 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards One-to-Many Temporal Grounding
Jun 04, 2026Temporal Grounding (TG) aims to localize video segments corresponding to a textual query. Prior research predominantly focuses on single-segment retrieval. Real-world scenarios, however, often require localizing multiple disjoint segments for a single query -- a setting we term One-to-Many Temporal Grounding (OMTG). Previous state-of-the-art MLLMs, optimized for one-to-one settings, struggle in this context, often yielding near-zero scores due to a lack of event cardinality perception. To bridge this gap, we present a systematic solution with three key contributions. First, we establish the first comprehensive OMTG benchmark, introducing Count Accuracy (C-Acc) and Effective Temporal F1 (EtF1) as evaluation metrics. Second, we curate a high-quality OMTG dataset comprising 56k samples through a sophisticated construction pipeline. Third, we develop novel temporal and caption reward functions specifically designed for OMTG. In particular, the caption reward leverages Chain-of-Thought reasoning over dense video captions to explicitly guide policy optimization toward both preciseness and completeness. Extensive experiments show our model achieves a new state-of-the-art EtF1 of 43.65\% on OMTG Bench, outperforming Gemini 2.5 Pro and Seed-1.8 by 15.85\% and 15.61\%, respectively.
MergeTok: Unified Continuous and Discrete Visual Tokenization via Token Merging
May 29, 2026Most visual tokenizers for image generation are bifurcated into two families with complementary limitations: continuous VAEs offer high-fidelity reconstruction but suffer from dense, entangled latents that are poorly suited for semantic control, whereas discrete VQ-based models enable autoregressive generation yet struggle with gradient sparsity, unstable training, and codebook collapse. In this work, we introduce MergeTok, a unified tokenizer that jointly optimizes continuous (VAE) and discrete (VQ) tokenizers within a encoder-decoder architecture, leveraging token merging techniques as a semantic bridge. By clustering similar tokens during encoding, MergeTok establishes a structural prior that provides dual supervision signals: (i) it imposes merged-token semantic alignment in the VAE branch, regularizing its latent space toward disentangled, semantic-aware representations; (ii) it derives group-wise constraints, promoting intra-group diversity and inter-group exclusivity that stabilize VQ training. MergeTok shows competitive reconstruction and generation performance on ImageNet-256, with substantially lower rFID than strong VAE and VQ models under matched token budgets, while producing semantically-organized token representations compatible with both autoregressive and diffusion generators. This shows that a single architecture can endow visual tokenizers with robust semantic organization and generator-friendly discreteness.
MergeDNA: Context-aware Genome Modeling with Dynamic Tokenization through Token Merging
Nov 17, 2025



Modeling genomic sequences faces two unsolved challenges: the information density varies widely across different regions, while there is no clearly defined minimum vocabulary unit. Relying on either four primitive bases or independently designed DNA tokenizers, existing approaches with naive masked language modeling pre-training often fail to adapt to the varying complexities of genomic sequences. Leveraging Token Merging techniques, this paper introduces a hierarchical architecture that jointly optimizes a dynamic genomic tokenizer and latent Transformers with context-aware pre-training tasks. As for network structures, the tokenization module automatically chunks adjacent bases into words by stacking multiple layers of the differentiable token merging blocks with local-window constraints, then a Latent Encoder captures the global context of these merged words by full-attention blocks. Symmetrically employing a Latent Decoder and a Local Decoder, MergeDNA learns with two pre-training tasks: Merged Token Reconstruction simultaneously trains the dynamic tokenization module and adaptively filters important tokens, while Adaptive Masked Token Modeling learns to predict these filtered tokens to capture informative contents. Extensive experiments show that MergeDNA achieves superior performance on three popular DNA benchmarks and several multi-omics tasks with fine-tuning or zero-shot evaluation, outperforming typical tokenization methods and large-scale DNA foundation models.
