 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual VLA: Self-Reflective Vision-Language-Action Model with Adaptive Reasoning
Dec 30, 2025Recent reasoning-augmented Vision-Language-Action (VLA) models have improved the interpretability of end-to-end autonomous driving by generating intermediate reasoning traces. Yet these models primarily describe what they perceive and intend to do, rarely questioning whether their planned actions are safe or appropriate. This work introduces Counterfactual VLA (CF-VLA), a self-reflective VLA framework that enables the model to reason about and revise its planned actions before execution. CF-VLA first generates time-segmented meta-actions that summarize driving intent, and then performs counterfactual reasoning conditioned on both the meta-actions and the visual context. This step simulates potential outcomes, identifies unsafe behaviors, and outputs corrected meta-actions that guide the final trajectory generation. To efficiently obtain such self-reflective capabilities, we propose a rollout-filter-label pipeline that mines high-value scenes from a base (non-counterfactual) VLA's rollouts and labels counterfactual reasoning traces for subsequent training rounds. Experiments on large-scale driving datasets show that CF-VLA improves trajectory accuracy by up to 17.6%, enhances safety metrics by 20.5%, and exhibits adaptive thinking: it only enables counterfactual reasoning in challenging scenarios. By transforming reasoning traces from one-shot descriptions to causal self-correction signals, CF-VLA takes a step toward self-reflective autonomous driving agents that learn to think before they act.
Safety Evaluation of Motion Plans Using Trajectory Predictors as Forward Reachable Set Estimators
Jul 30, 2025

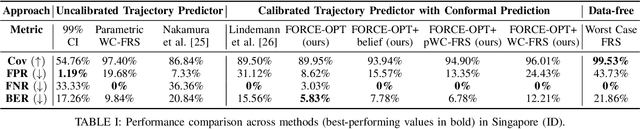

The advent of end-to-end autonomy stacks - often lacking interpretable intermediate modules - has placed an increased burden on ensuring that the final output, i.e., the motion plan, is safe in order to validate the safety of the entire stack. This requires a safety monitor that is both complete (able to detect all unsafe plans) and sound (does not flag safe plans). In this work, we propose a principled safety monitor that leverages modern multi-modal trajectory predictors to approximate forward reachable sets (FRS) of surrounding agents. By formulating a convex program, we efficiently extract these data-driven FRSs directly from the predicted state distributions, conditioned on scene context such as lane topology and agent history. To ensure completeness, we leverage conformal prediction to calibrate the FRS and guarantee coverage of ground-truth trajectories with high probability. To preserve soundness in out-of-distribution (OOD) scenarios or under predictor failure, we introduce a Bayesian filter that dynamically adjusts the FRS conservativeness based on the predictor's observed performance. We then assess the safety of the ego vehicle's motion plan by checking for intersections with these calibrated FRSs, ensuring the plan remains collision-free under plausible future behaviors of others. Extensive experiments on the nuScenes dataset show our approach significantly improves soundness while maintaining completeness, offering a practical and reliable safety monitor for learned autonomy stacks.
Leveraging Correlation Across Test Platforms for Variance-Reduced Metric Estimation
Jun 25, 2025



Learning-based robotic systems demand rigorous validation to assure reliable performance, but extensive real-world testing is often prohibitively expensive, and if conducted may still yield insufficient data for high-confidence guarantees. In this work, we introduce a general estimation framework that leverages paired data across test platforms, e.g., paired simulation and real-world observations, to achieve better estimates of real-world metrics via the method of control variates. By incorporating cheap and abundant auxiliary measurements (for example, simulator outputs) as control variates for costly real-world samples, our method provably reduces the variance of Monte Carlo estimates and thus requires significantly fewer real-world samples to attain a specified confidence bound on the mean performance. We provide theoretical analysis characterizing the variance and sample-efficiency improvement, and demonstrate empirically in autonomous driving and quadruped robotics settings that our approach achieves high-probability bounds with markedly improved sample efficiency. Our technique can lower the real-world testing burden for validating the performance of the stack, thereby enabling more efficient and cost-effective experimental evaluation of robotic systems.
