 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResMAS: Resilience Optimization in LLM-based Multi-agent Systems
Jan 08, 2026Large Language Model-based Multi-Agent Systems (LLM-based MAS), where multiple LLM agents collaborate to solve complex tasks, have shown impressive performance in many areas. However, MAS are typically distributed across different devices or environments, making them vulnerable to perturbations such as agent failures. While existing works have studied the adversarial attacks and corresponding defense strategies, they mainly focus on reactively detecting and mitigating attacks after they occur rather than proactively designing inherently resilient systems. In this work, we study the resilience of LLM-based MAS under perturbations and find that both the communication topology and prompt design significantly influence system resilience. Motivated by these findings, we propose ResMAS: a two-stage framework for enhancing MAS resilience. First, we train a reward model to predict the MAS's resilience, based on which we train a topology generator to automatically design resilient topology for specific tasks through reinforcement learning. Second, we introduce a topology-aware prompt optimization method that refines each agent's prompt based on its connections and interactions with other agents. Extensive experiments across a range of tasks show that our approach substantially improves MAS resilience under various constraints. Moreover, our framework demonstrates strong generalization ability to new tasks and models, highlighting its potential for building resilient MASs.
UrbanPlanBench: A Comprehensive Urban Planning Benchmark for Evaluating Large Language Models
Apr 23, 2025
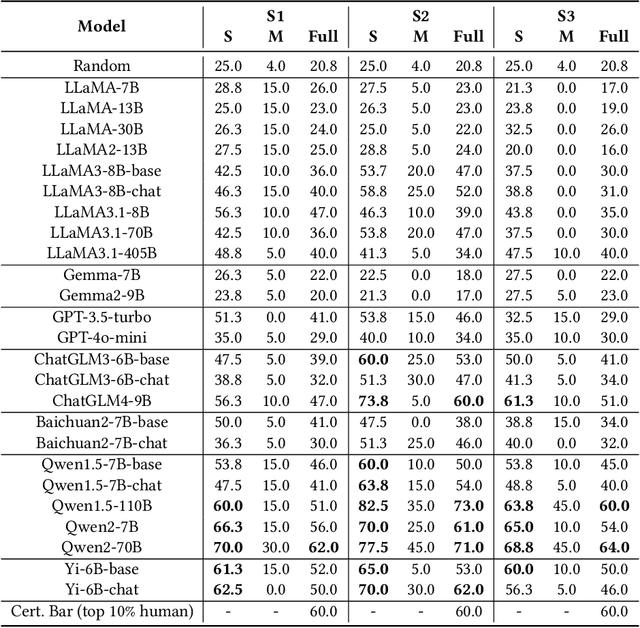


The advent of Large Language Models (LLMs) holds promise for revolutionizing various fields traditionally dominated by human expertise. Urban planning, a professional discipline that fundamentally shapes our daily surroundings, is one such field heavily relying on multifaceted domain knowledge and experience of human experts. The extent to which LLMs can assist human practitioners in urban planning remains largely unexplored. In this paper, we introduce a comprehensive benchmark, UrbanPlanBench, tailored to evaluate the efficacy of LLMs in urban planning, which encompasses fundamental principles, professional knowledge, and management and regulations, aligning closely with the qualifications expected of human planners. Through extensive evaluation, we reveal a significant imbalance in the acquisition of planning knowledge among LLMs, with even the most proficient models falling short of meeting professional standards. For instance, we observe that 70% of LLMs achieve subpar performance in understanding planning regulations compared to other aspects. Besides the benchmark, we present the largest-ever supervised fine-tuning (SFT) dataset, UrbanPlanText, comprising over 30,000 instruction pairs sourced from urban planning exams and textbooks. Our findings demonstrate that fine-tuned models exhibit enhanced performance in memorization tests and comprehension of urban planning knowledge, while there exists significant room for improvement, particularly in tasks requiring domain-specific terminology and reasoning. By making our benchmark, dataset, and associated evaluation and fine-tuning toolsets publicly available at https://github.com/tsinghua-fib-lab/PlanBench, we aim to catalyze the integration of LLMs into practical urban planning, fostering a symbiotic collaboration between human expertise and machine intelligence.
