 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbo your multi-modal classification with contrastive learning
Sep 14, 2024



Contrastive learning has become one of the most impressive approaches for multi-modal representation learning. However, previous multi-modal works mainly focused on cross-modal understanding, ignoring in-modal contrastive learning, which limits the representation of each modality. In this paper, we propose a novel contrastive learning strategy, called $Turbo$, to promote multi-modal understanding by joint in-modal and cross-modal contrastive learning. Specifically, multi-modal data pairs are sent through the forward pass twice with different hidden dropout masks to get two different representations for each modality. With these representations, we obtain multiple in-modal and cross-modal contrastive objectives for training. Finally, we combine the self-supervised Turbo with the supervised multi-modal classification and demonstrate its effectiveness on two audio-text classification tasks, where the state-of-the-art performance is achieved on a speech emotion recognition benchmark dataset.
DSCLAP: Domain-Specific Contrastive Language-Audio Pre-Training
Sep 14, 2024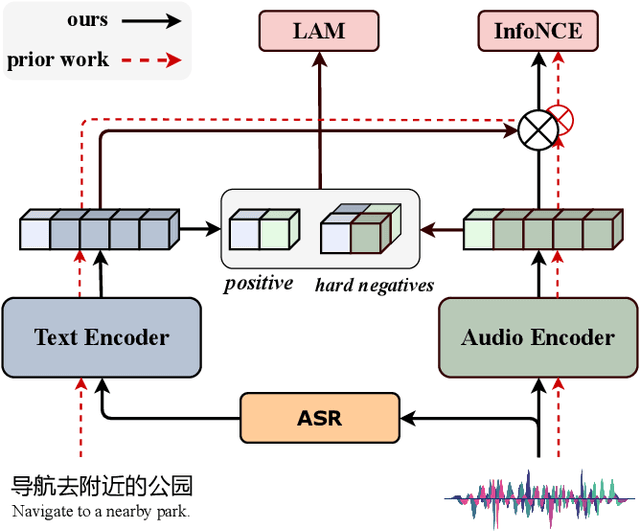
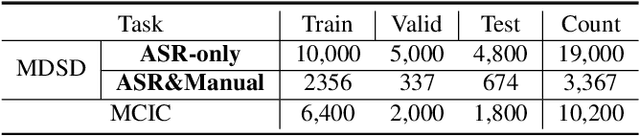
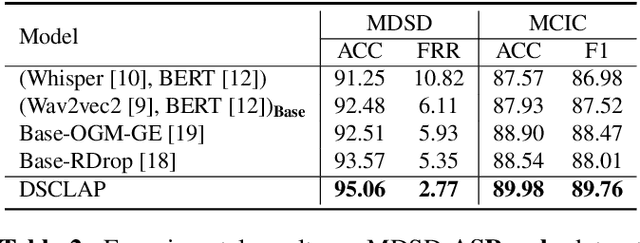
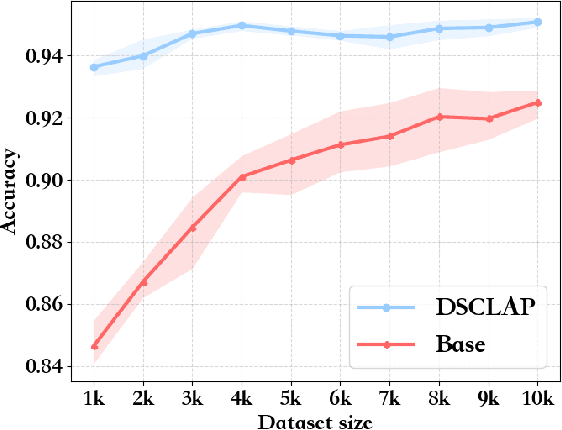
Analyzing real-world multimodal signals is an essential and challenging task for intelligent voice assistants (IVAs). Mainstream approaches have achieved remarkable performance on various downstream tasks of IVAs with pre-trained audio models and text models. However, these models are pre-trained independently and usually on tasks different from target domains, resulting in sub-optimal modality representations for downstream tasks. Moreover, in many domains, collecting enough language-audio pairs is extremely hard, and transcribing raw audio also requires high professional skills, making it difficult or even infeasible to joint pre-training. To address these painpoints, we propose DSCLAP, a simple and effective framework that enables language-audio pre-training with only raw audio signal input. Specifically, DSCLAP converts raw audio signals into text via an ASR system and combines a contrastive learning objective and a language-audio matching objective to align the audio and ASR transcriptions. We pre-train DSCLAP on 12,107 hours of in-vehicle domain audio. Empirical results on two downstream tasks show that while conceptually simple, DSCLAP significantly outperforms the baseline models in all metrics, showing great promise for domain-specific IVAs applications.