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
Evaluating Compositional Scene Understanding in Multimodal Generative Models
Mar 29, 2025



The visual world is fundamentally compositional. Visual scenes are defined by the composition of objects and their relations. Hence, it is essential for computer vision systems to reflect and exploit this compositionality to achieve robust and generalizable scene understanding. While major strides have been made toward the development of general-purpose, multimodal generative models, including both text-to-image models and multimodal vision-language models, it remains unclear whether these systems are capable of accurately generating and interpreting scenes involving the composition of multiple objects and relations. In this work, we present an evaluation of the compositional visual processing capabilities in the current generation of text-to-image (DALL-E 3) and multimodal vision-language models (GPT-4V, GPT-4o, Claude Sonnet 3.5, QWEN2-VL-72B, and InternVL2.5-38B), and compare the performance of these systems to human participants. The results suggest that these systems display some ability to solve compositional and relational tasks, showing notable improvements over the previous generation of multimodal models, but with performance nevertheless well below the level of human participants, particularly for more complex scenes involving many ($>5$) objects and multiple relations. These results highlight the need for further progress toward compositional understanding of visual scenes.
A Framework for Evaluating Emerging Cyberattack Capabilities of AI
Mar 14, 2025As frontier models become more capable, the community has attempted to evaluate their ability to enable cyberattacks. Performing a comprehensive evaluation and prioritizing defenses are crucial tasks in preparing for AGI safely. However, current cyber evaluation efforts are ad-hoc, with no systematic reasoning about the various phases of attacks, and do not provide a steer on how to use targeted defenses. In this work, we propose a novel approach to AI cyber capability evaluation that (1) examines the end-to-end attack chain, (2) helps to identify gaps in the evaluation of AI threats, and (3) helps defenders prioritize targeted mitigations and conduct AI-enabled adversary emulation to support red teaming. To achieve these goals, we propose adapting existing cyberattack chain frameworks to AI systems. We analyze over 12,000 instances of real-world attempts to use AI in cyberattacks catalogued by Google's Threat Intelligence Group. Using this analysis, we curate a representative collection of seven cyberattack chain archetypes and conduct a bottleneck analysis to identify areas of potential AI-driven cost disruption. Our evaluation benchmark consists of 50 new challenges spanning different phases of cyberattacks. Based on this, we devise targeted cybersecurity model evaluations, report on the potential for AI to amplify offensive cyber capabilities across specific attack phases, and conclude with recommendations on prioritizing defenses. In all, we consider this to be the most comprehensive AI cyber risk evaluation framework published so far.
DSCLAP: Domain-Specific Contrastive Language-Audio Pre-Training
Sep 14, 2024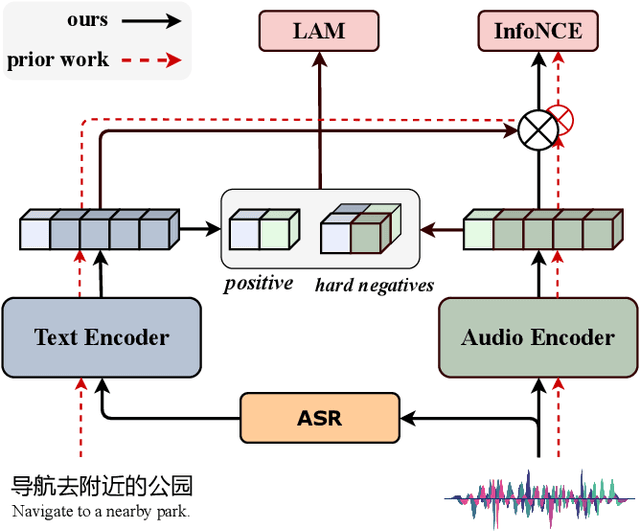
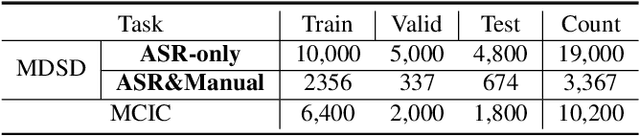
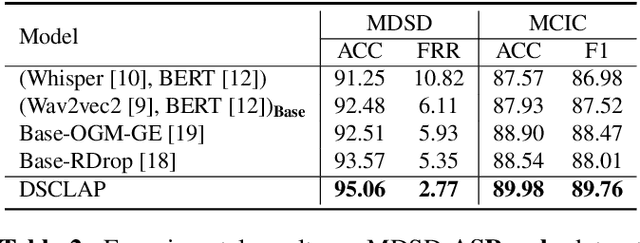
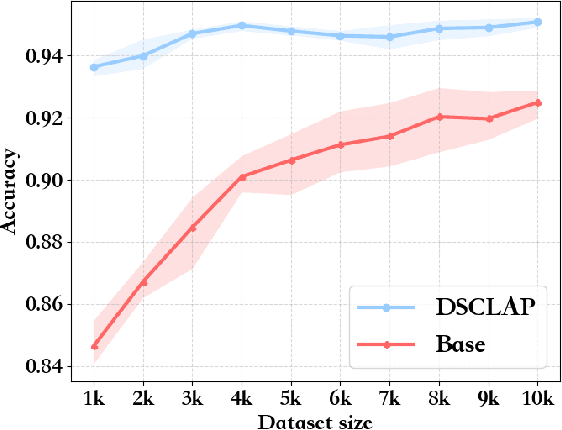