A Foundation Model for Unified Urban Spatio-Temporal Flow Prediction
Nov 20, 2024
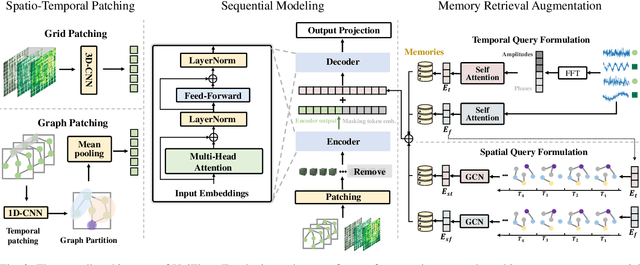


Urban spatio-temporal flow prediction, encompassing traffic flows and crowd flows, is crucial for optimizing city infrastructure and managing traffic and emergency responses. Traditional approaches have relied on separate models tailored to either grid-based data, representing cities as uniform cells, or graph-based data, modeling cities as networks of nodes and edges. In this paper, we build UniFlow, a foundational model for general urban flow prediction that unifies both grid-based and graphbased data. We first design a multi-view spatio-temporal patching mechanism to standardize different data into a consistent sequential format and then introduce a spatio-temporal transformer architecture to capture complex correlations and dynamics. To leverage shared spatio-temporal patterns across different data types and facilitate effective cross-learning, we propose SpatioTemporal Memory Retrieval Augmentation (ST-MRA). By creating structured memory modules to store shared spatio-temporal patterns, ST-MRA enhances predictions through adaptive memory retrieval. Extensive experiments demonstrate that UniFlow outperforms existing models in both grid-based and graph-based flow prediction, excelling particularly in scenarios with limited data availability, showcasing its superior performance and broad applicability. The datasets and code implementation have been released on https://github.com/YuanYuan98/UniFlow.
UrbanDiT: A Foundation Model for Open-World Urban Spatio-Temporal Learning
Nov 19, 2024The urban environment is characterized by complex spatio-temporal dynamics arising from diverse human activities and interactions. Effectively modeling these dynamics is essential for understanding and optimizing urban systems In this work, we introduce UrbanDiT, a foundation model for open-world urban spatio-temporal learning that successfully scale up diffusion transformers in this field. UrbanDiT pioneers a unified model that integrates diverse spatio-temporal data sources and types while learning universal spatio-temporal patterns across different cities and scenarios. This allows the model to unify both multi-data and multi-task learning, and effectively support a wide range of spatio-temporal applications. Its key innovation lies in the elaborated prompt learning framework, which adaptively generates both data-driven and task-specific prompts, guiding the model to deliver superior performance across various urban applications. UrbanDiT offers three primary advantages: 1) It unifies diverse data types, such as grid-based and graph-based data, into a sequential format, allowing to capture spatio-temporal dynamics across diverse scenarios of different cities; 2) With masking strategies and task-specific prompts, it supports a wide range of tasks, including bi-directional spatio-temporal prediction, temporal interpolation, spatial extrapolation, and spatio-temporal imputation; and 3) It generalizes effectively to open-world scenarios, with its powerful zero-shot capabilities outperforming nearly all baselines with training data. These features allow UrbanDiT to achieves state-of-the-art performance in different domains such as transportation traffic, crowd flows, taxi demand, bike usage, and cellular traffic, across multiple cities and tasks. UrbanDiT sets up a new benchmark for foundation models in the urban spatio-temporal domain.
Enhancing ID-based Recommendation with Large Language Models
Nov 04, 2024Large Language Models (LLMs) have recently garnered significant attention in various domains, including recommendation systems. Recent research leverages the capabilities of LLMs to improve the performance and user modeling aspects of recommender systems. These studies primarily focus on utilizing LLMs to interpret textual data in recommendation tasks. However, it's worth noting that in ID-based recommendations, textual data is absent, and only ID data is available. The untapped potential of LLMs for ID data within the ID-based recommendation paradigm remains relatively unexplored. To this end, we introduce a pioneering approach called "LLM for ID-based Recommendation" (LLM4IDRec). This innovative approach integrates the capabilities of LLMs while exclusively relying on ID data, thus diverging from the previous reliance on textual data. The basic idea of LLM4IDRec is that by employing LLM to augment ID data, if augmented ID data can improve recommendation performance, it demonstrates the ability of LLM to interpret ID data effectively, exploring an innovative way for the integration of LLM in ID-based recommendation. We evaluate the effectiveness of our LLM4IDRec approach using three widely-used datasets. Our results demonstrate a notable improvement in recommendation performance, with our approach consistently outperforming existing methods in ID-based recommendation by solely augmenting input data.
Synergizing LLM Agents and Knowledge Graph for Socioeconomic Prediction in LBSN
Oct 29, 2024



The fast development of location-based social networks (LBSNs) has led to significant changes in society, resulting in popular studies of using LBSN data for socioeconomic prediction, e.g., regional population and commercial activity estimation. Existing studies design various graphs to model heterogeneous LBSN data, and further apply graph representation learning methods for socioeconomic prediction. However, these approaches heavily rely on heuristic ideas and expertise to extract task-relevant knowledge from diverse data, which may not be optimal for specific tasks. Additionally, they tend to overlook the inherent relationships between different indicators, limiting the prediction accuracy. Motivated by the remarkable abilities of large language models (LLMs) in commonsense reasoning, embedding, and multi-agent collaboration, in this work, we synergize LLM agents and knowledge graph for socioeconomic prediction. We first construct a location-based knowledge graph (LBKG) to integrate multi-sourced LBSN data. Then we leverage the reasoning power of LLM agent to identify relevant meta-paths in the LBKG for each type of socioeconomic prediction task, and design a semantic-guided attention module for knowledge fusion with meta-paths. Moreover, we introduce a cross-task communication mechanism to further enhance performance by enabling knowledge sharing across tasks at both LLM agent and KG levels. On the one hand, the LLM agents for different tasks collaborate to generate more diverse and comprehensive meta-paths. On the other hand, the embeddings from different tasks are adaptively merged for better socioeconomic prediction. Experiments on two datasets demonstrate the effectiveness of the synergistic design between LLM and KG, providing insights for information sharing across socioeconomic prediction tasks.
