 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Spatial Augmentation for Semi-supervised Semantic Segmentation
May 29, 2025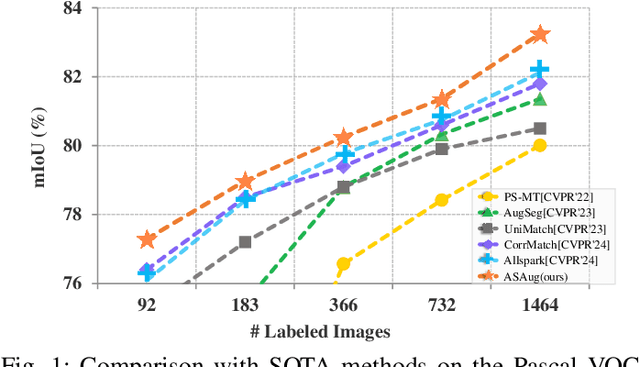
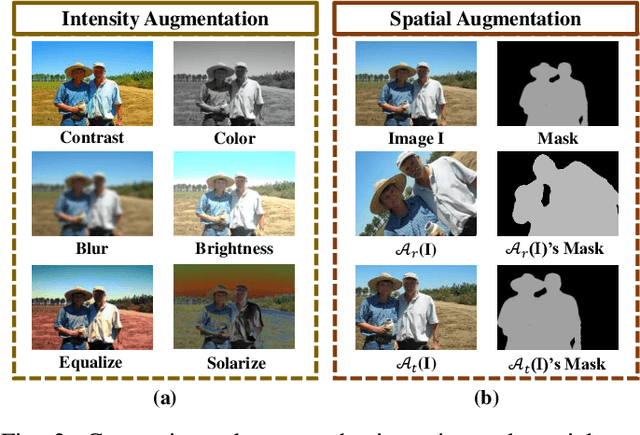
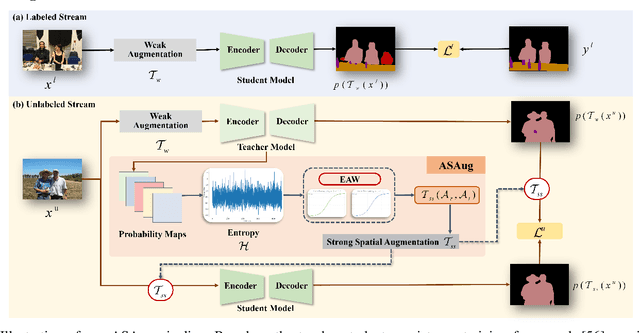
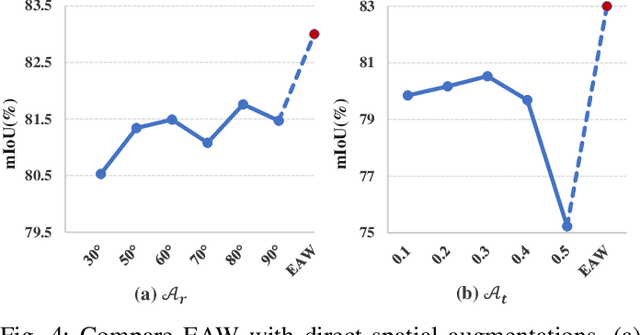
In semi-supervised semantic segmentation (SSSS), data augmentation plays a crucial role in the weak-to-strong consistency regularization framework, as it enhances diversity and improves model generalization. Recent strong augmentation methods have primarily focused on intensity-based perturbations, which have minimal impact on the semantic masks. In contrast, spatial augmentations like translation and rotation have long been acknowledged for their effectiveness in supervised semantic segmentation tasks, but they are often ignored in SSSS. In this work, we demonstrate that spatial augmentation can also contribute to model training in SSSS, despite generating inconsistent masks between the weak and strong augmentations. Furthermore, recognizing the variability among images, we propose an adaptive augmentation strategy that dynamically adjusts the augmentation for each instance based on entropy. Extensive experiments show that our proposed Adaptive Spatial Augmentation (\textbf{ASAug}) can be integrated as a pluggable module, consistently improving the performance of existing methods and achieving state-of-the-art results on benchmark datasets such as PASCAL VOC 2012, Cityscapes, and COCO.
