 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOME: Learning Human-Object Manipulation with Action-Conditioned Egocentric World Model
Mar 28, 2026Learning human-object manipulation presents significant challenges due to its fine-grained and contact-rich nature of the motions involved. Traditional physics-based animation requires extensive modeling and manual setup, and more importantly, it neither generalizes well across diverse object morphologies nor scales effectively to real-world environment. To address these limitations, we introduce LOME, an egocentric world model that can generate realistic human-object interactions as videos conditioned on an input image, a text prompt, and per-frame human actions, including both body poses and hand gestures. LOME injects strong and precise action guidance into object manipulation by jointly estimating spatial human actions and the environment contexts during training. After finetuning a pretrained video generative model on videos of diverse egocentric human-object interactions, LOME demonstrates not only high action-following accuracy and strong generalization to unseen scenarios, but also realistic physical consequences of hand-object interactions, e.g., liquid flowing from a bottle into a mug after executing a ``pouring'' action. Extensive experiments demonstrate that our video-based framework significantly outperforms state-of-the-art image based and video-based action-conditioned methods and Image/Text-to-Video (I/T2V) generative model in terms of both temporal consistency and motion control. LOME paves the way for photorealistic AR/VR experiences and scalable robotic training, without being limited to simulated environments or relying on explicit 3D/4D modeling.
Fast SAM 3D Body: Accelerating SAM 3D Body for Real-Time Full-Body Human Mesh Recovery
Mar 16, 2026SAM 3D Body (3DB) achieves state-of-the-art accuracy in monocular 3D human mesh recovery, yet its inference latency of several seconds per image precludes real-time application. We present Fast SAM 3D Body, a training-free acceleration framework that reformulates the 3DB inference pathway to achieve interactive rates. By decoupling serial spatial dependencies and applying architecture-aware pruning, we enable parallelized multi-crop feature extraction and streamlined transformer decoding. Moreover, to extract the joint-level kinematics (SMPL) compatible with existing humanoid control and policy learning frameworks, we replace the iterative mesh fitting with a direct feedforward mapping, accelerating this specific conversion by over 10,000x. Overall, our framework delivers up to a 10.9x end-to-end speedup while maintaining on-par reconstruction fidelity, even surpassing 3DB on benchmarks such as LSPET. We demonstrate its utility by deploying Fast SAM 3D Body in a vision-only teleoperation system that-unlike methods reliant on wearable IMUs-enables real-time humanoid control and the direct collection of manipulation policies from a single RGB stream.
MiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling
Feb 12, 2026The evolution of large language models (LLMs) towards applications with ultra-long contexts faces challenges posed by the high computational and memory costs of the Transformer architecture. While existing sparse and linear attention mechanisms attempt to mitigate these issues, they typically involve a trade-off between memory efficiency and model performance. This paper introduces MiniCPM-SALA, a 9B-parameter hybrid architecture that integrates the high-fidelity long-context modeling of sparse attention (InfLLM-V2) with the global efficiency of linear attention (Lightning Attention). By employing a layer selection algorithm to integrate these mechanisms in a 1:3 ratio and utilizing a hybrid positional encoding (HyPE), the model maintains efficiency and performance for long-context tasks. Furthermore, we introduce a cost-effective continual training framework that transforms pre-trained Transformer-based models into hybrid models, which reduces training costs by approximately 75% compared to training from scratch. Extensive experiments show that MiniCPM-SALA maintains general capabilities comparable to full-attention models while offering improved efficiency. On a single NVIDIA A6000D GPU, the model achieves up to 3.5x the inference speed of the full-attention model at the sequence length of 256K tokens and supports context lengths of up to 1M tokens, a scale where traditional full-attention 8B models fail because of memory constraints.
Towards Efficient and Effective Multi-Camera Encoding for End-to-End Driving
Dec 12, 2025We present Flex, an efficient and effective scene encoder that addresses the computational bottleneck of processing high-volume multi-camera data in end-to-end autonomous driving. Flex employs a small set of learnable scene tokens to jointly encode information from all image tokens across different cameras and timesteps. By design, our approach is geometry-agnostic, learning a compact scene representation directly from data without relying on the explicit 3D inductive biases, such as Bird-Eye-View (BEV), occupancy or tri-plane representations, which are common in prior work. This holistic encoding strategy aggressively compresses the visual input for the downstream Large Language Model (LLM) based policy model. Evaluated on a large-scale proprietary dataset of 20,000 driving hours, our Flex achieves 2.2x greater inference throughput while improving driving performance by a large margin compared to state-of-the-art methods. Furthermore, we show that these compact scene tokens develop an emergent capability for scene decomposition without any explicit supervision. Our findings challenge the prevailing assumption that 3D priors are necessary, demonstrating that a data-driven, joint encoding strategy offers a more scalable, efficient and effective path for future autonomous driving systems.