Large-scale Urban Facility Location Selection with Knowledge-informed Reinforcement Learning
Sep 03, 2024
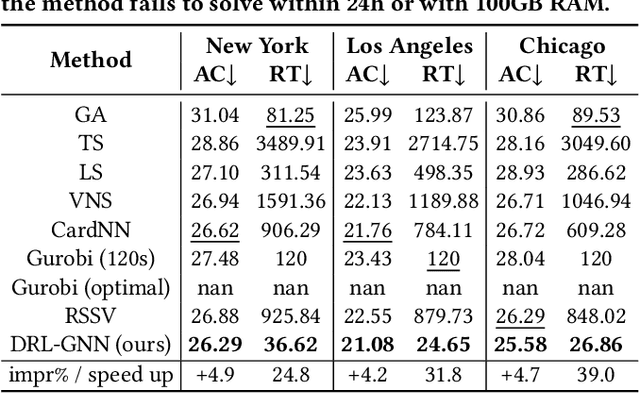


The facility location problem (FLP) is a classical combinatorial optimization challenge aimed at strategically laying out facilities to maximize their accessibility. In this paper, we propose a reinforcement learning method tailored to solve large-scale urban FLP, capable of producing near-optimal solutions at superfast inference speed. We distill the essential swap operation from local search, and simulate it by intelligently selecting edges on a graph of urban regions, guided by a knowledge-informed graph neural network, thus sidestepping the need for heavy computation of local search. Extensive experiments on four US cities with different geospatial conditions demonstrate that our approach can achieve comparable performance to commercial solvers with less than 5\% accessibility loss, while displaying up to 1000 times speedup. We deploy our model as an online geospatial application at https://huggingface.co/spaces/randommmm/MFLP.
PateGail: A Privacy-Preserving Mobility Trajectory Generator with Imitation Learning
Jul 23, 2024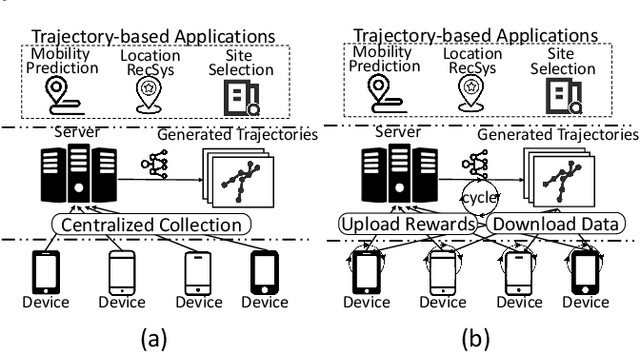
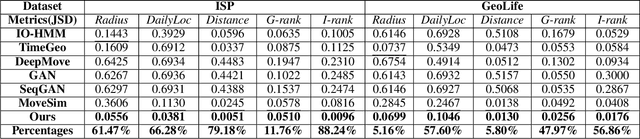
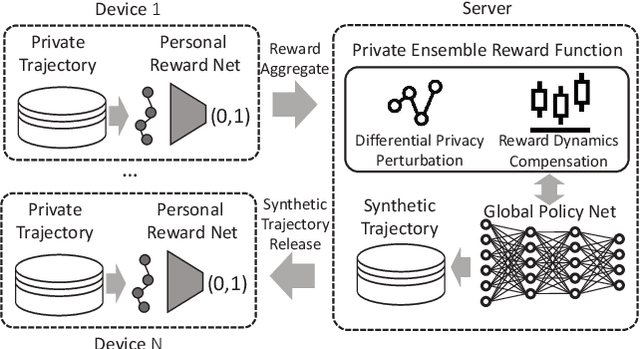
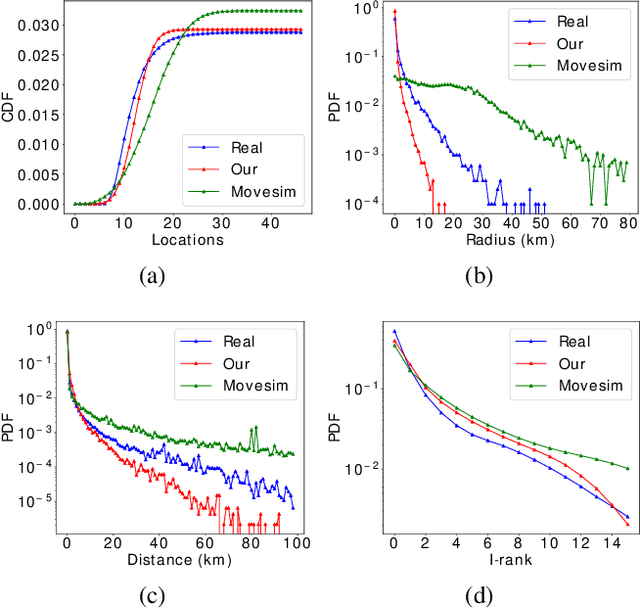
Generating human mobility trajectories is of great importance to solve the lack of large-scale trajectory data in numerous applications, which is caused by privacy concerns. However, existing mobility trajectory generation methods still require real-world human trajectories centrally collected as the training data, where there exists an inescapable risk of privacy leakage. To overcome this limitation, in this paper, we propose PateGail, a privacy-preserving imitation learning model to generate mobility trajectories, which utilizes the powerful generative adversary imitation learning model to simulate the decision-making process of humans. Further, in order to protect user privacy, we train this model collectively based on decentralized mobility data stored in user devices, where personal discriminators are trained locally to distinguish and reward the real and generated human trajectories. In the training process, only the generated trajectories and their rewards obtained based on personal discriminators are shared between the server and devices, whose privacy is further preserved by our proposed perturbation mechanisms with theoretical proof to satisfy differential privacy. Further, to better model the human decision-making process, we propose a novel aggregation mechanism of the rewards obtained from personal discriminators. We theoretically prove that under the reward obtained based on the aggregation mechanism, our proposed model maximizes the lower bound of the discounted total rewards of users. Extensive experiments show that the trajectories generated by our model are able to resemble real-world trajectories in terms of five key statistical metrics, outperforming state-of-the-art algorithms by over 48.03%. Furthermore, we demonstrate that the synthetic trajectories are able to efficiently support practical applications, including mobility prediction and location recommendation.