Analyzing real-world multimodal signals is an essential and challenging task for intelligent voice assistants (IVAs). Mainstream approaches have achieved remarkable performance on various downstream tasks of IVAs with pre-trained audio models and text models. However, these models are pre-trained independently and usually on tasks different from target domains, resulting in sub-optimal modality representations for downstream tasks. Moreover, in many domains, collecting enough language-audio pairs is extremely hard, and transcribing raw audio also requires high professional skills, making it difficult or even infeasible to joint pre-training. To address these painpoints, we propose DSCLAP, a simple and effective framework that enables language-audio pre-training with only raw audio signal input. Specifically, DSCLAP converts raw audio signals into text via an ASR system and combines a contrastive learning objective and a language-audio matching objective to align the audio and ASR transcriptions. We pre-train DSCLAP on 12,107 hours of in-vehicle domain audio. Empirical results on two downstream tasks show that while conceptually simple, DSCLAP significantly outperforms the baseline models in all metrics, showing great promise for domain-specific IVAs applications.
Turbo your multi-modal classification with contrastive learning
Sep 14, 2024



Contrastive learning has become one of the most impressive approaches for multi-modal representation learning. However, previous multi-modal works mainly focused on cross-modal understanding, ignoring in-modal contrastive learning, which limits the representation of each modality. In this paper, we propose a novel contrastive learning strategy, called $Turbo$, to promote multi-modal understanding by joint in-modal and cross-modal contrastive learning. Specifically, multi-modal data pairs are sent through the forward pass twice with different hidden dropout masks to get two different representations for each modality. With these representations, we obtain multiple in-modal and cross-modal contrastive objectives for training. Finally, we combine the self-supervised Turbo with the supervised multi-modal classification and demonstrate its effectiveness on two audio-text classification tasks, where the state-of-the-art performance is achieved on a speech emotion recognition benchmark dataset.
M$^{3}$V: A multi-modal multi-view approach for Device-Directed Speech Detection
Sep 14, 2024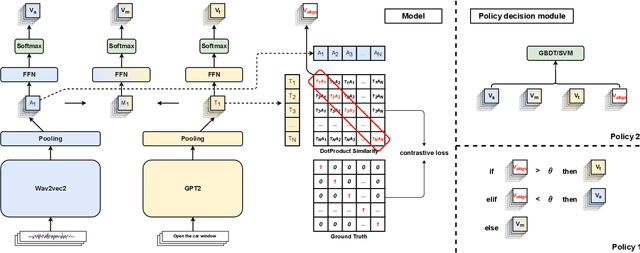

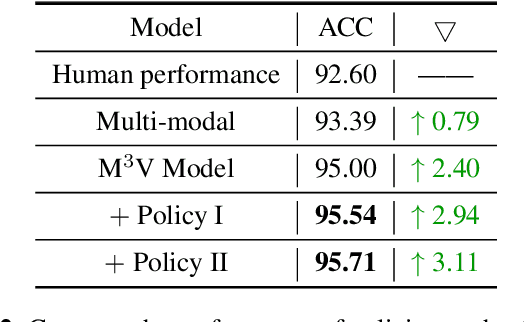
With the goal of more natural and human-like interaction with virtual voice assistants, recent research in the field has focused on full duplex interaction mode without relying on repeated wake-up words. This requires that in scenes with complex sound sources, the voice assistant must classify utterances as device-oriented or non-device-oriented. The dual-encoder structure, which is jointly modeled by text and speech, has become the paradigm of device-directed speech detection. However, in practice, these models often produce incorrect predictions for unaligned input pairs due to the unavoidable errors of automatic speech recognition (ASR).To address this challenge, we propose M$^{3}$V, a multi-modal multi-view approach for device-directed speech detection, which frames we frame the problem as a multi-view learning task that introduces unimodal views and a text-audio alignment view in the network besides the multi-modal. Experimental results show that M$^{3}$V significantly outperforms models trained using only single or multi-modality and surpasses human judgment performance on ASR error data for the first time.