One for All: Multi-Domain Joint Training for Point Cloud Based 3D Object Detection
Nov 03, 2024
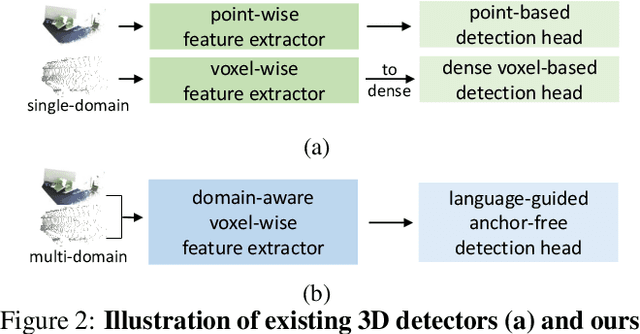
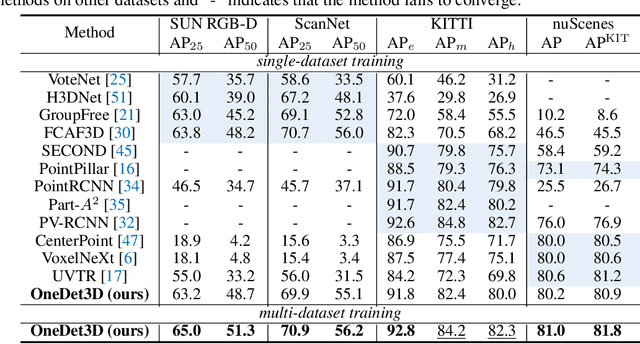
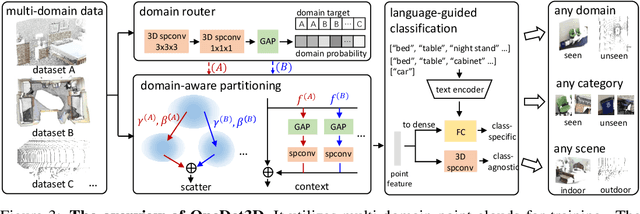
The current trend in computer vision is to utilize one universal model to address all various tasks. Achieving such a universal model inevitably requires incorporating multi-domain data for joint training to learn across multiple problem scenarios. In point cloud based 3D object detection, however, such multi-domain joint training is highly challenging, because large domain gaps among point clouds from different datasets lead to the severe domain-interference problem. In this paper, we propose \textbf{OneDet3D}, a universal one-for-all model that addresses 3D detection across different domains, including diverse indoor and outdoor scenes, within the \emph{same} framework and only \emph{one} set of parameters. We propose the domain-aware partitioning in scatter and context, guided by a routing mechanism, to address the data interference issue, and further incorporate the text modality for a language-guided classification to unify the multi-dataset label spaces and mitigate the category interference issue. The fully sparse structure and anchor-free head further accommodate point clouds with significant scale disparities. Extensive experiments demonstrate the strong universal ability of OneDet3D to utilize only one trained model for addressing almost all 3D object detection tasks.
Turbo your multi-modal classification with contrastive learning
Sep 14, 2024



Contrastive learning has become one of the most impressive approaches for multi-modal representation learning. However, previous multi-modal works mainly focused on cross-modal understanding, ignoring in-modal contrastive learning, which limits the representation of each modality. In this paper, we propose a novel contrastive learning strategy, called $Turbo$, to promote multi-modal understanding by joint in-modal and cross-modal contrastive learning. Specifically, multi-modal data pairs are sent through the forward pass twice with different hidden dropout masks to get two different representations for each modality. With these representations, we obtain multiple in-modal and cross-modal contrastive objectives for training. Finally, we combine the self-supervised Turbo with the supervised multi-modal classification and demonstrate its effectiveness on two audio-text classification tasks, where the state-of-the-art performance is achieved on a speech emotion recognition benchmark dataset.