M$^{3}$V: A multi-modal multi-view approach for Device-Directed Speech Detection
Sep 14, 2024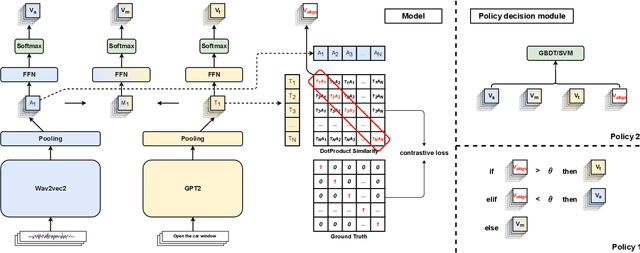

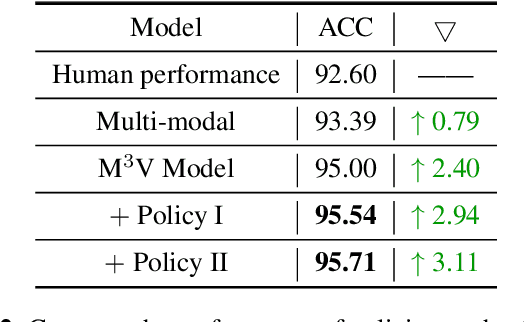
With the goal of more natural and human-like interaction with virtual voice assistants, recent research in the field has focused on full duplex interaction mode without relying on repeated wake-up words. This requires that in scenes with complex sound sources, the voice assistant must classify utterances as device-oriented or non-device-oriented. The dual-encoder structure, which is jointly modeled by text and speech, has become the paradigm of device-directed speech detection. However, in practice, these models often produce incorrect predictions for unaligned input pairs due to the unavoidable errors of automatic speech recognition (ASR).To address this challenge, we propose M$^{3}$V, a multi-modal multi-view approach for device-directed speech detection, which frames we frame the problem as a multi-view learning task that introduces unimodal views and a text-audio alignment view in the network besides the multi-modal. Experimental results show that M$^{3}$V significantly outperforms models trained using only single or multi-modality and surpasses human judgment performance on ASR error data for the first time.
Point-Voxel Transformer: An Efficient Approach To 3D Deep Learning
Aug 13, 2021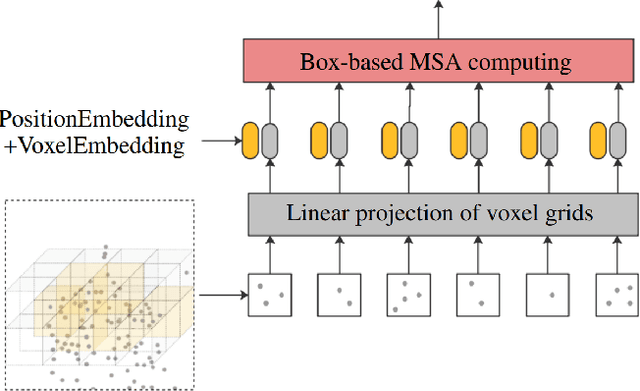
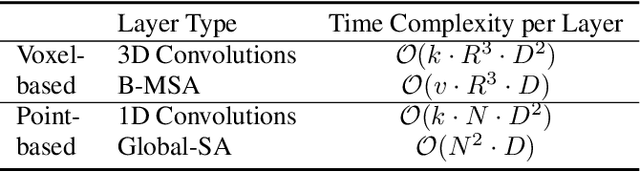
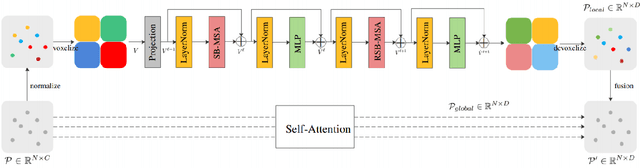
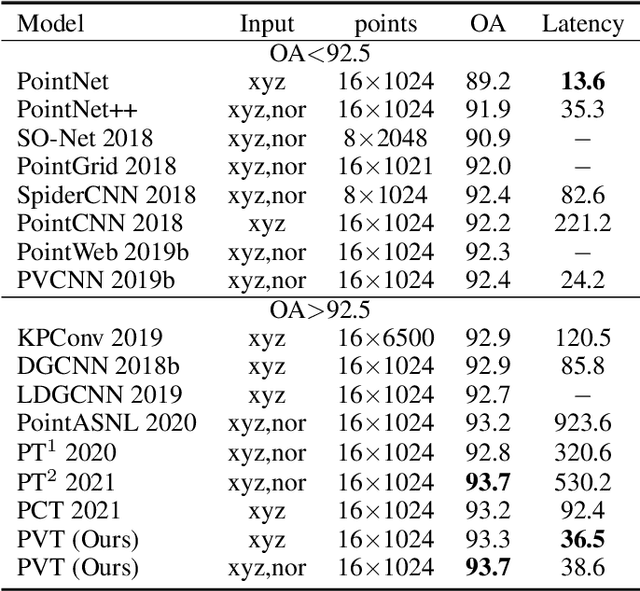
Due to the sparsity and irregularity of the 3D data, approaches that directly process points have become popular. Among all point-based models, Transformer-based models have achieved state-of-the-art performance by fully preserving point interrelation. However, most of them spend high percentage of total time on sparse data accessing (e.g., Farthest Point Sampling (FPS) and neighbor points query), which becomes the computation burden. Therefore, we present a novel 3D Transformer, called Point-Voxel Transformer (PVT) that leverages self-attention computation in points to gather global context features, while performing multi-head self-attention (MSA) computation in voxels to capture local information and reduce the irregular data access. Additionally, to further reduce the cost of MSA computation, we design a cyclic shifted boxing scheme which brings greater efficiency by limiting the MSA computation to non-overlapping local boxes while also preserving cross-box connection. Our method fully exploits the potentials of Transformer architecture, paving the road to efficient and accurate recognition results. Evaluated on classification and segmentation benchmarks, our PVT not only achieves strong accuracy but outperforms previous state-of-the-art Transformer-based models with 9x measured speedup on average. For 3D object detection task, we replace the primitives in Frustrum PointNet with PVT layer and achieve the improvement of 8.6%.