Deep learning-assisted imaging through stationary scattering media
Feb 25, 2022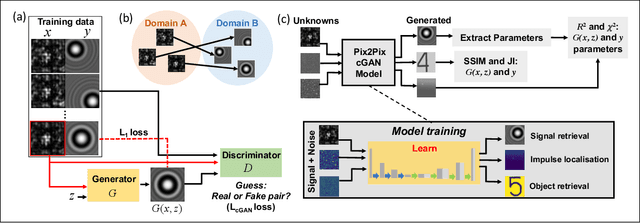
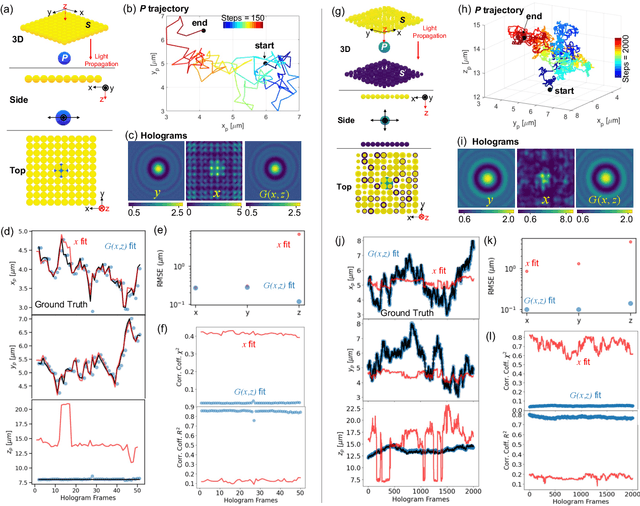
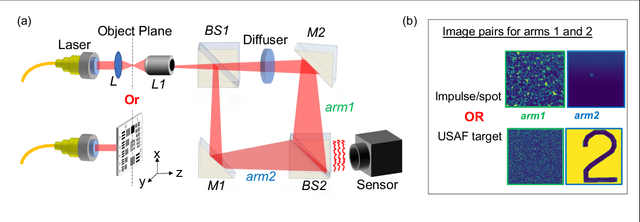
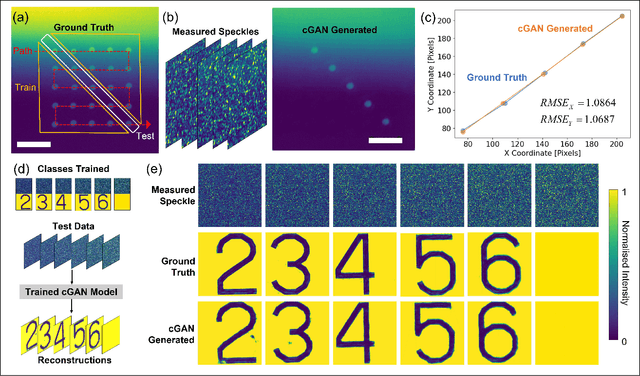
Imaging through scattering media is a challenging problem owing to speckle decorrelations from perturbations in the media itself. For in-line imaging modalities, which are appealing because they are compact, require no moving parts, and are robust, negating the effects of such scattering becomes particularly challenging. Here we explore the effect of stationary scattering media on light scattering in in-line geometries, including digital holographic microscopy. We consider various object-scatterer scenarios where the object is distorted or obscured by additional stationary scatterers, and use an advanced deep learning (DL) generative methodology, generative adversarial networks (GANs), to mitigate the effects of the additional scatterers. Using light scattering simulations and experiments on objects of interest with and without additional scatterers, we find that conditional GANs can be quickly trained with minuscule datasets and can also efficiently learn the one-to-one statistical mapping between the cross-domain input-output image pairs. Training such a network yields a standalone model, that can be used later to inverse or negate the effect of scattering, yielding clear object reconstructions for object retrieval and downstream processing. Moreover, it is well-known that the coherent point spread function (c-PSF) of a stationary scattering optical system is a speckle pattern which is spatially shift variant. We show that with rapid training using only 20 image pairs, it is possible to negate this undesired scattering to accurately localize diffraction-limited impulses with high spatial accuracy, therefore transforming the earlier shift variant system to a linear shift invariant (LSI) system.