M$^{3}$V: A multi-modal multi-view approach for Device-Directed Speech Detection
Sep 14, 2024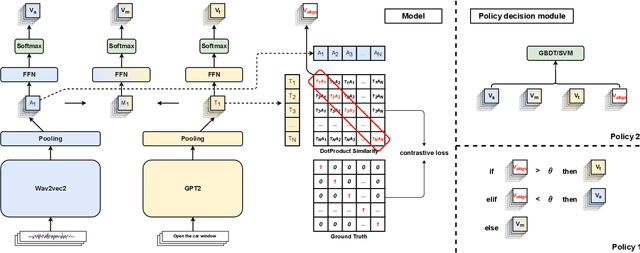

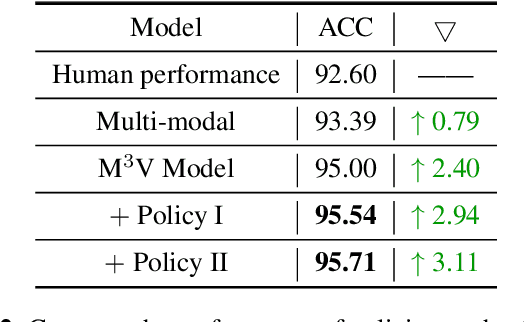
With the goal of more natural and human-like interaction with virtual voice assistants, recent research in the field has focused on full duplex interaction mode without relying on repeated wake-up words. This requires that in scenes with complex sound sources, the voice assistant must classify utterances as device-oriented or non-device-oriented. The dual-encoder structure, which is jointly modeled by text and speech, has become the paradigm of device-directed speech detection. However, in practice, these models often produce incorrect predictions for unaligned input pairs due to the unavoidable errors of automatic speech recognition (ASR).To address this challenge, we propose M$^{3}$V, a multi-modal multi-view approach for device-directed speech detection, which frames we frame the problem as a multi-view learning task that introduces unimodal views and a text-audio alignment view in the network besides the multi-modal. Experimental results show that M$^{3}$V significantly outperforms models trained using only single or multi-modality and surpasses human judgment performance on ASR error data for the first time.
DSCLAP: Domain-Specific Contrastive Language-Audio Pre-Training
Sep 14, 2024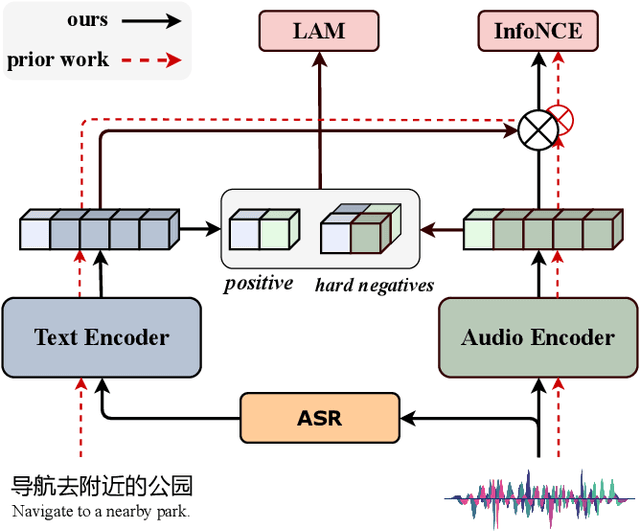
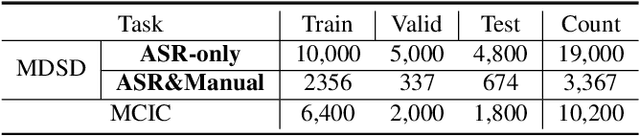
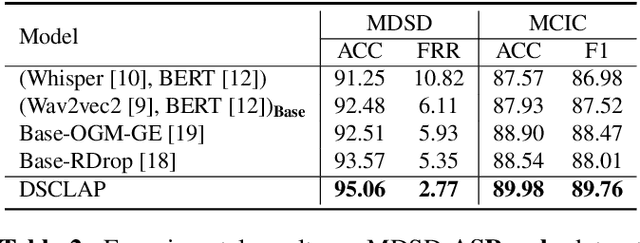
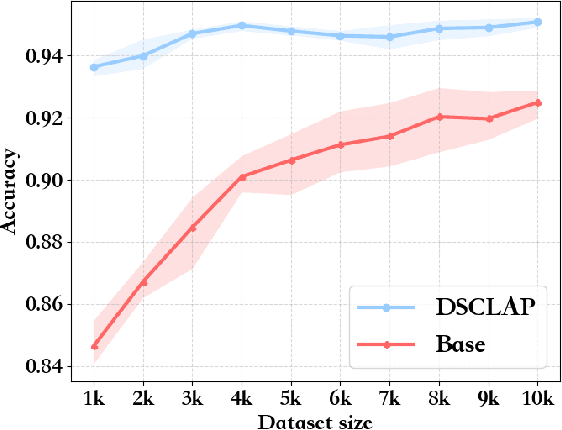
Analyzing real-world multimodal signals is an essential and challenging task for intelligent voice assistants (IVAs). Mainstream approaches have achieved remarkable performance on various downstream tasks of IVAs with pre-trained audio models and text models. However, these models are pre-trained independently and usually on tasks different from target domains, resulting in sub-optimal modality representations for downstream tasks. Moreover, in many domains, collecting enough language-audio pairs is extremely hard, and transcribing raw audio also requires high professional skills, making it difficult or even infeasible to joint pre-training. To address these painpoints, we propose DSCLAP, a simple and effective framework that enables language-audio pre-training with only raw audio signal input. Specifically, DSCLAP converts raw audio signals into text via an ASR system and combines a contrastive learning objective and a language-audio matching objective to align the audio and ASR transcriptions. We pre-train DSCLAP on 12,107 hours of in-vehicle domain audio. Empirical results on two downstream tasks show that while conceptually simple, DSCLAP significantly outperforms the baseline models in all metrics, showing great promise for domain-specific IVAs applications.
