 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchFormer: An Efficient Point Transformer with Patch Attention
Dec 02, 2021
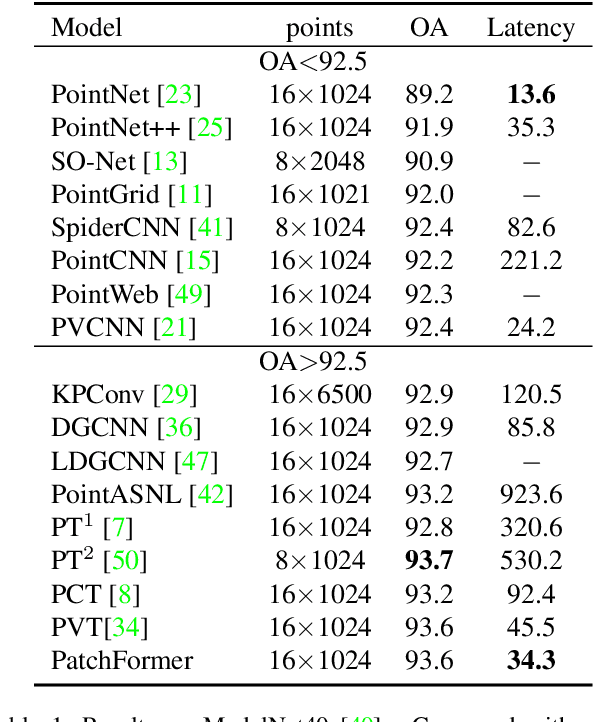
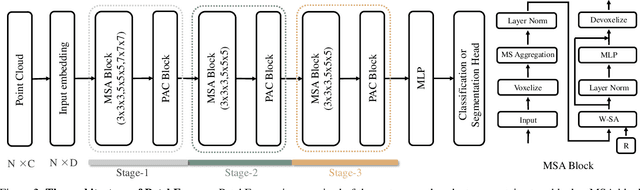
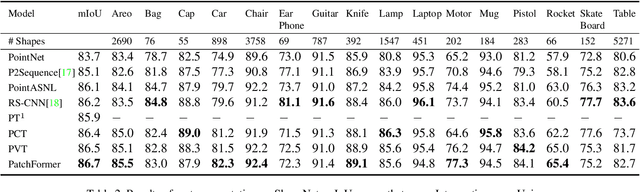
The point cloud learning community is witnesses a modeling shift from CNNs to Transformers, where pure Transformer architectures have achieved top accuracy on the major learning benchmarks. However, existing point Transformers are computationally expensive since they need to generate a large attention map, which has quadratic complexity (both in space and time) with respect to input size. To solve this shortcoming, we introduce Patch attention (PAT) to adaptively learn a much smaller set of bases upon which the attention maps are computed. By a weighted summation upon these bases, PAT not only captures the global shape context but also achieves linear complexity to input size. In addition, we propose a lightweight Multi-scale attention (MST) block to build attentions among features of different scales, providing the model with multi-scale features. Equipped with the PAT and MST, we construct our neural architecture called PatchFormer that integrates both modules into a joint framework for point cloud learning. Extensive experiments demonstrate that our network achieves comparable accuracy on general point cloud learning tasks with 9.2x speed-up than previous point Transformers.
Point-Voxel Transformer: An Efficient Approach To 3D Deep Learning
Aug 13, 2021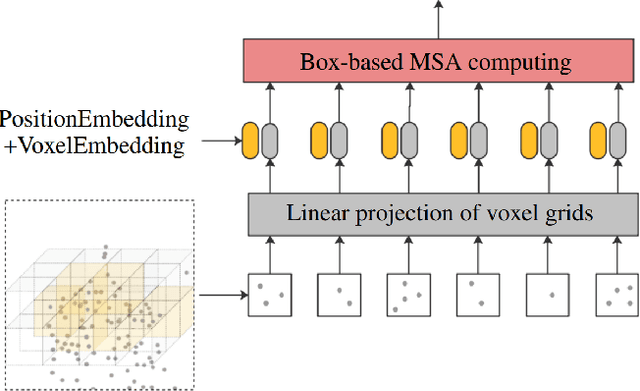
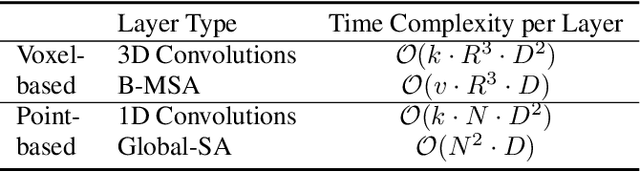
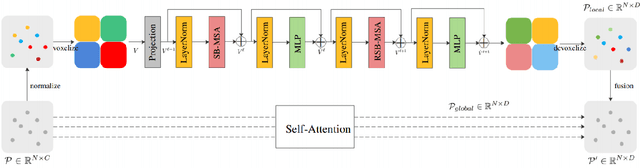
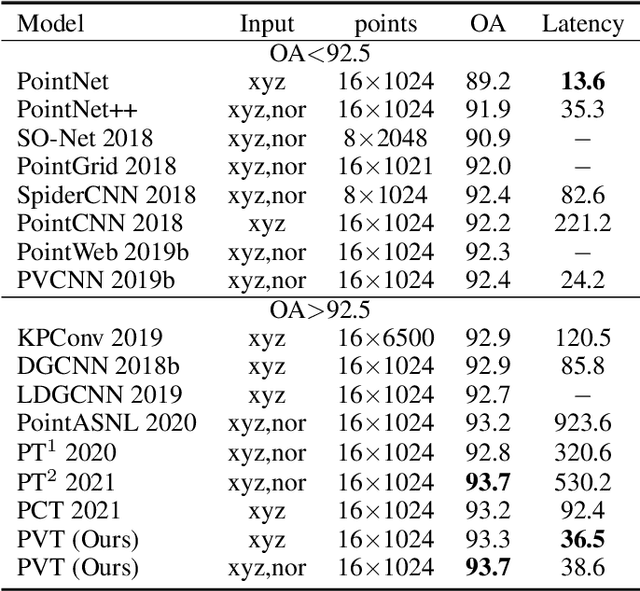
Due to the sparsity and irregularity of the 3D data, approaches that directly process points have become popular. Among all point-based models, Transformer-based models have achieved state-of-the-art performance by fully preserving point interrelation. However, most of them spend high percentage of total time on sparse data accessing (e.g., Farthest Point Sampling (FPS) and neighbor points query), which becomes the computation burden. Therefore, we present a novel 3D Transformer, called Point-Voxel Transformer (PVT) that leverages self-attention computation in points to gather global context features, while performing multi-head self-attention (MSA) computation in voxels to capture local information and reduce the irregular data access. Additionally, to further reduce the cost of MSA computation, we design a cyclic shifted boxing scheme which brings greater efficiency by limiting the MSA computation to non-overlapping local boxes while also preserving cross-box connection. Our method fully exploits the potentials of Transformer architecture, paving the road to efficient and accurate recognition results. Evaluated on classification and segmentation benchmarks, our PVT not only achieves strong accuracy but outperforms previous state-of-the-art Transformer-based models with 9x measured speedup on average. For 3D object detection task, we replace the primitives in Frustrum PointNet with PVT layer and achieve the improvement of 8.6%.