 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOV-Uni3DETR: Towards Unified Open-Vocabulary 3D Object Detection via Cycle-Modality Propagation
Mar 28, 2024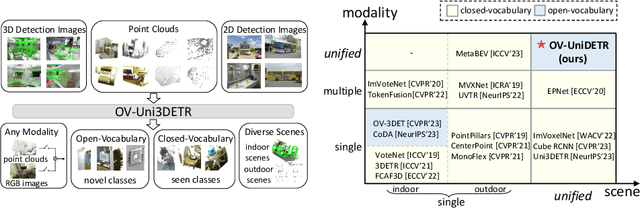
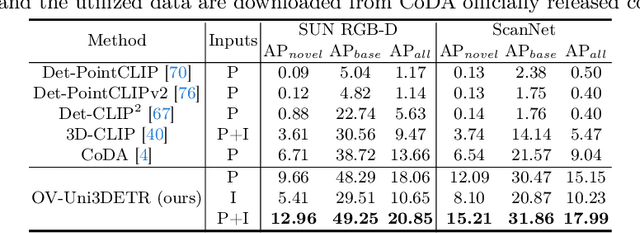
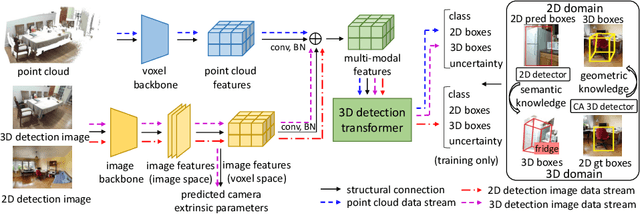
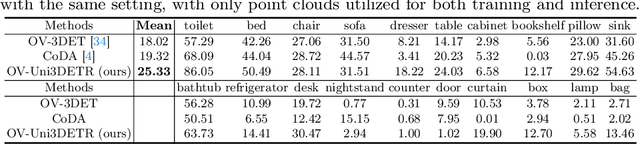
In the current state of 3D object detection research, the severe scarcity of annotated 3D data, substantial disparities across different data modalities, and the absence of a unified architecture, have impeded the progress towards the goal of universality. In this paper, we propose \textbf{OV-Uni3DETR}, a unified open-vocabulary 3D detector via cycle-modality propagation. Compared with existing 3D detectors, OV-Uni3DETR offers distinct advantages: 1) Open-vocabulary 3D detection: During training, it leverages various accessible data, especially extensive 2D detection images, to boost training diversity. During inference, it can detect both seen and unseen classes. 2) Modality unifying: It seamlessly accommodates input data from any given modality, effectively addressing scenarios involving disparate modalities or missing sensor information, thereby supporting test-time modality switching. 3) Scene unifying: It provides a unified multi-modal model architecture for diverse scenes collected by distinct sensors. Specifically, we propose the cycle-modality propagation, aimed at propagating knowledge bridging 2D and 3D modalities, to support the aforementioned functionalities. 2D semantic knowledge from large-vocabulary learning guides novel class discovery in the 3D domain, and 3D geometric knowledge provides localization supervision for 2D detection images. OV-Uni3DETR achieves the state-of-the-art performance on various scenarios, surpassing existing methods by more than 6\% on average. Its performance using only RGB images is on par with or even surpasses that of previous point cloud based methods. Code and pre-trained models will be released later.
Uncertainty-aware Consistency Learning for Cold-Start Item Recommendation
Aug 07, 2023Graph Neural Network (GNN)-based models have become the mainstream approach for recommender systems. Despite the effectiveness, they are still suffering from the cold-start problem, i.e., recommend for few-interaction items. Existing GNN-based recommendation models to address the cold-start problem mainly focus on utilizing auxiliary features of users and items, leaving the user-item interactions under-utilized. However, embeddings distributions of cold and warm items are still largely different, since cold items' embeddings are learned from lower-popularity interactions, while warm items' embeddings are from higher-popularity interactions. Thus, there is a seesaw phenomenon, where the recommendation performance for the cold and warm items cannot be improved simultaneously. To this end, we proposed a Uncertainty-aware Consistency learning framework for Cold-start item recommendation (shorten as UCC) solely based on user-item interactions. Under this framework, we train the teacher model (generator) and student model (recommender) with consistency learning, to ensure the cold items with additionally generated low-uncertainty interactions can have similar distribution with the warm items. Therefore, the proposed framework improves the recommendation of cold and warm items at the same time, without hurting any one of them. Extensive experiments on benchmark datasets demonstrate that our proposed method significantly outperforms state-of-the-art methods on both warm and cold items, with an average performance improvement of 27.6%.