Online Aggregation of Trajectory Predictors
Feb 11, 2025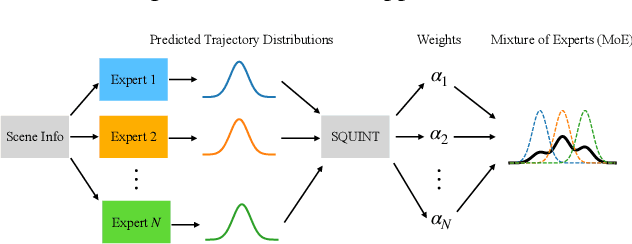
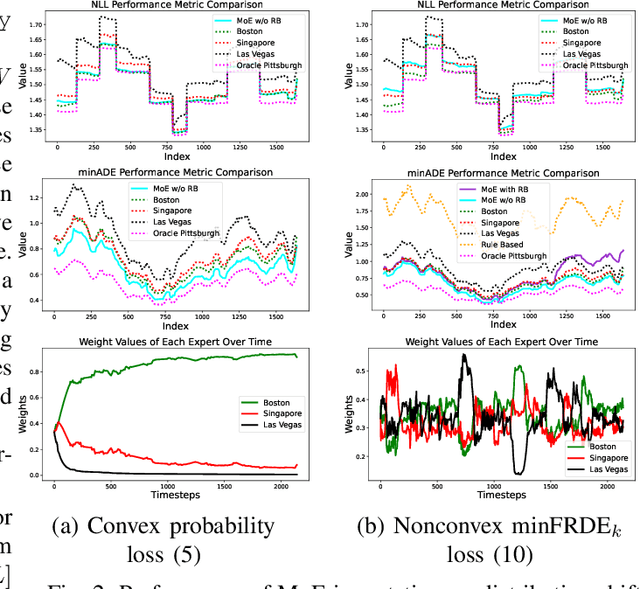
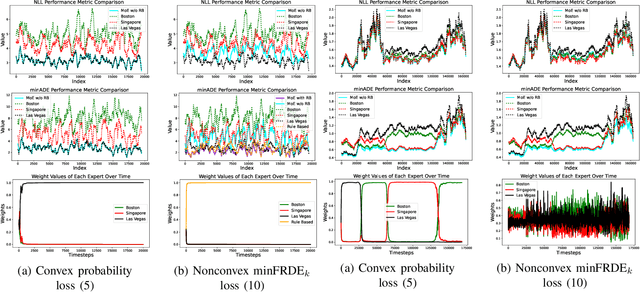
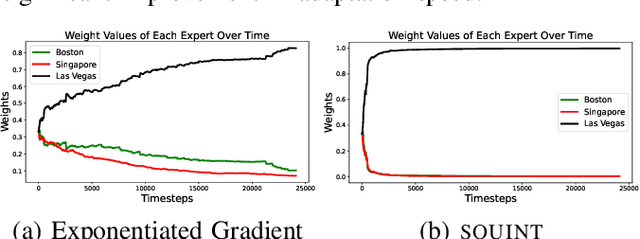
Trajectory prediction, the task of forecasting future agent behavior from past data, is central to safe and efficient autonomous driving. A diverse set of methods (e.g., rule-based or learned with different architectures and datasets) have been proposed, yet it is often the case that the performance of these methods is sensitive to the deployment environment (e.g., how well the design rules model the environment, or how accurately the test data match the training data). Building upon the principled theory of online convex optimization but also going beyond convexity and stationarity, we present a lightweight and model-agnostic method to aggregate different trajectory predictors online. We propose treating each individual trajectory predictor as an "expert" and maintaining a probability vector to mix the outputs of different experts. Then, the key technical approach lies in leveraging online data -the true agent behavior to be revealed at the next timestep- to form a convex-or-nonconvex, stationary-or-dynamic loss function whose gradient steers the probability vector towards choosing the best mixture of experts. We instantiate this method to aggregate trajectory predictors trained on different cities in the NUSCENES dataset and show that it performs just as well, if not better than, any singular model, even when deployed on the out-of-distribution LYFT dataset.
