 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Human-Robot Surgery for Mandibular Angle Split Osteotomy: Optical Tracking based Approach
Jul 10, 2025Mandibular Angle Split Osteotomy (MASO) is a significant procedure in oral and maxillofacial surgery. Despite advances in technique and instrumentation, its success still relies heavily on the surgeon's experience. In this work, a human-robot collaborative system is proposed to perform MASO according to a preoperative plan and under guidance of a surgeon. A task decomposition methodology is used to divide the collaborative surgical procedure into three subtasks: (1) positional control and (2) orientation control, both led by the robot for precise alignment; and (3) force-control, managed by surgeon to ensure safety. Additionally, to achieve patient tracking without the need for a skull clamp, an optical tracking system (OTS) is utilized. Movement of the patient mandibular is measured with an optical-based tracker mounted on a dental occlusal splint. A registration method and Robot-OTS calibration method are introduced to achieve reliable navigation within our framework. The experiments of drilling were conducted on the realistic phantom model, which demonstrated that the average error between the planned and actual drilling points is 1.85mm.
Turbo your multi-modal classification with contrastive learning
Sep 14, 2024



Contrastive learning has become one of the most impressive approaches for multi-modal representation learning. However, previous multi-modal works mainly focused on cross-modal understanding, ignoring in-modal contrastive learning, which limits the representation of each modality. In this paper, we propose a novel contrastive learning strategy, called $Turbo$, to promote multi-modal understanding by joint in-modal and cross-modal contrastive learning. Specifically, multi-modal data pairs are sent through the forward pass twice with different hidden dropout masks to get two different representations for each modality. With these representations, we obtain multiple in-modal and cross-modal contrastive objectives for training. Finally, we combine the self-supervised Turbo with the supervised multi-modal classification and demonstrate its effectiveness on two audio-text classification tasks, where the state-of-the-art performance is achieved on a speech emotion recognition benchmark dataset.
DSCLAP: Domain-Specific Contrastive Language-Audio Pre-Training
Sep 14, 2024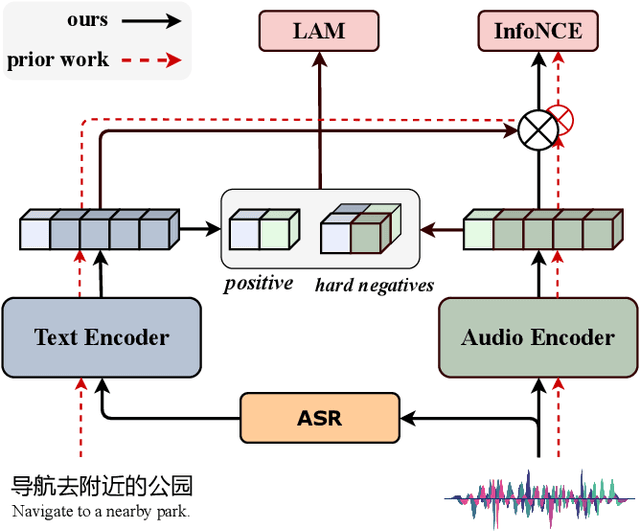
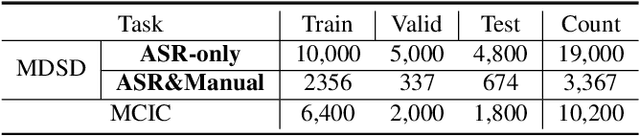
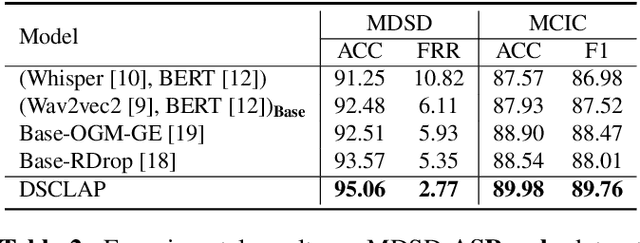
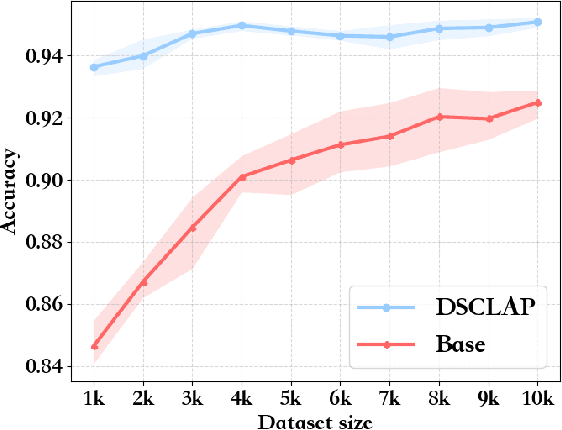
Analyzing real-world multimodal signals is an essential and challenging task for intelligent voice assistants (IVAs). Mainstream approaches have achieved remarkable performance on various downstream tasks of IVAs with pre-trained audio models and text models. However, these models are pre-trained independently and usually on tasks different from target domains, resulting in sub-optimal modality representations for downstream tasks. Moreover, in many domains, collecting enough language-audio pairs is extremely hard, and transcribing raw audio also requires high professional skills, making it difficult or even infeasible to joint pre-training. To address these painpoints, we propose DSCLAP, a simple and effective framework that enables language-audio pre-training with only raw audio signal input. Specifically, DSCLAP converts raw audio signals into text via an ASR system and combines a contrastive learning objective and a language-audio matching objective to align the audio and ASR transcriptions. We pre-train DSCLAP on 12,107 hours of in-vehicle domain audio. Empirical results on two downstream tasks show that while conceptually simple, DSCLAP significantly outperforms the baseline models in all metrics, showing great promise for domain-specific IVAs applications.