Diffusion Model Meets Non-Exemplar Class-Incremental Learning and Beyond
Aug 06, 2024



Non-exemplar class-incremental learning (NECIL) is to resist catastrophic forgetting without saving old class samples. Prior methodologies generally employ simple rules to generate features for replaying, suffering from large distribution gap between replayed features and real ones. To address the aforementioned issue, we propose a simple, yet effective \textbf{Diff}usion-based \textbf{F}eature \textbf{R}eplay (\textbf{DiffFR}) method for NECIL. First, to alleviate the limited representational capacity caused by fixing the feature extractor, we employ Siamese-based self-supervised learning for initial generalizable features. Second, we devise diffusion models to generate class-representative features highly similar to real features, which provides an effective way for exemplar-free knowledge memorization. Third, we introduce prototype calibration to direct the diffusion model's focus towards learning the distribution shapes of features, rather than the entire distribution. Extensive experiments on public datasets demonstrate significant performance gains of our DiffFR, outperforming the state-of-the-art NECIL methods by 3.0\% in average. The code will be made publicly available soon.
Map Optical Properties to Subwavelength Structures Directly via a Diffusion Model
Apr 09, 2024



Subwavelength photonic structures and metamaterials provide revolutionary approaches for controlling light. The inverse design methods proposed for these subwavelength structures are vital to the development of new photonic devices. However, most of the existing inverse design methods cannot realize direct mapping from optical properties to photonic structures but instead rely on forward simulation methods to perform iterative optimization. In this work, we exploit the powerful generative abilities of artificial intelligence (AI) and propose a practical inverse design method based on latent diffusion models. Our method maps directly the optical properties to structures without the requirement of forward simulation and iterative optimization. Here, the given optical properties can work as "prompts" and guide the constructed model to correctly "draw" the required photonic structures. Experiments show that our direct mapping-based inverse design method can generate subwavelength photonic structures at high fidelity while following the given optical properties. This may change the method used for optical design and greatly accelerate the research on new photonic devices.