STORM: Spatio-Temporal Reconstruction Model for Large-Scale Outdoor Scenes
Dec 31, 2024



We present STORM, a spatio-temporal reconstruction model designed for reconstructing dynamic outdoor scenes from sparse observations. Existing dynamic reconstruction methods often rely on per-scene optimization, dense observations across space and time, and strong motion supervision, resulting in lengthy optimization times, limited generalization to novel views or scenes, and degenerated quality caused by noisy pseudo-labels for dynamics. To address these challenges, STORM leverages a data-driven Transformer architecture that directly infers dynamic 3D scene representations--parameterized by 3D Gaussians and their velocities--in a single forward pass. Our key design is to aggregate 3D Gaussians from all frames using self-supervised scene flows, transforming them to the target timestep to enable complete (i.e., "amodal") reconstructions from arbitrary viewpoints at any moment in time. As an emergent property, STORM automatically captures dynamic instances and generates high-quality masks using only reconstruction losses. Extensive experiments on public datasets show that STORM achieves precise dynamic scene reconstruction, surpassing state-of-the-art per-scene optimization methods (+4.3 to 6.6 PSNR) and existing feed-forward approaches (+2.1 to 4.7 PSNR) in dynamic regions. STORM reconstructs large-scale outdoor scenes in 200ms, supports real-time rendering, and outperforms competitors in scene flow estimation, improving 3D EPE by 0.422m and Acc5 by 28.02%. Beyond reconstruction, we showcase four additional applications of our model, illustrating the potential of self-supervised learning for broader dynamic scene understanding.
System-Level Safety Monitoring and Recovery for Perception Failures in Autonomous Vehicles
Sep 26, 2024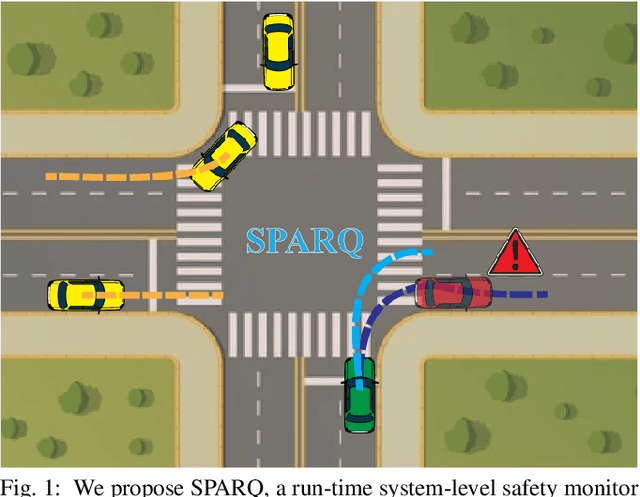
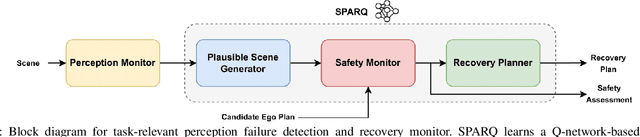
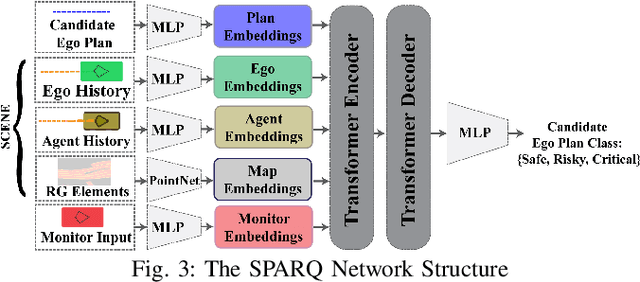
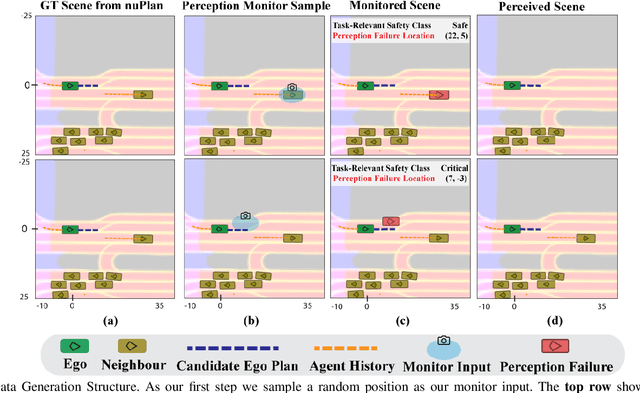
The safety-critical nature of autonomous vehicle (AV) operation necessitates development of task-relevant algorithms that can reason about safety at the system level and not just at the component level. To reason about the impact of a perception failure on the entire system performance, such task-relevant algorithms must contend with various challenges: complexity of AV stacks, high uncertainty in the operating environments, and the need for real-time performance. To overcome these challenges, in this work, we introduce a Q-network called SPARQ (abbreviation for Safety evaluation for Perception And Recovery Q-network) that evaluates the safety of a plan generated by a planning algorithm, accounting for perception failures that the planning process may have overlooked. This Q-network can be queried during system runtime to assess whether a proposed plan is safe for execution or poses potential safety risks. If a violation is detected, the network can then recommend a corrective plan while accounting for the perceptual failure. We validate our algorithm using the NuPlan-Vegas dataset, demonstrating its ability to handle cases where a perception failure compromises a proposed plan while the corrective plan remains safe. We observe an overall accuracy and recall of 90% while sustaining a frequency of 42Hz on the unseen testing dataset. We compare our performance to a popular reachability-based baseline and analyze some interesting properties of our approach in improving the safety properties of an AV pipeline.