Occupancy Learning with Spatiotemporal Memory
Aug 06, 20253D occupancy becomes a promising perception representation for autonomous driving to model the surrounding environment at a fine-grained scale. However, it remains challenging to efficiently aggregate 3D occupancy over time across multiple input frames due to the high processing cost and the uncertainty and dynamics of voxels. To address this issue, we propose ST-Occ, a scene-level occupancy representation learning framework that effectively learns the spatiotemporal feature with temporal consistency. ST-Occ consists of two core designs: a spatiotemporal memory that captures comprehensive historical information and stores it efficiently through a scene-level representation and a memory attention that conditions the current occupancy representation on the spatiotemporal memory with a model of uncertainty and dynamic awareness. Our method significantly enhances the spatiotemporal representation learned for 3D occupancy prediction tasks by exploiting the temporal dependency between multi-frame inputs. Experiments show that our approach outperforms the state-of-the-art methods by a margin of 3 mIoU and reduces the temporal inconsistency by 29%.
BEVCon: Advancing Bird's Eye View Perception with Contrastive Learning
Aug 06, 2025We present BEVCon, a simple yet effective contrastive learning framework designed to improve Bird's Eye View (BEV) perception in autonomous driving. BEV perception offers a top-down-view representation of the surrounding environment, making it crucial for 3D object detection, segmentation, and trajectory prediction tasks. While prior work has primarily focused on enhancing BEV encoders and task-specific heads, we address the underexplored potential of representation learning in BEV models. BEVCon introduces two contrastive learning modules: an instance feature contrast module for refining BEV features and a perspective view contrast module that enhances the image backbone. The dense contrastive learning designed on top of detection losses leads to improved feature representations across both the BEV encoder and the backbone. Extensive experiments on the nuScenes dataset demonstrate that BEVCon achieves consistent performance gains, achieving up to +2.4% mAP improvement over state-of-the-art baselines. Our results highlight the critical role of representation learning in BEV perception and offer a complementary avenue to conventional task-specific optimizations.
MemOS: An Operating System for Memory-Augmented Generation (MAG) in Large Language Models
May 28, 2025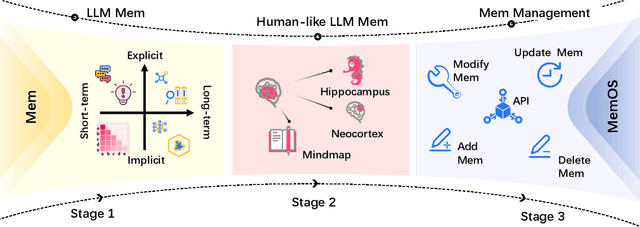
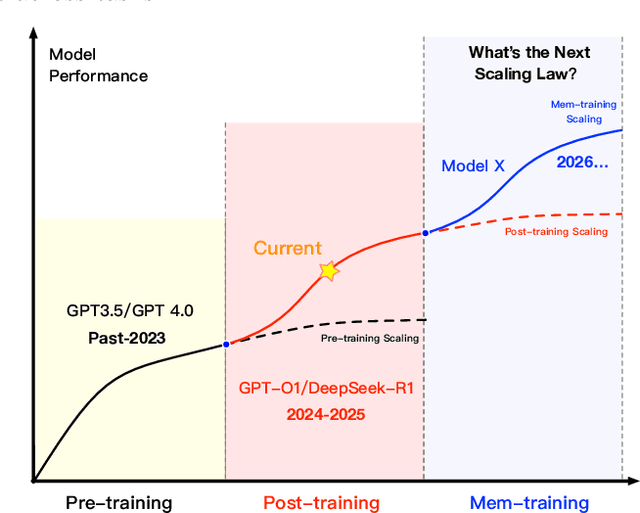
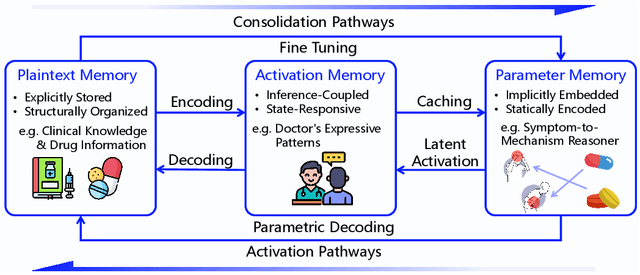
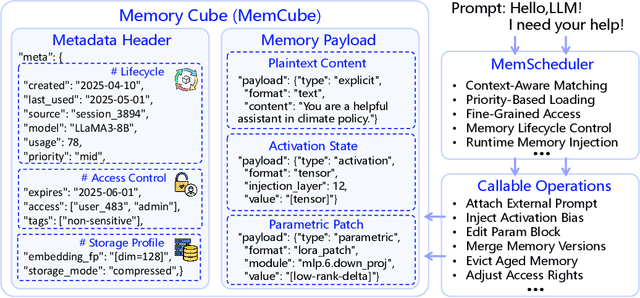
Large Language Models (LLMs) have emerged as foundational infrastructure in the pursuit of Artificial General Intelligence (AGI). Despite their remarkable capabilities in language perception and generation, current LLMs fundamentally lack a unified and structured architecture for handling memory. They primarily rely on parametric memory (knowledge encoded in model weights) and ephemeral activation memory (context-limited runtime states). While emerging methods like Retrieval-Augmented Generation (RAG) incorporate plaintext memory, they lack lifecycle management and multi-modal integration, limiting their capacity for long-term knowledge evolution. To address this, we introduce MemOS, a memory operating system designed for LLMs that, for the first time, elevates memory to a first-class operational resource. It builds unified mechanisms for representation, organization, and governance across three core memory types: parametric, activation, and plaintext. At its core is the MemCube, a standardized memory abstraction that enables tracking, fusion, and migration of heterogeneous memory, while offering structured, traceable access across tasks and contexts. MemOS establishes a memory-centric execution framework with strong controllability, adaptability, and evolvability. It fills a critical gap in current LLM infrastructure and lays the groundwork for continual adaptation, personalized intelligence, and cross-platform coordination in next-generation intelligent systems.