M$^{3}$V: A multi-modal multi-view approach for Device-Directed Speech Detection
Sep 14, 2024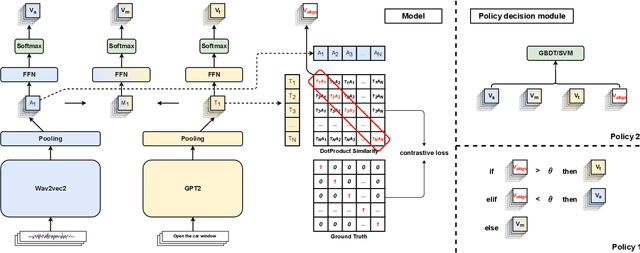

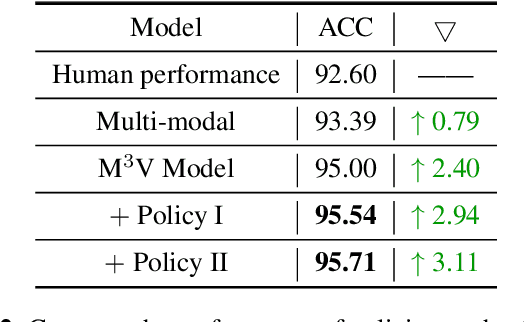
With the goal of more natural and human-like interaction with virtual voice assistants, recent research in the field has focused on full duplex interaction mode without relying on repeated wake-up words. This requires that in scenes with complex sound sources, the voice assistant must classify utterances as device-oriented or non-device-oriented. The dual-encoder structure, which is jointly modeled by text and speech, has become the paradigm of device-directed speech detection. However, in practice, these models often produce incorrect predictions for unaligned input pairs due to the unavoidable errors of automatic speech recognition (ASR).To address this challenge, we propose M$^{3}$V, a multi-modal multi-view approach for device-directed speech detection, which frames we frame the problem as a multi-view learning task that introduces unimodal views and a text-audio alignment view in the network besides the multi-modal. Experimental results show that M$^{3}$V significantly outperforms models trained using only single or multi-modality and surpasses human judgment performance on ASR error data for the first time.
Interpretable machine learning-accelerated seed treatment by nanomaterials for environmental stress alleviation
Apr 08, 2023Crops are constantly challenged by different environmental conditions. Seed treatment by nanomaterials is a cost-effective and environmentally-friendly solution for environmental stress mitigation in crop plants. Here, 56 seed nanopriming treatments are used to alleviate environmental stresses in maize. Seven selected nanopriming treatments significantly increase the stress resistance index (SRI) by 13.9% and 12.6% under salinity stress and combined heat-drought stress, respectively. Metabolomics data reveals that ZnO nanopriming treatment, with the highest SRI value, mainly regulates the pathways of amino acid metabolism, secondary metabolite synthesis, carbohydrate metabolism, and translation. Understanding the mechanism of seed nanopriming is still difficult due to the variety of nanomaterials and the complexity of interactions between nanomaterials and plants. Using the nanopriming data, we present an interpretable structure-activity relationship (ISAR) approach based on interpretable machine learning for predicting and understanding its stress mitigation effects. The post hoc and model-based interpretation approaches of machine learning are combined to provide complementary benefits and give researchers or policymakers more illuminating or trustworthy results. The concentration, size, and zeta potential of nanoparticles are identified as dominant factors for correlating root dry weight under salinity stress, and their effects and interactions are explained. Additionally, a web-based interactive tool is developed for offering prediction-level interpretation and gathering more details about specific nanopriming treatments. This work offers a promising framework for accelerating the agricultural applications of nanomaterials and may profoundly contribute to nanosafety assessment.