OV-Uni3DETR: Towards Unified Open-Vocabulary 3D Object Detection via Cycle-Modality Propagation
Mar 28, 2024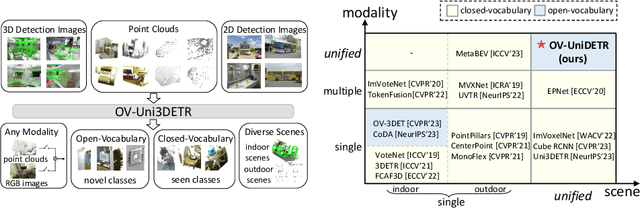
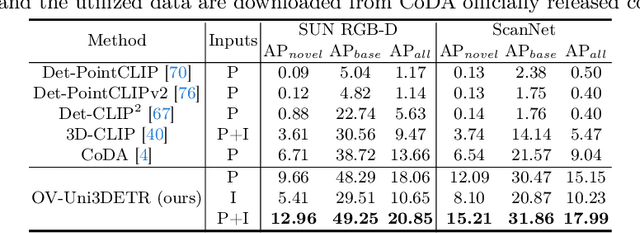
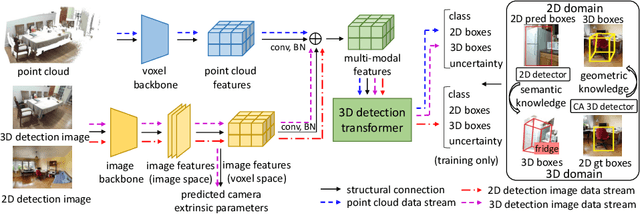
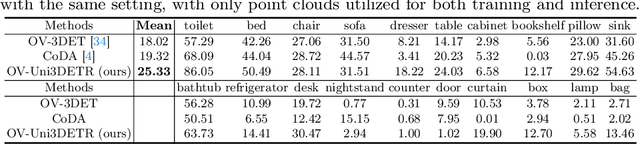
In the current state of 3D object detection research, the severe scarcity of annotated 3D data, substantial disparities across different data modalities, and the absence of a unified architecture, have impeded the progress towards the goal of universality. In this paper, we propose \textbf{OV-Uni3DETR}, a unified open-vocabulary 3D detector via cycle-modality propagation. Compared with existing 3D detectors, OV-Uni3DETR offers distinct advantages: 1) Open-vocabulary 3D detection: During training, it leverages various accessible data, especially extensive 2D detection images, to boost training diversity. During inference, it can detect both seen and unseen classes. 2) Modality unifying: It seamlessly accommodates input data from any given modality, effectively addressing scenarios involving disparate modalities or missing sensor information, thereby supporting test-time modality switching. 3) Scene unifying: It provides a unified multi-modal model architecture for diverse scenes collected by distinct sensors. Specifically, we propose the cycle-modality propagation, aimed at propagating knowledge bridging 2D and 3D modalities, to support the aforementioned functionalities. 2D semantic knowledge from large-vocabulary learning guides novel class discovery in the 3D domain, and 3D geometric knowledge provides localization supervision for 2D detection images. OV-Uni3DETR achieves the state-of-the-art performance on various scenarios, surpassing existing methods by more than 6\% on average. Its performance using only RGB images is on par with or even surpasses that of previous point cloud based methods. Code and pre-trained models will be released later.