A GPU-accelerated Large-scale Simulator for Transportation System Optimization Benchmarking
Jun 15, 2024With the development of artificial intelligence techniques, transportation system optimization is evolving from traditional methods relying on expert experience to simulation and learning-based decision optimization methods. Learning-based optimization methods require extensive interaction with highly realistic microscopic traffic simulators for optimization. However, existing microscopic traffic simulators are computationally inefficient in large-scale scenarios and therefore significantly reduce the efficiency of the data sampling process of optimization algorithms. In addition, the optimization scenarios supported by existing simulators are limited, mainly focusing on the traffic signal control. To address these challenges and limitations, we propose the first open-source GPU-accelerated large-scale microscopic simulator for transportation system simulation. The simulator is able to iterate at 84.09Hz, which achieves 88.92 times computational acceleration in the large-scale scenario with more than a million vehicles compared to the best baseline. Based on the simulator, we implement a set of microscopic and macroscopic controllable objects and metrics to support most typical transportation system optimization scenarios. These controllable objects and metrics are all provided by Python API for ease of use. We choose five important and representative transportation system optimization scenarios and benchmark classical rule-based algorithms, reinforcement learning, and black-box optimization in four cities. The codes are available at \url{https://github.com/tsinghua-fib-lab/moss-benchmark} with the MIT License.
Large Language Model for Participatory Urban Planning
Feb 27, 2024



Participatory urban planning is the mainstream of modern urban planning that involves the active engagement of residents. However, the traditional participatory paradigm requires experienced planning experts and is often time-consuming and costly. Fortunately, the emerging Large Language Models (LLMs) have shown considerable ability to simulate human-like agents, which can be used to emulate the participatory process easily. In this work, we introduce an LLM-based multi-agent collaboration framework for participatory urban planning, which can generate land-use plans for urban regions considering the diverse needs of residents. Specifically, we construct LLM agents to simulate a planner and thousands of residents with diverse profiles and backgrounds. We first ask the planner to carry out an initial land-use plan. To deal with the different facilities needs of residents, we initiate a discussion among the residents in each community about the plan, where residents provide feedback based on their profiles. Furthermore, to improve the efficiency of discussion, we adopt a fishbowl discussion mechanism, where part of the residents discuss and the rest of them act as listeners in each round. Finally, we let the planner modify the plan based on residents' feedback. We deploy our method on two real-world regions in Beijing. Experiments show that our method achieves state-of-the-art performance in residents satisfaction and inclusion metrics, and also outperforms human experts in terms of service accessibility and ecology metrics.