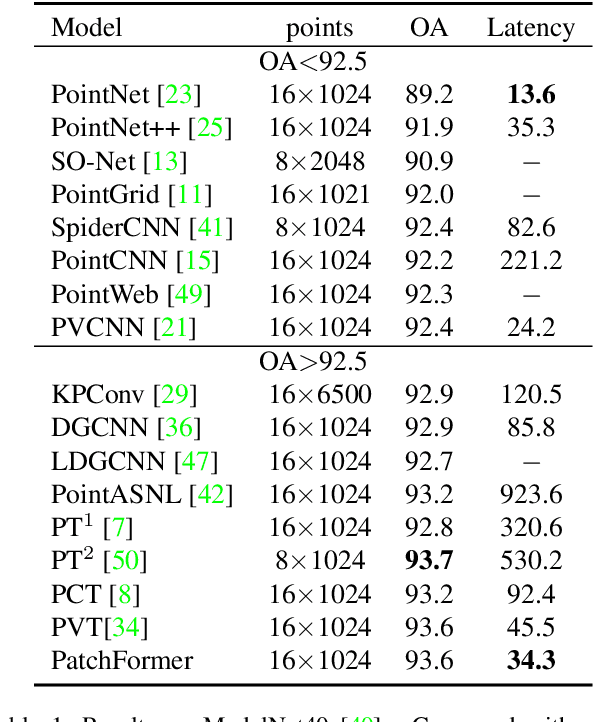
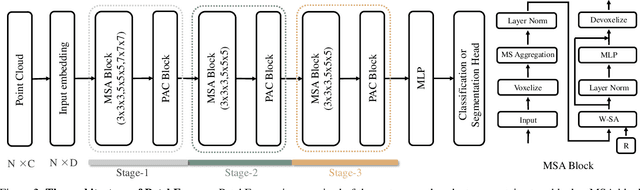
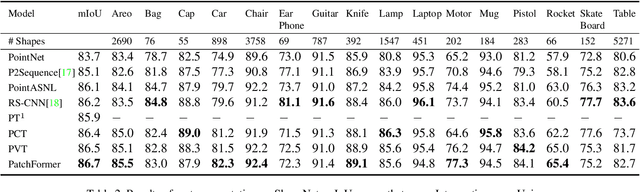
The point cloud learning community is witnesses a modeling shift from CNNs to Transformers, where pure Transformer architectures have achieved top accuracy on the major learning benchmarks. However, existing point Transformers are computationally expensive since they need to generate a large attention map, which has quadratic complexity (both in space and time) with respect to input size. To solve this shortcoming, we introduce Patch attention (PAT) to adaptively learn a much smaller set of bases upon which the attention maps are computed. By a weighted summation upon these bases, PAT not only captures the global shape context but also achieves linear complexity to input size. In addition, we propose a lightweight Multi-scale attention (MST) block to build attentions among features of different scales, providing the model with multi-scale features. Equipped with the PAT and MST, we construct our neural architecture called PatchFormer that integrates both modules into a joint framework for point cloud learning. Extensive experiments demonstrate that our network achieves comparable accuracy on general point cloud learning tasks with 9.2x speed-up than previous point Transformers.
Point-Voxel Transformer: An Efficient Approach To 3D Deep Learning
Aug 13, 2021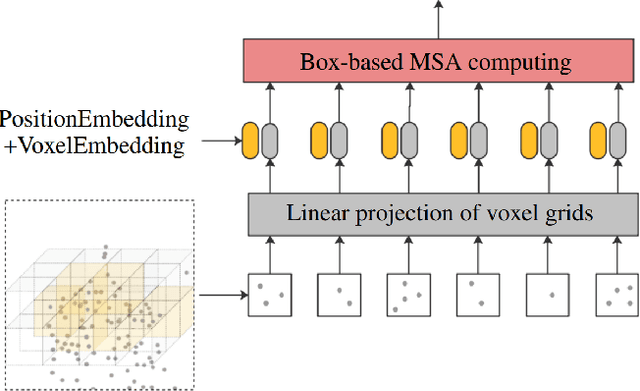
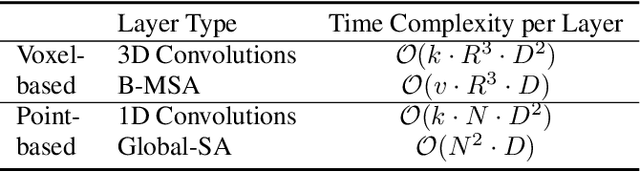
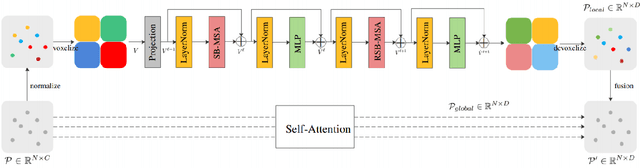
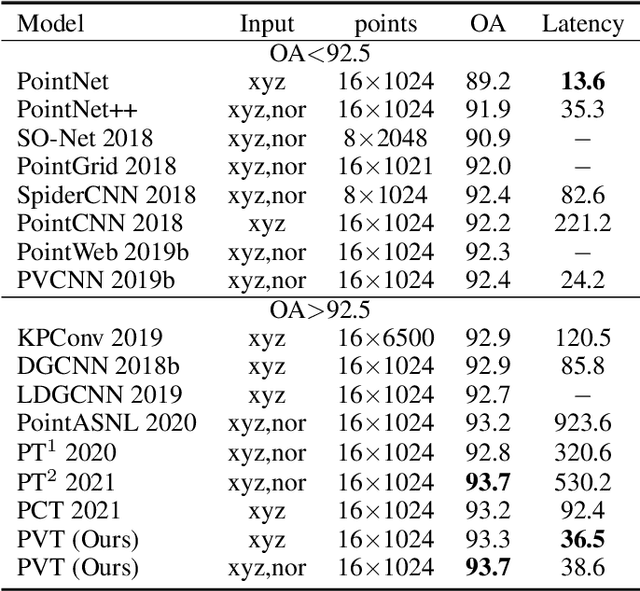
Due to the sparsity and irregularity of the 3D data, approaches that directly process points have become popular. Among all point-based models, Transformer-based models have achieved state-of-the-art performance by fully preserving point interrelation. However, most of them spend high percentage of total time on sparse data accessing (e.g., Farthest Point Sampling (FPS) and neighbor points query), which becomes the computation burden. Therefore, we present a novel 3D Transformer, called Point-Voxel Transformer (PVT) that leverages self-attention computation in points to gather global context features, while performing multi-head self-attention (MSA) computation in voxels to capture local information and reduce the irregular data access. Additionally, to further reduce the cost of MSA computation, we design a cyclic shifted boxing scheme which brings greater efficiency by limiting the MSA computation to non-overlapping local boxes while also preserving cross-box connection. Our method fully exploits the potentials of Transformer architecture, paving the road to efficient and accurate recognition results. Evaluated on classification and segmentation benchmarks, our PVT not only achieves strong accuracy but outperforms previous state-of-the-art Transformer-based models with 9x measured speedup on average. For 3D object detection task, we replace the primitives in Frustrum PointNet with PVT layer and achieve the improvement of 8.6%.