 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^{3}$V: A multi-modal multi-view approach for Device-Directed Speech Detection
Paper and Code
Sep 14, 2024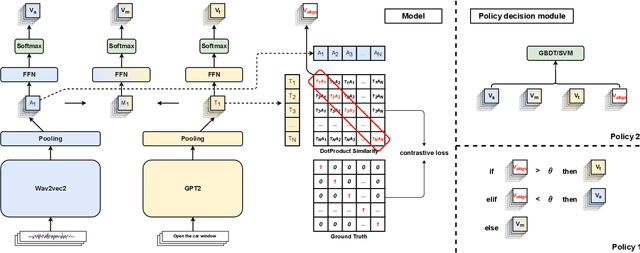

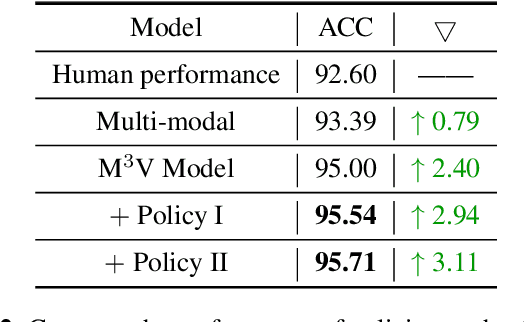
With the goal of more natural and human-like interaction with virtual voice assistants, recent research in the field has focused on full duplex interaction mode without relying on repeated wake-up words. This requires that in scenes with complex sound sources, the voice assistant must classify utterances as device-oriented or non-device-oriented. The dual-encoder structure, which is jointly modeled by text and speech, has become the paradigm of device-directed speech detection. However, in practice, these models often produce incorrect predictions for unaligned input pairs due to the unavoidable errors of automatic speech recognition (ASR).To address this challenge, we propose M$^{3}$V, a multi-modal multi-view approach for device-directed speech detection, which frames we frame the problem as a multi-view learning task that introduces unimodal views and a text-audio alignment view in the network besides the multi-modal. Experimental results show that M$^{3}$V significantly outperforms models trained using only single or multi-modality and surpasses human judgment performance on ASR error data for the first time.