RuleFuser: Injecting Rules in Evidential Networks for Robust Out-of-Distribution Trajectory Prediction
May 18, 2024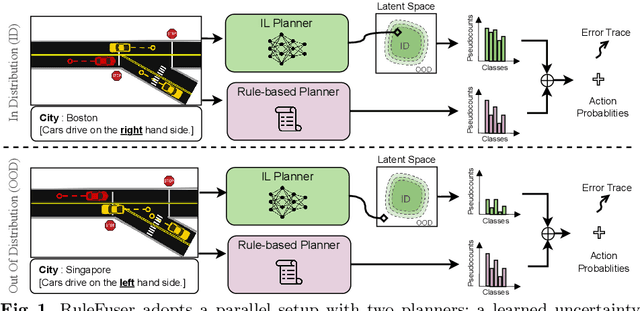

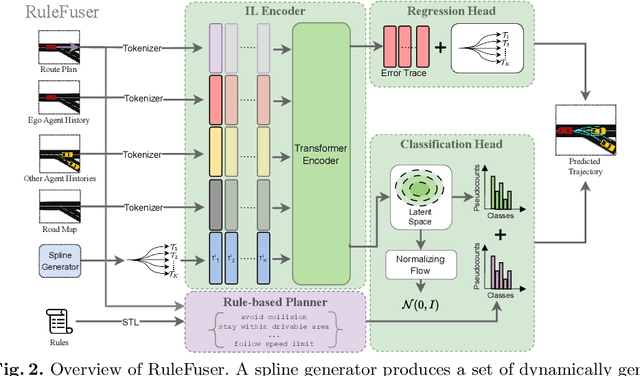

Modern neural trajectory predictors in autonomous driving are developed using imitation learning (IL) from driving logs. Although IL benefits from its ability to glean nuanced and multi-modal human driving behaviors from large datasets, the resulting predictors often struggle with out-of-distribution (OOD) scenarios and with traffic rule compliance. On the other hand, classical rule-based predictors, by design, can predict traffic rule satisfying behaviors while being robust to OOD scenarios, but these predictors fail to capture nuances in agent-to-agent interactions and human driver's intent. In this paper, we present RuleFuser, a posterior-net inspired evidential framework that combines neural predictors with classical rule-based predictors to draw on the complementary benefits of both, thereby striking a balance between performance and traffic rule compliance. The efficacy of our approach is demonstrated on the real-world nuPlan dataset where RuleFuser leverages the higher performance of the neural predictor in in-distribution (ID) scenarios and the higher safety offered by the rule-based predictor in OOD scenarios.