Semi-Supervised Semantic Segmentation Based on Pseudo-Labels: A Survey
Mar 04, 2024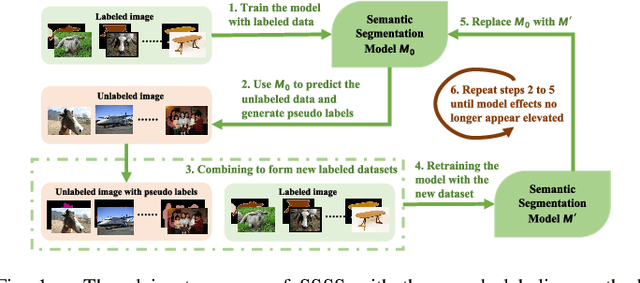
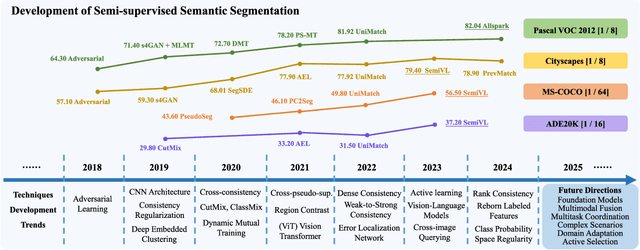
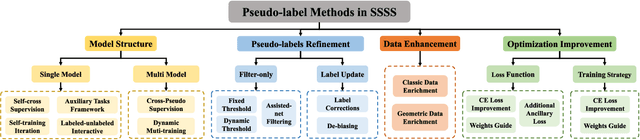
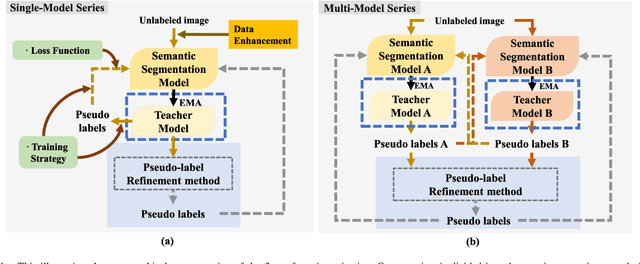
Semantic segmentation is an important and popular research area in computer vision that focuses on classifying pixels in an image based on their semantics. However, supervised deep learning requires large amounts of data to train models and the process of labeling images pixel by pixel is time-consuming and laborious. This review aims to provide a first comprehensive and organized overview of the state-of-the-art research results on pseudo-label methods in the field of semi-supervised semantic segmentation, which we categorize from different perspectives and present specific methods for specific application areas. In addition, we explore the application of pseudo-label technology in medical and remote-sensing image segmentation. Finally, we also propose some feasible future research directions to address the existing challenges.
Uni3DETR: Unified 3D Detection Transformer
Oct 09, 2023Existing point cloud based 3D detectors are designed for the particular scene, either indoor or outdoor ones. Because of the substantial differences in object distribution and point density within point clouds collected from various environments, coupled with the intricate nature of 3D metrics, there is still a lack of a unified network architecture that can accommodate diverse scenes. In this paper, we propose Uni3DETR, a unified 3D detector that addresses indoor and outdoor 3D detection within the same framework. Specifically, we employ the detection transformer with point-voxel interaction for object prediction, which leverages voxel features and points for cross-attention and behaves resistant to the discrepancies from data. We then propose the mixture of query points, which sufficiently exploits global information for dense small-range indoor scenes and local information for large-range sparse outdoor ones. Furthermore, our proposed decoupled IoU provides an easy-to-optimize training target for localization by disentangling the xy and z space. Extensive experiments validate that Uni3DETR exhibits excellent performance consistently on both indoor and outdoor 3D detection. In contrast to previous specialized detectors, which may perform well on some particular datasets but suffer a substantial degradation on different scenes, Uni3DETR demonstrates the strong generalization ability under heterogeneous conditions (Fig. 1). Codes are available at \href{https://github.com/zhenyuw16/Uni3DETR}{https://github.com/zhenyuw16/Uni3DETR}.