 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSCLAP: Domain-Specific Contrastive Language-Audio Pre-Training
Paper and Code
Sep 14, 2024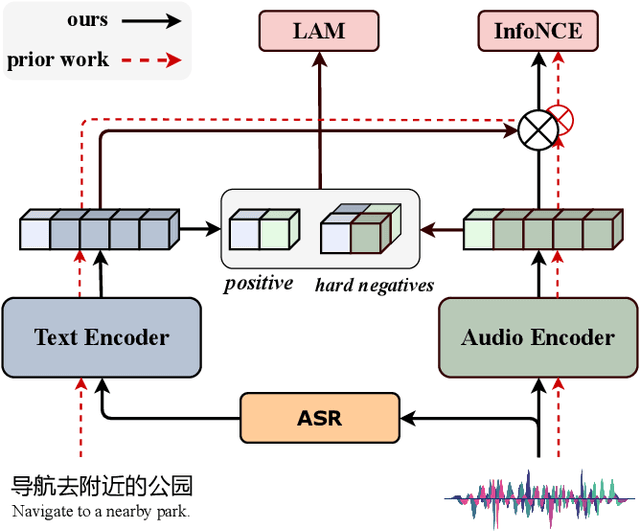
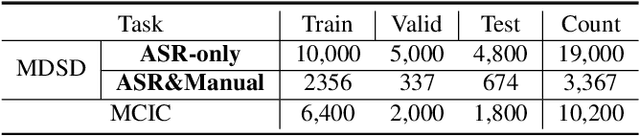
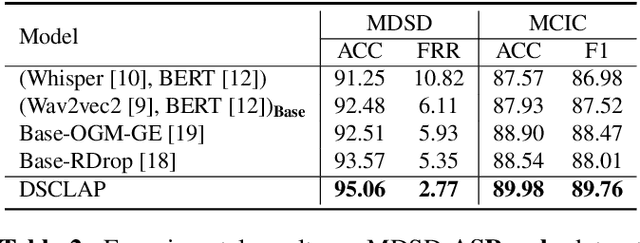
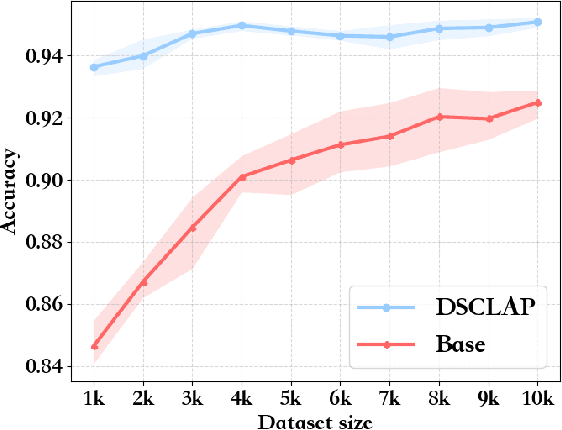
Analyzing real-world multimodal signals is an essential and challenging task for intelligent voice assistants (IVAs). Mainstream approaches have achieved remarkable performance on various downstream tasks of IVAs with pre-trained audio models and text models. However, these models are pre-trained independently and usually on tasks different from target domains, resulting in sub-optimal modality representations for downstream tasks. Moreover, in many domains, collecting enough language-audio pairs is extremely hard, and transcribing raw audio also requires high professional skills, making it difficult or even infeasible to joint pre-training. To address these painpoints, we propose DSCLAP, a simple and effective framework that enables language-audio pre-training with only raw audio signal input. Specifically, DSCLAP converts raw audio signals into text via an ASR system and combines a contrastive learning objective and a language-audio matching objective to align the audio and ASR transcriptions. We pre-train DSCLAP on 12,107 hours of in-vehicle domain audio. Empirical results on two downstream tasks show that while conceptually simple, DSCLAP significantly outperforms the baseline models in all metrics, showing great promise for domain-specific IVAs applications.