PAC-Bayes Generalization Certificates for Learned Inductive Conformal Prediction
Dec 07, 2023Inductive Conformal Prediction (ICP) provides a practical and effective approach for equipping deep learning models with uncertainty estimates in the form of set-valued predictions which are guaranteed to contain the ground truth with high probability. Despite the appeal of this coverage guarantee, these sets may not be efficient: the size and contents of the prediction sets are not directly controlled, and instead depend on the underlying model and choice of score function. To remedy this, recent work has proposed learning model and score function parameters using data to directly optimize the efficiency of the ICP prediction sets. While appealing, the generalization theory for such an approach is lacking: direct optimization of empirical efficiency may yield prediction sets that are either no longer efficient on test data, or no longer obtain the required coverage on test data. In this work, we use PAC-Bayes theory to obtain generalization bounds on both the coverage and the efficiency of set-valued predictors which can be directly optimized to maximize efficiency while satisfying a desired test coverage. In contrast to prior work, our framework allows us to utilize the entire calibration dataset to learn the parameters of the model and score function, instead of requiring a separate hold-out set for obtaining test-time coverage guarantees. We leverage these theoretical results to provide a practical algorithm for using calibration data to simultaneously fine-tune the parameters of a model and score function while guaranteeing test-time coverage and efficiency of the resulting prediction sets. We evaluate the approach on regression and classification tasks, and outperform baselines calibrated using a Hoeffding bound-based PAC guarantee on ICP, especially in the low-data regime.
Multi-Predictor Fusion: Combining Learning-based and Rule-based Trajectory Predictors
Jul 03, 2023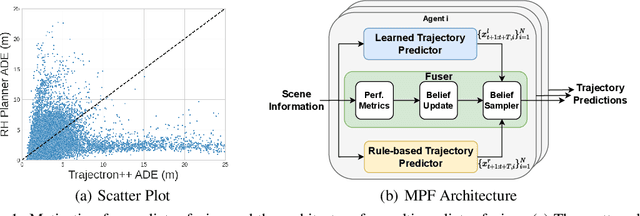
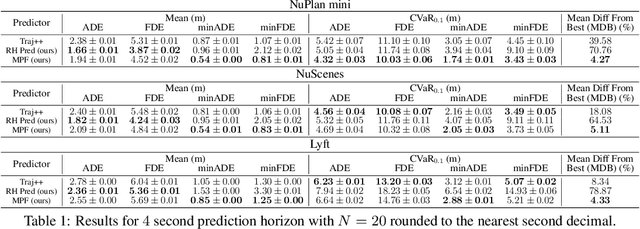
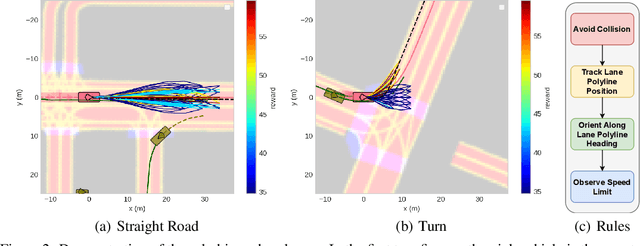

Trajectory prediction modules are key enablers for safe and efficient planning of autonomous vehicles (AVs), particularly in highly interactive traffic scenarios. Recently, learning-based trajectory predictors have experienced considerable success in providing state-of-the-art performance due to their ability to learn multimodal behaviors of other agents from data. In this paper, we present an algorithm called multi-predictor fusion (MPF) that augments the performance of learning-based predictors by imbuing them with motion planners that are tasked with satisfying logic-based rules. MPF probabilistically combines learning- and rule-based predictors by mixing trajectories from both standalone predictors in accordance with a belief distribution that reflects the online performance of each predictor. In our results, we show that MPF outperforms the two standalone predictors on various metrics and delivers the most consistent performance.
A System-Level View on Out-of-Distribution Data in Robotics
Dec 28, 2022When testing conditions differ from those represented in training data, so-called out-of-distribution (OOD) inputs can mar the reliability of black-box learned components in the modern robot autonomy stack. Therefore, coping with OOD data is an important challenge on the path towards trustworthy learning-enabled open-world autonomy. In this paper, we aim to demystify the topic of OOD data and its associated challenges in the context of data-driven robotic systems, drawing connections to emerging paradigms in the ML community that study the effect of OOD data on learned models in isolation. We argue that as roboticists, we should reason about the overall system-level competence of a robot as it performs tasks in OOD conditions. We highlight key research questions around this system-level view of OOD problems to guide future research toward safe and reliable learning-enabled autonomy.