SEAP: Training-free Sparse Expert Activation Pruning Unlock the Brainpower of Large Language Models
Mar 10, 2025



Large Language Models have achieved remarkable success across various natural language processing tasks, yet their high computational cost during inference remains a major bottleneck. This paper introduces Sparse Expert Activation Pruning (SEAP), a training-free pruning method that selectively retains task-relevant parameters to reduce inference overhead. Inspired by the clustering patterns of hidden states and activations in LLMs, SEAP identifies task-specific expert activation patterns and prunes the model while preserving task performance and enhancing computational efficiency. Experimental results demonstrate that SEAP significantly reduces computational overhead while maintaining competitive accuracy. Notably, at 50% pruning, SEAP surpasses both WandA and FLAP by over 20%, and at 20% pruning, it incurs only a 2.2% performance drop compared to the dense model. These findings highlight SEAP's scalability and effectiveness, making it a promising approach for optimizing large-scale LLMs.
SampleMix: A Sample-wise Pre-training Data Mixing Strategey by Coordinating Data Quality and Diversity
Mar 03, 2025Existing pretraining data mixing methods for large language models (LLMs) typically follow a domain-wise methodology, a top-down process that first determines domain weights and then performs uniform data sampling across each domain. However, these approaches neglect significant inter-domain overlaps and commonalities, failing to control the global diversity of the constructed training dataset. Further, uniform sampling within domains ignores fine-grained sample-specific features, potentially leading to suboptimal data distribution. To address these shortcomings, we propose a novel sample-wise data mixture approach based on a bottom-up paradigm. This method performs global cross-domain sampling by systematically evaluating the quality and diversity of each sample, thereby dynamically determining the optimal domain distribution. Comprehensive experiments across multiple downstream tasks and perplexity assessments demonstrate that SampleMix surpasses existing domain-based methods. Meanwhile, SampleMix requires 1.4x to 2.1x training steps to achieves the baselines' performance, highlighting the substantial potential of SampleMix to optimize pre-training data.
SurveyX: Academic Survey Automation via Large Language Models
Feb 20, 2025Large Language Models (LLMs) have demonstrated exceptional comprehension capabilities and a vast knowledge base, suggesting that LLMs can serve as efficient tools for automated survey generation. However, recent research related to automated survey generation remains constrained by some critical limitations like finite context window, lack of in-depth content discussion, and absence of systematic evaluation frameworks. Inspired by human writing processes, we propose SurveyX, an efficient and organized system for automated survey generation that decomposes the survey composing process into two phases: the Preparation and Generation phases. By innovatively introducing online reference retrieval, a pre-processing method called AttributeTree, and a re-polishing process, SurveyX significantly enhances the efficacy of survey composition. Experimental evaluation results show that SurveyX outperforms existing automated survey generation systems in content quality (0.259 improvement) and citation quality (1.76 enhancement), approaching human expert performance across multiple evaluation dimensions. Examples of surveys generated by SurveyX are available on www.surveyx.cn